Parameter Estimation
CMSC 173 - Module 01
Noel Jeffrey Pinton
Department of Computer Science
University of the Philippines Cebu
What We'll Cover
Foundations
What is parameter estimation?
Method of Moments
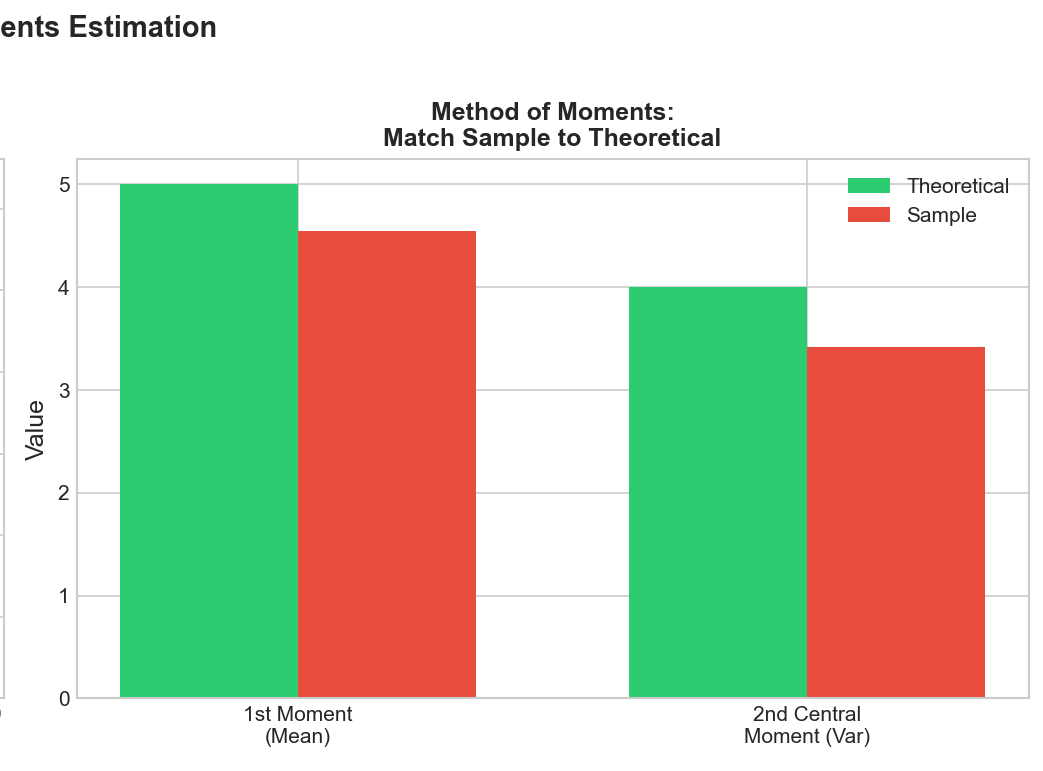
Match sample to theory
Maximum Likelihood
Optimal estimation
Applications
Real-world ML examples
What is Parameter Estimation?
Inferring unknown distribution parameters from observed data samples.
- Data: $\{x_1, x_2, \ldots, x_n\}$
- Distribution: $f(x|\theta)$
- Find: $\hat{\theta}$
Why It Matters in ML
- Supervised: Model weights
- Unsupervised: Cluster parameters
- Time Series: ARIMA coefficients
- Deep Learning: Network weights
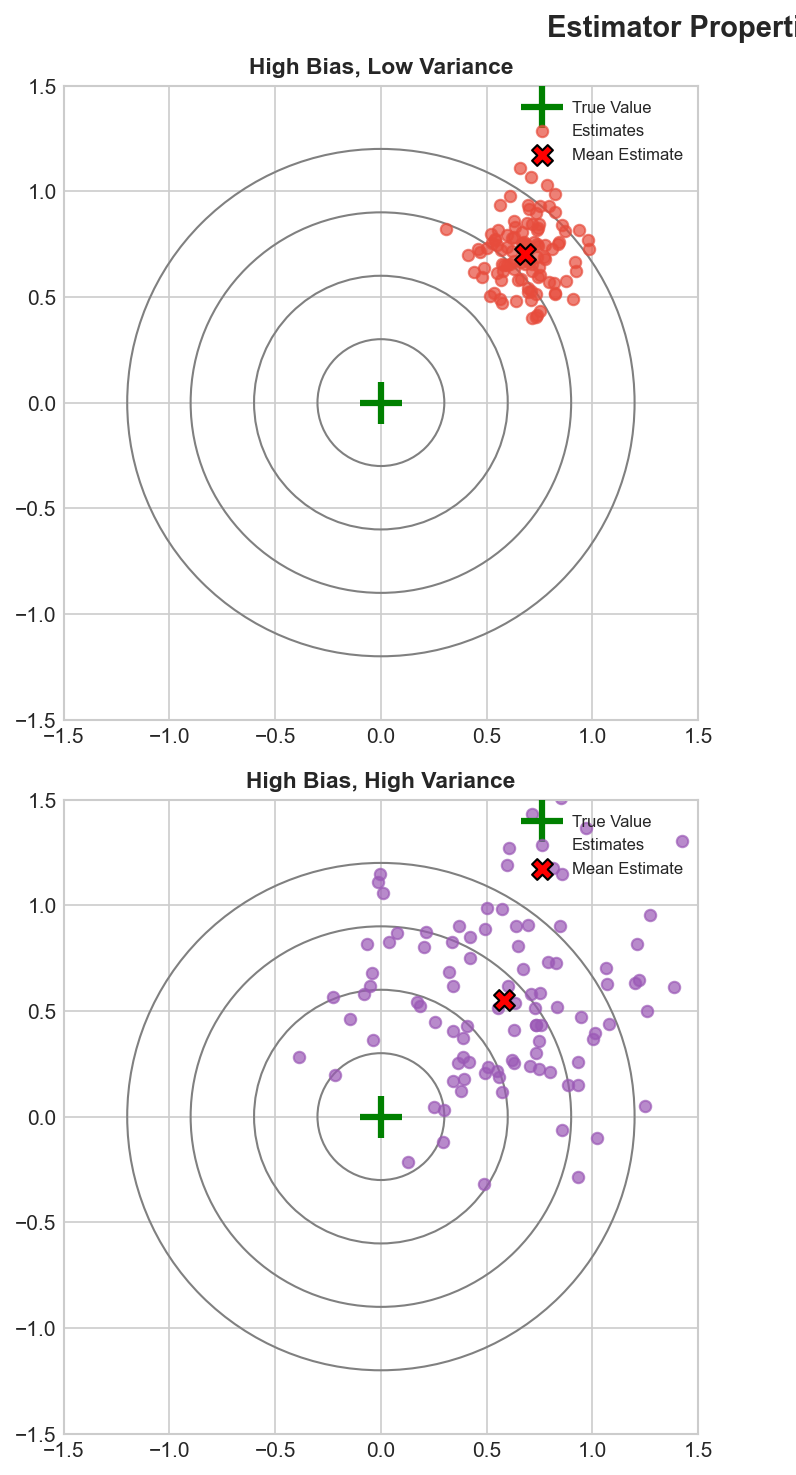
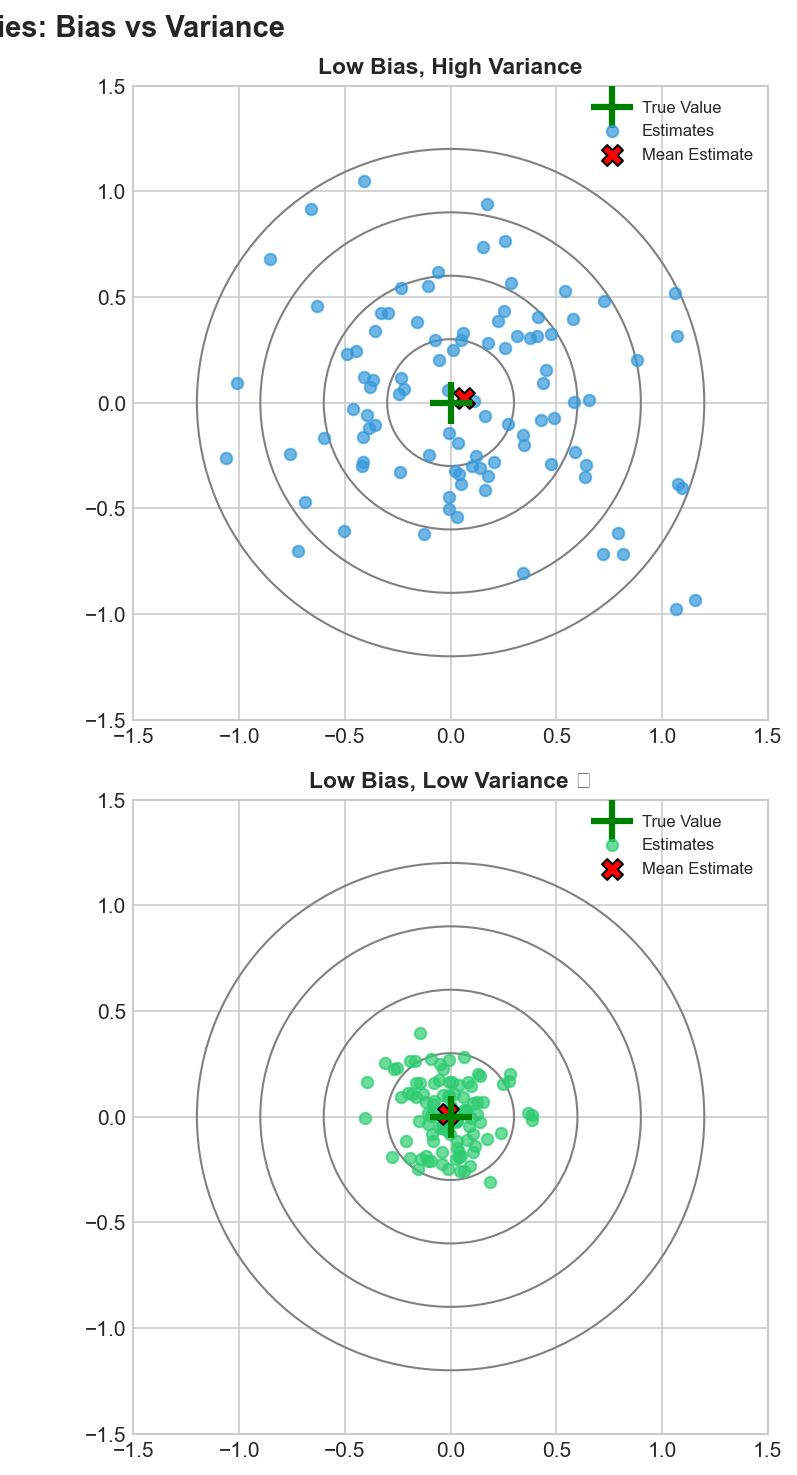
Estimator Quality Criteria
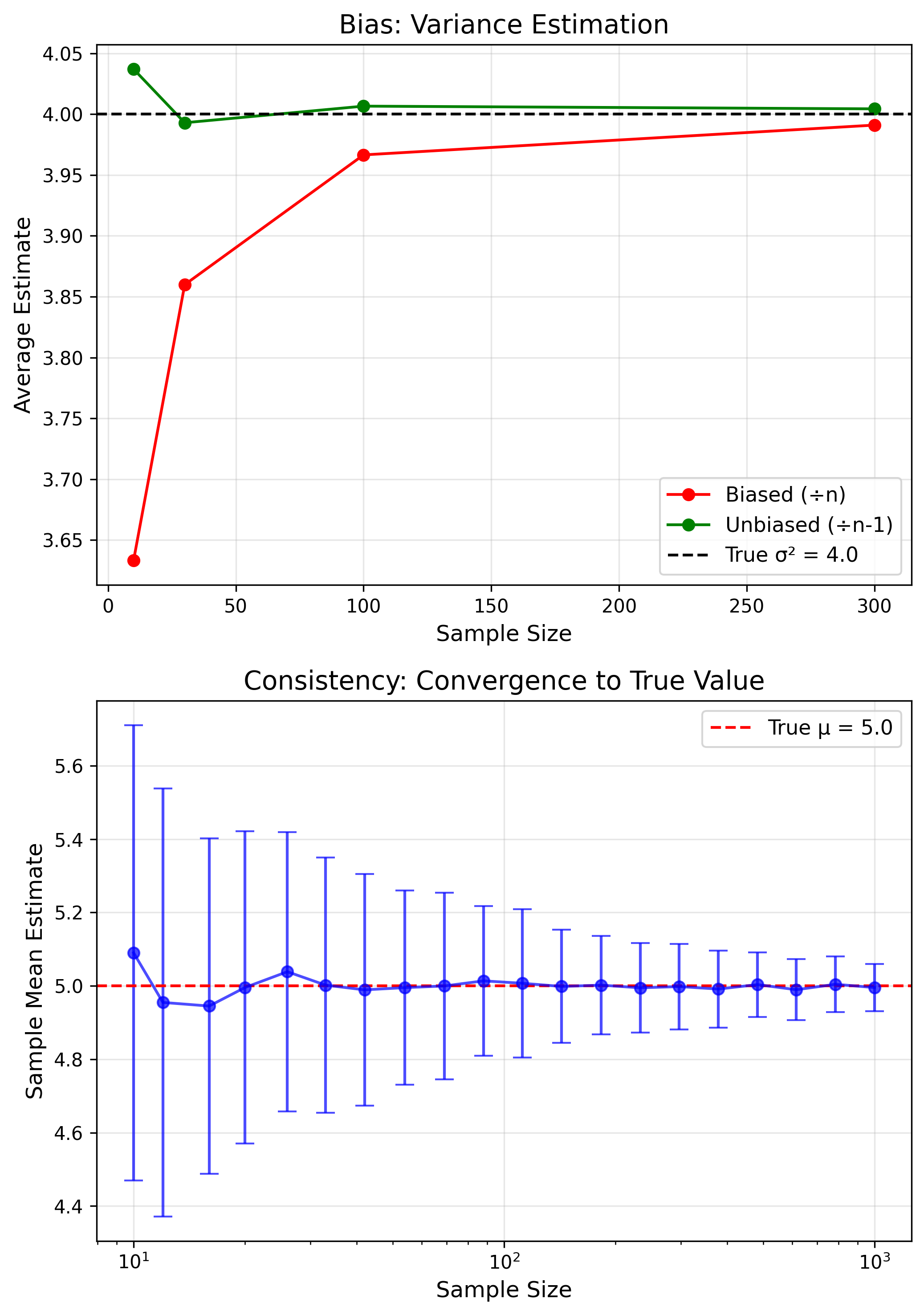
Desirable Properties
- Unbiased: $E[\hat{\theta}] = \theta$
- Consistent: $\hat{\theta} \to \theta$
- Efficient: Min variance
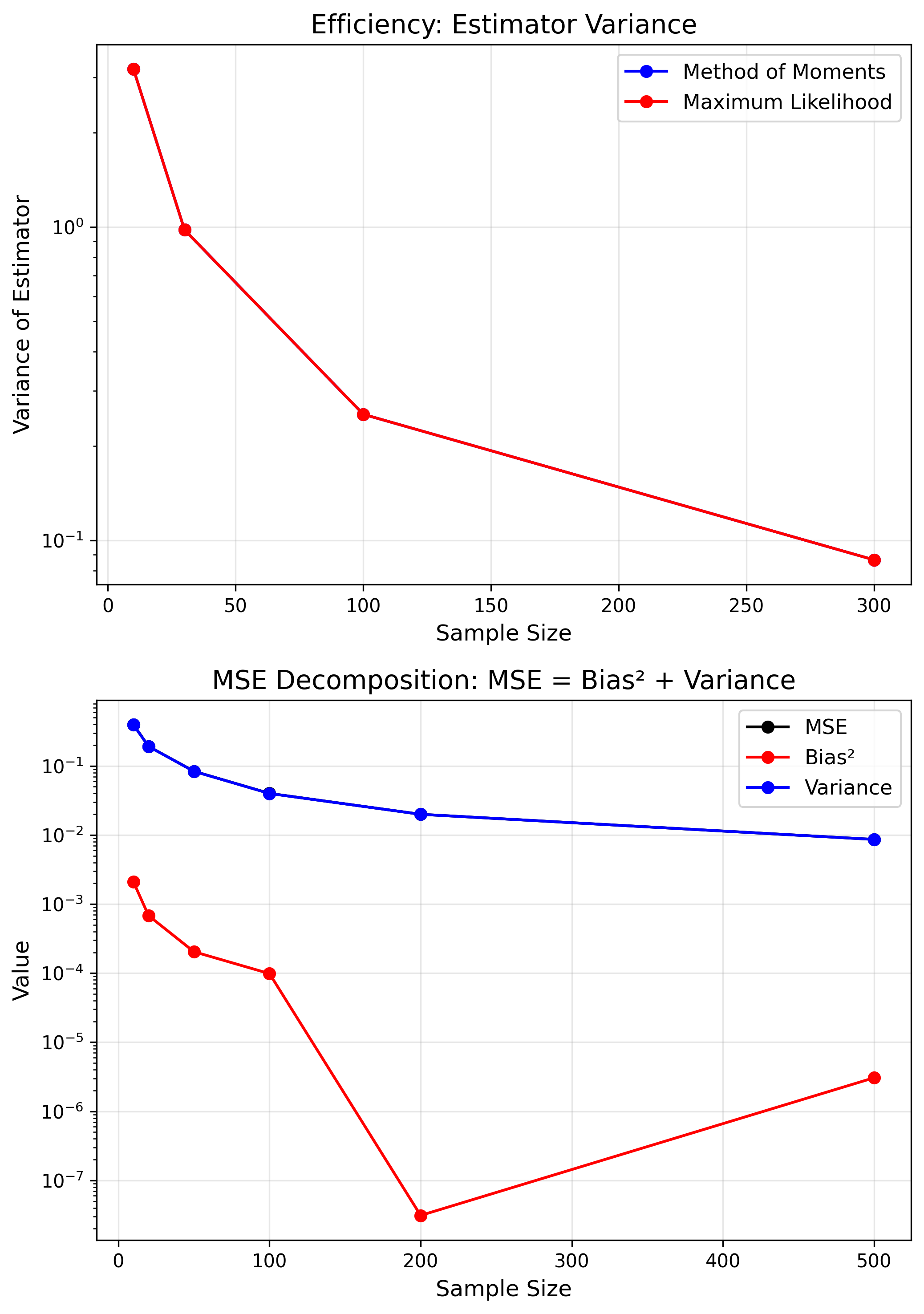
Bias-Variance Tradeoff
Mean Squared Error
$$MSE = Bias^2 + Variance$$Sometimes a little bias can reduce overall error.
Key Notation
Variables
- $X$: Random variable
- $\theta$: True parameter
- $\hat{\theta}$: Estimate
Functions
- $f(x|\theta)$: PDF/PMF
- $L(\theta|x)$: Likelihood
Understanding Moments
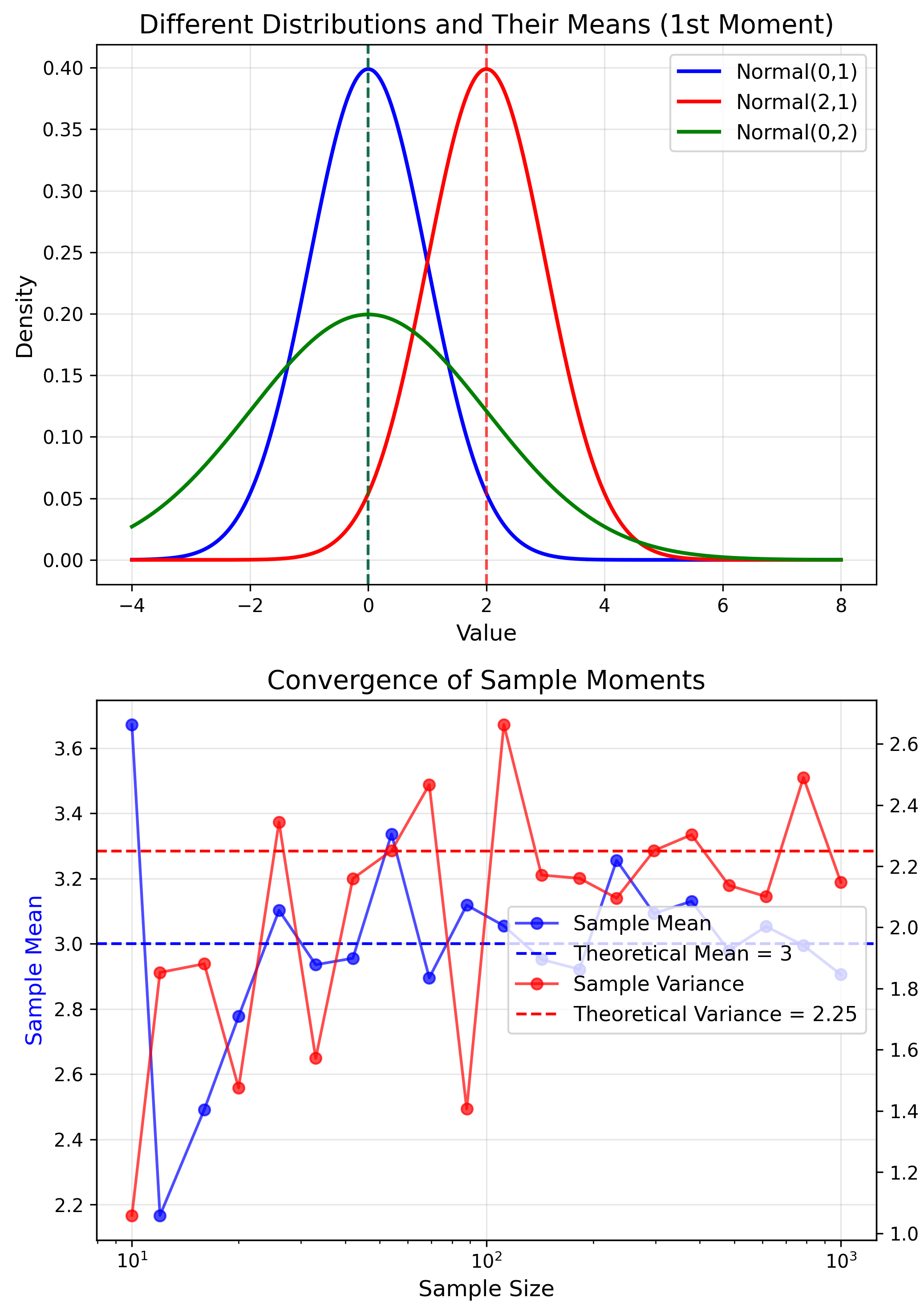
$k$-th Moment
$$m_k = E[X^k]$$- $m_1 = \mu$ (mean)
- $\mu_2 = \sigma^2$ (variance)
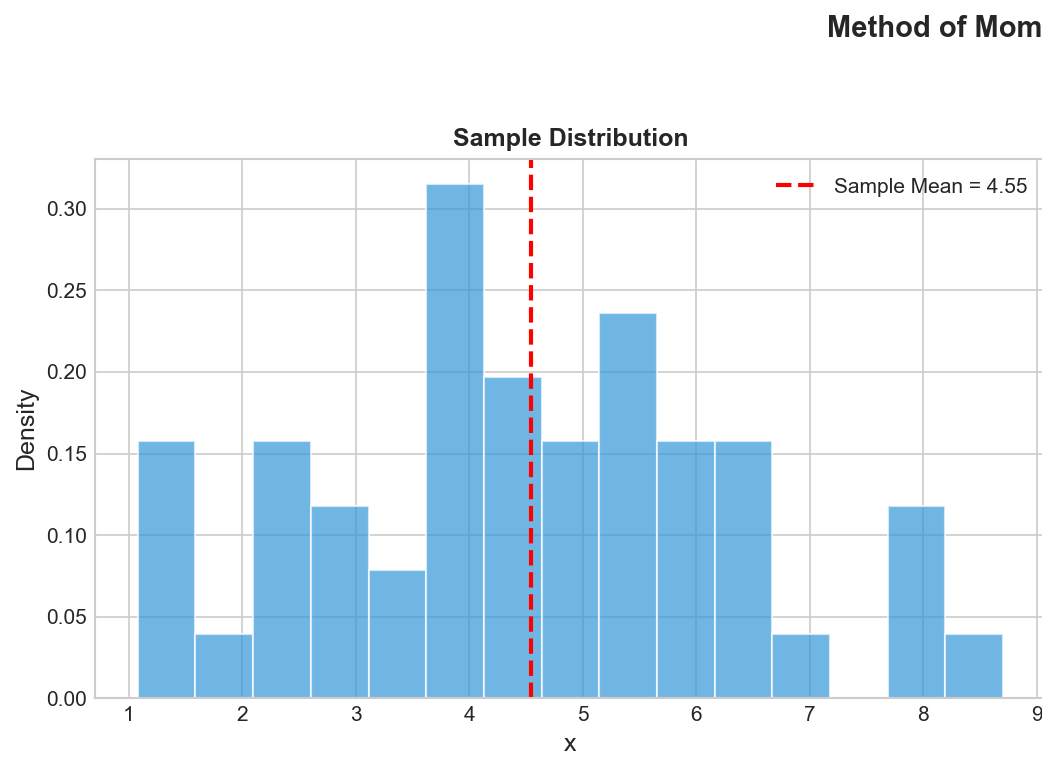
Method of Moments: Core Idea
Match sample moments to theoretical moments to estimate parameters.
Theory
$m_k(\theta)$
Sample
$\hat{m}_k = \frac{1}{n}\sum x_i^k$
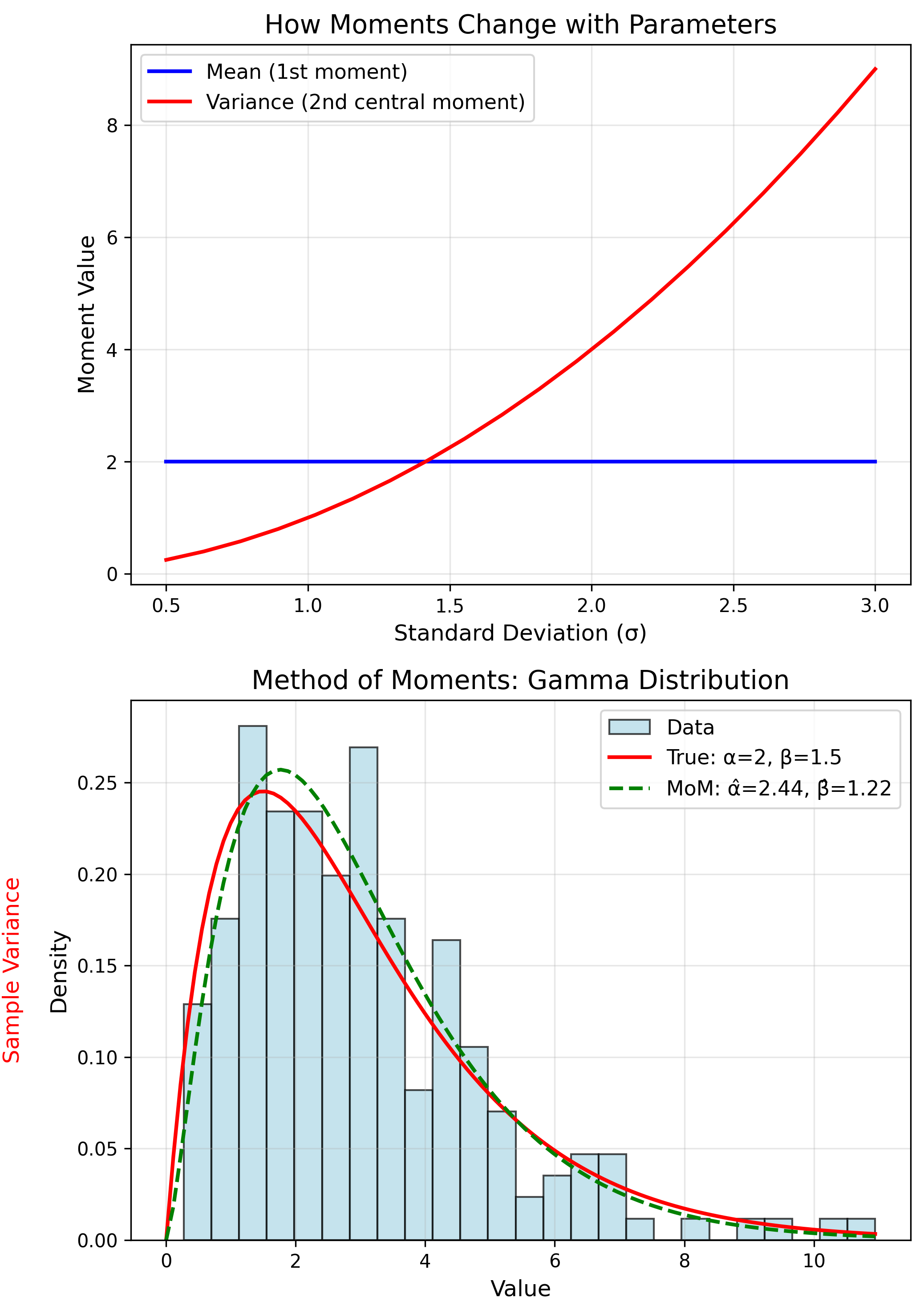
MoM Algorithm
- Express moments: $m_k(\theta)$
- Calculate sample: $\hat{m}_k$
- Set equal: $m_k(\theta) = \hat{m}_k$
- Solve for $\hat{\theta}$
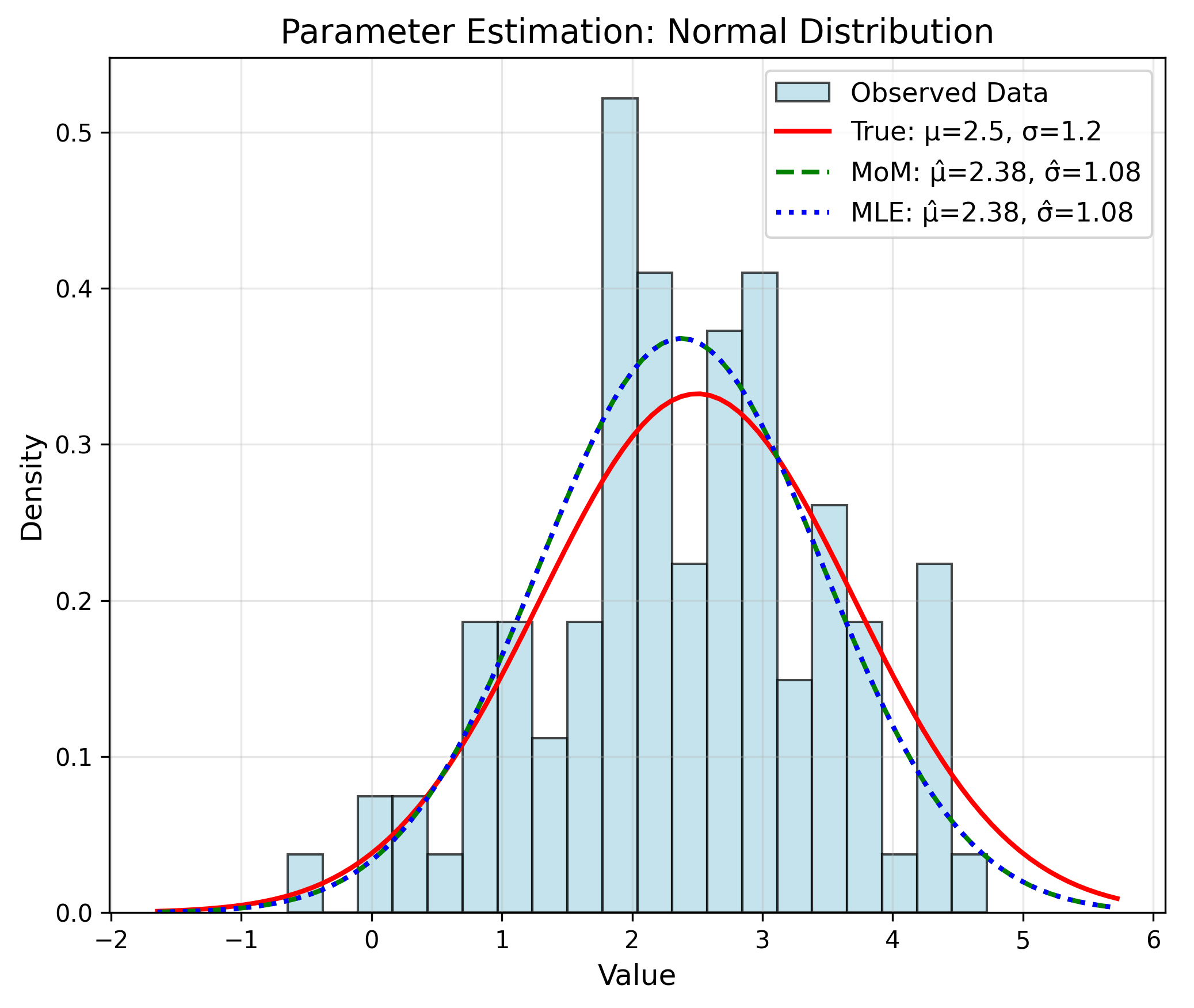
MoM: Normal Distribution
Estimate $\mu$ and $\sigma^2$ for $N(\mu, \sigma^2)$
Theory
$m_1 = \mu$
$m_2 = \mu^2 + \sigma^2$
MoM Estimates
$\hat{\mu} = \bar{x}$
$\hat{\sigma}^2 = \frac{1}{n}\sum(x_i - \bar{x})^2$
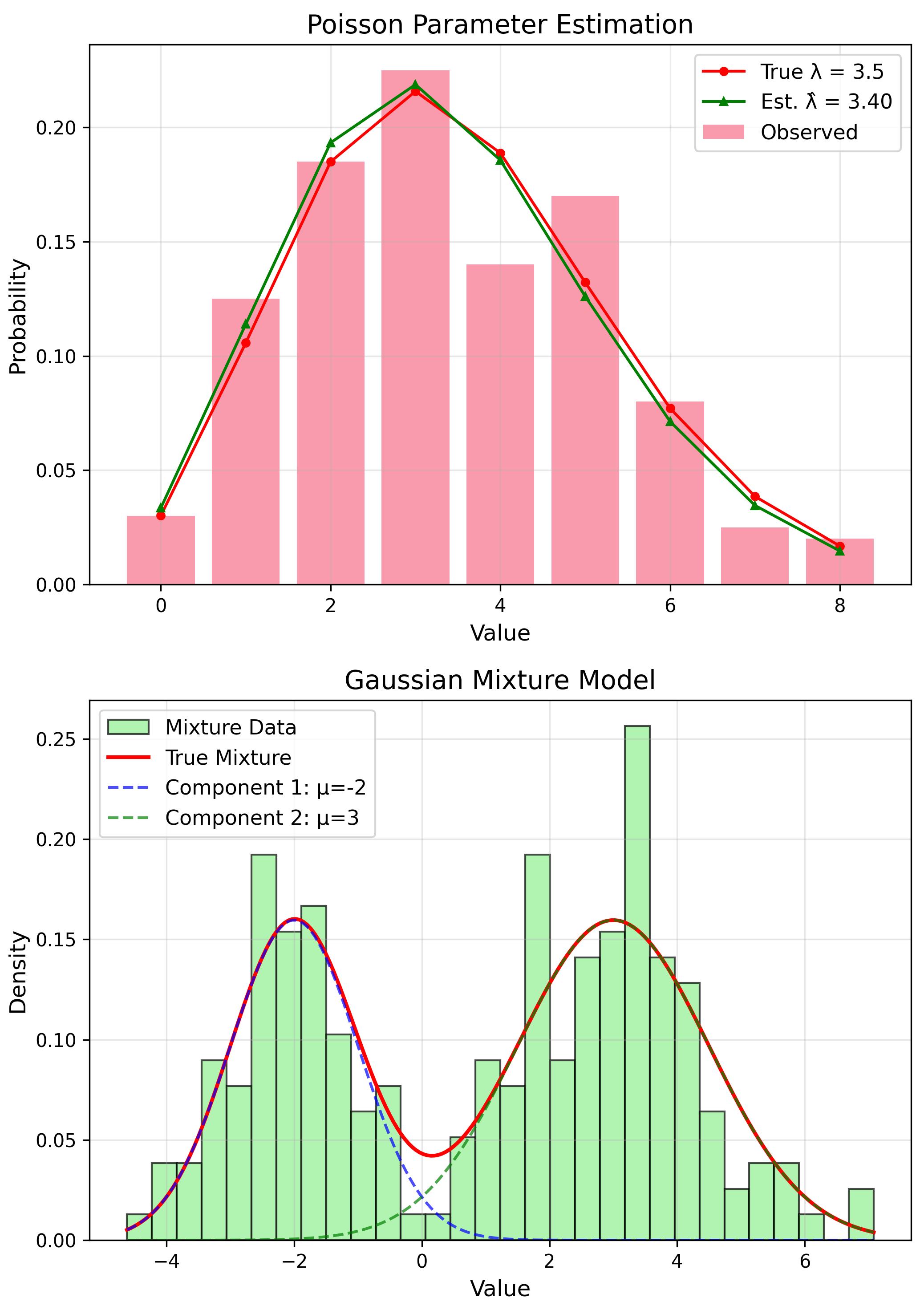
MoM: Poisson Distribution
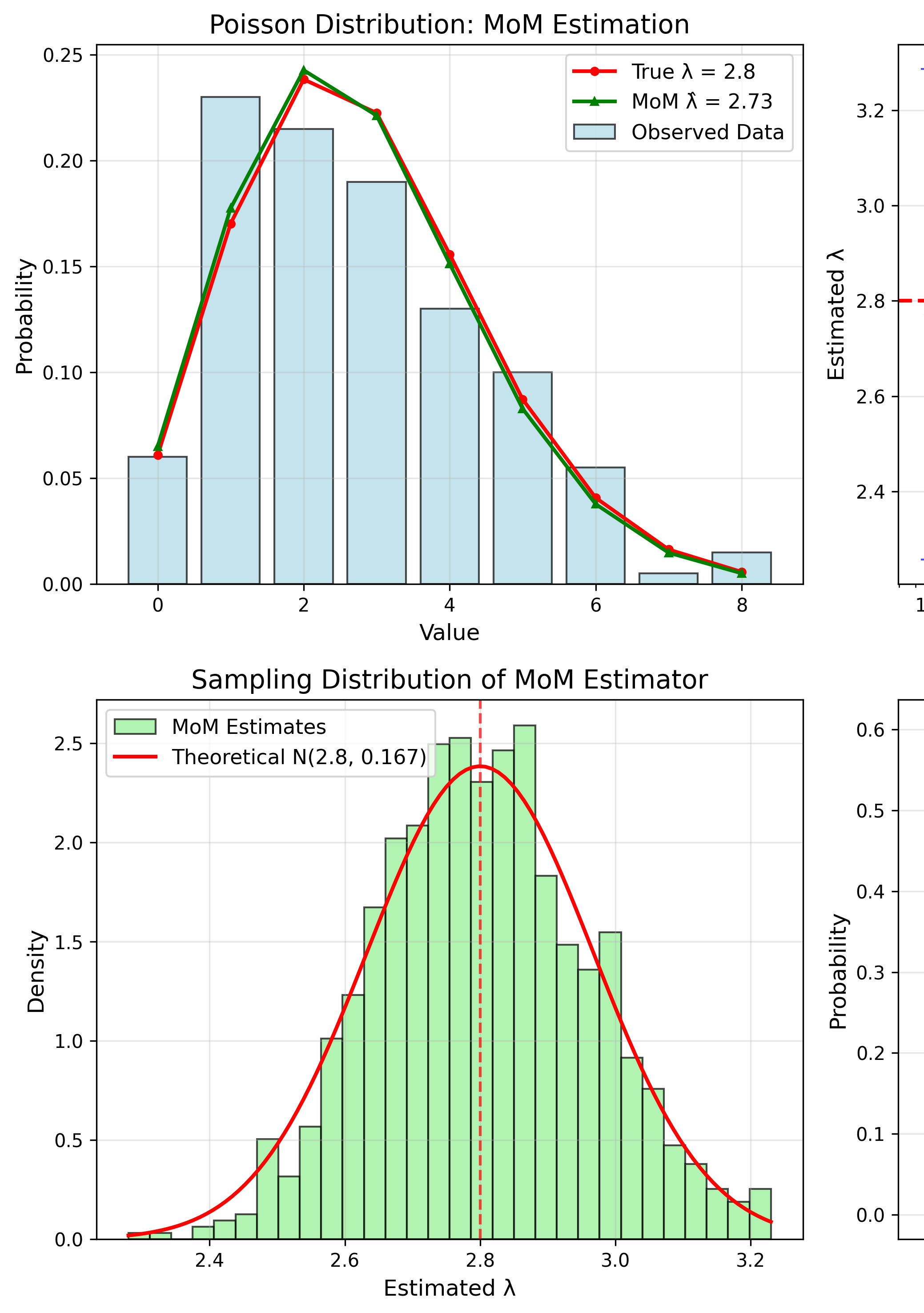
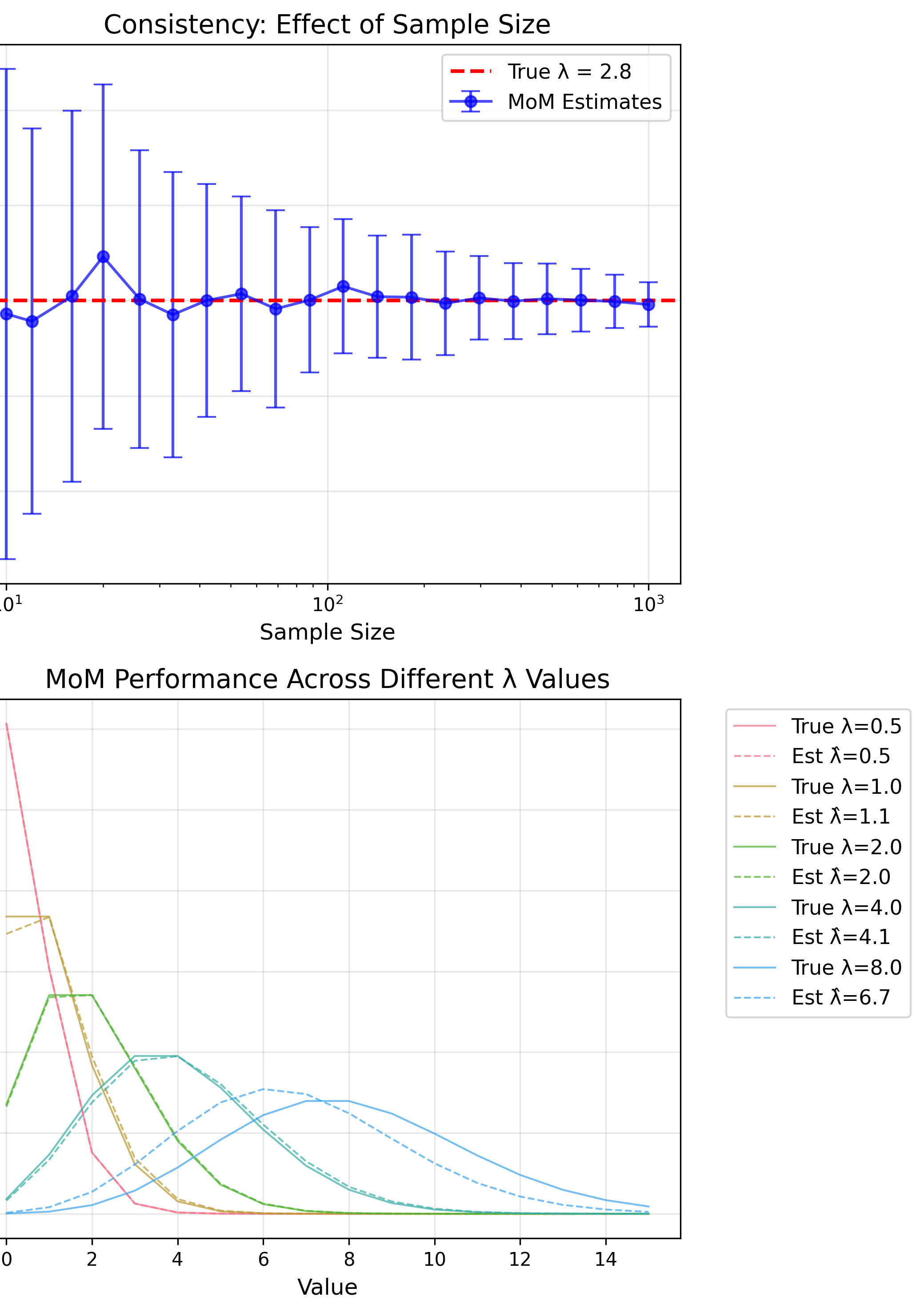
Theory: $E[X] = \lambda$
MoM Estimate
$$\hat{\lambda} = \bar{x}$$MoM: Gamma Distribution
$E[X] = \alpha\beta$, $Var(X) = \alpha\beta^2$
MoM Estimates
$$\hat{\beta} = \frac{\hat{\sigma}^2}{\bar{x}}, \quad \hat{\alpha} = \frac{\bar{x}^2}{\hat{\sigma}^2}$$MoM Properties
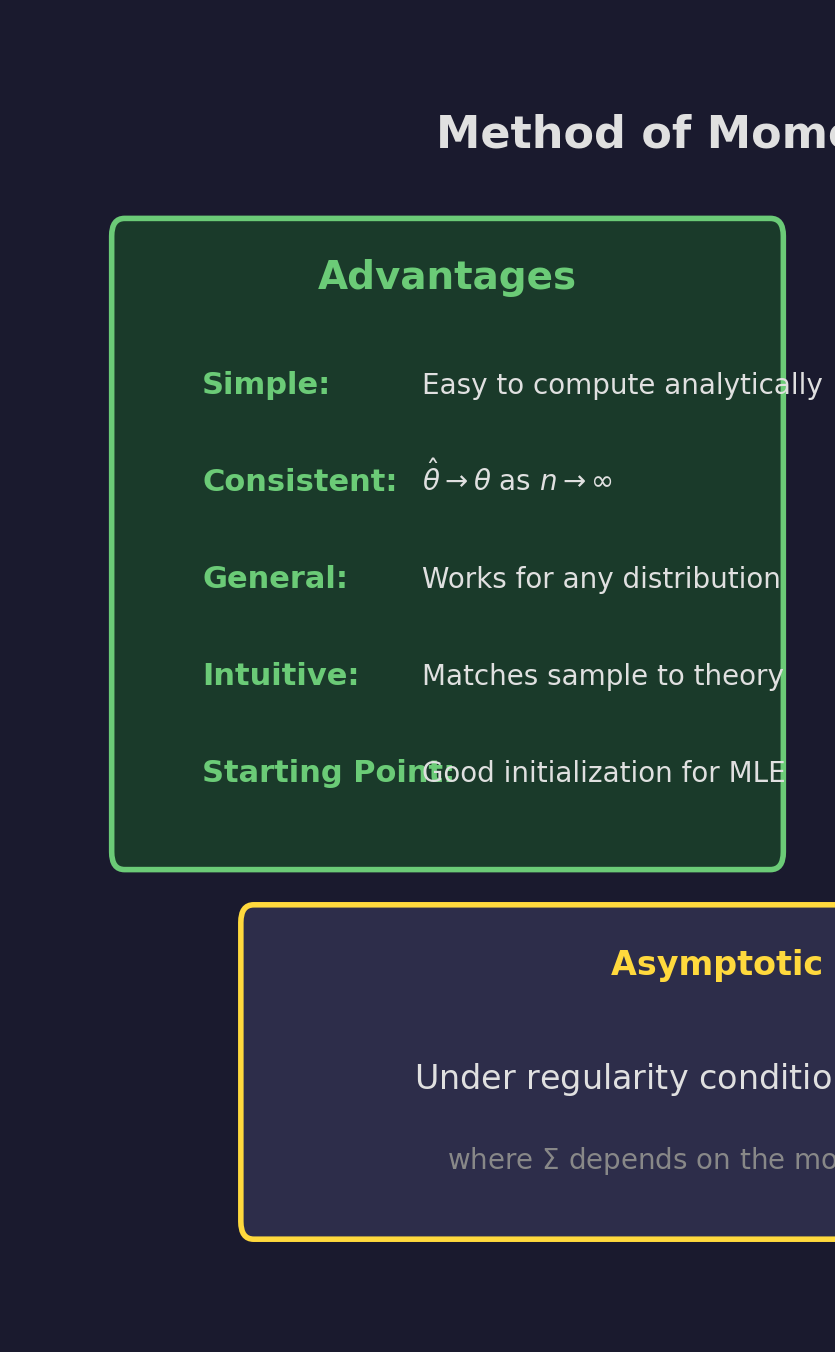

Simple, consistent, general
Not optimal, may give invalid estimates
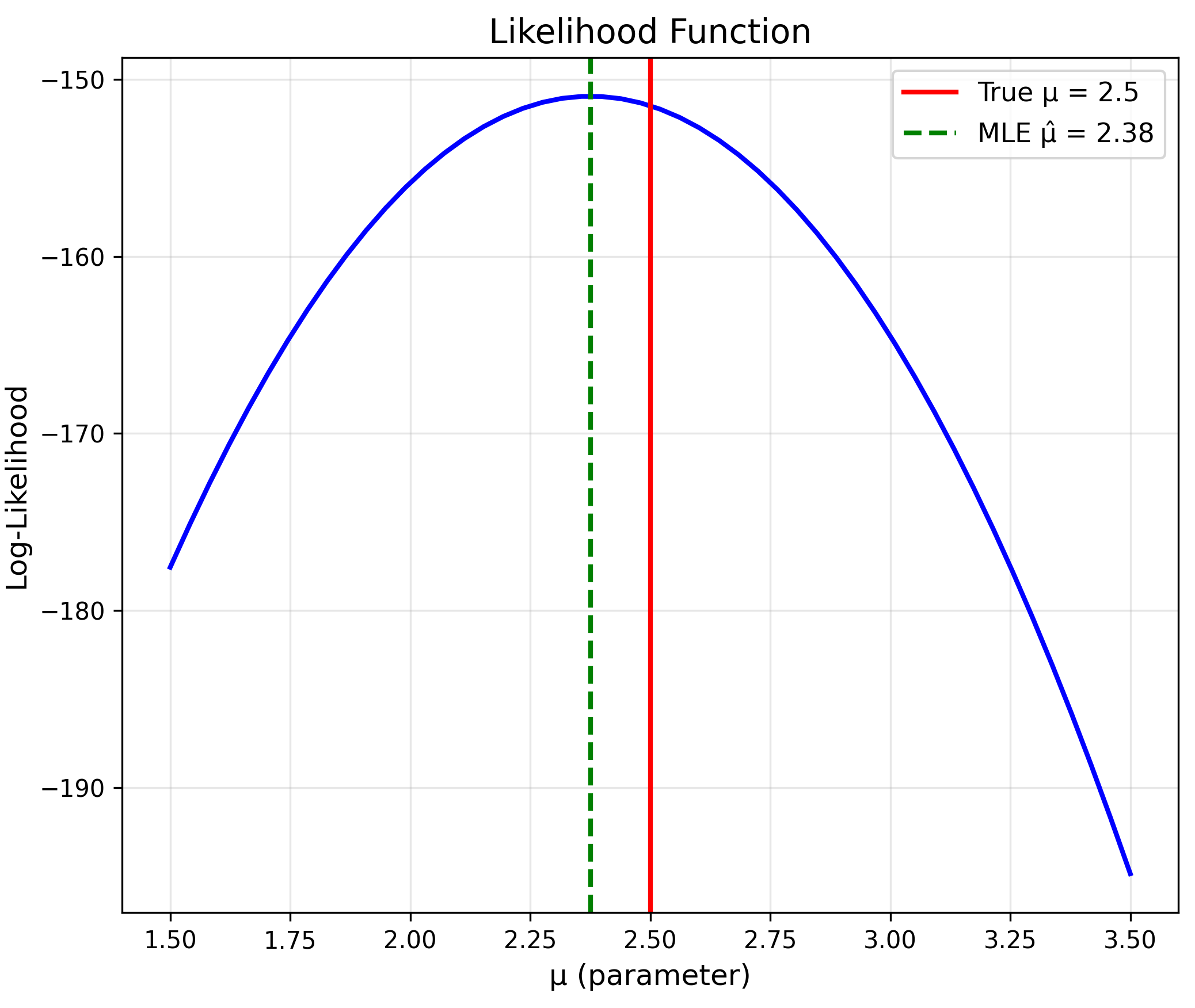
Maximum Likelihood: Core Idea
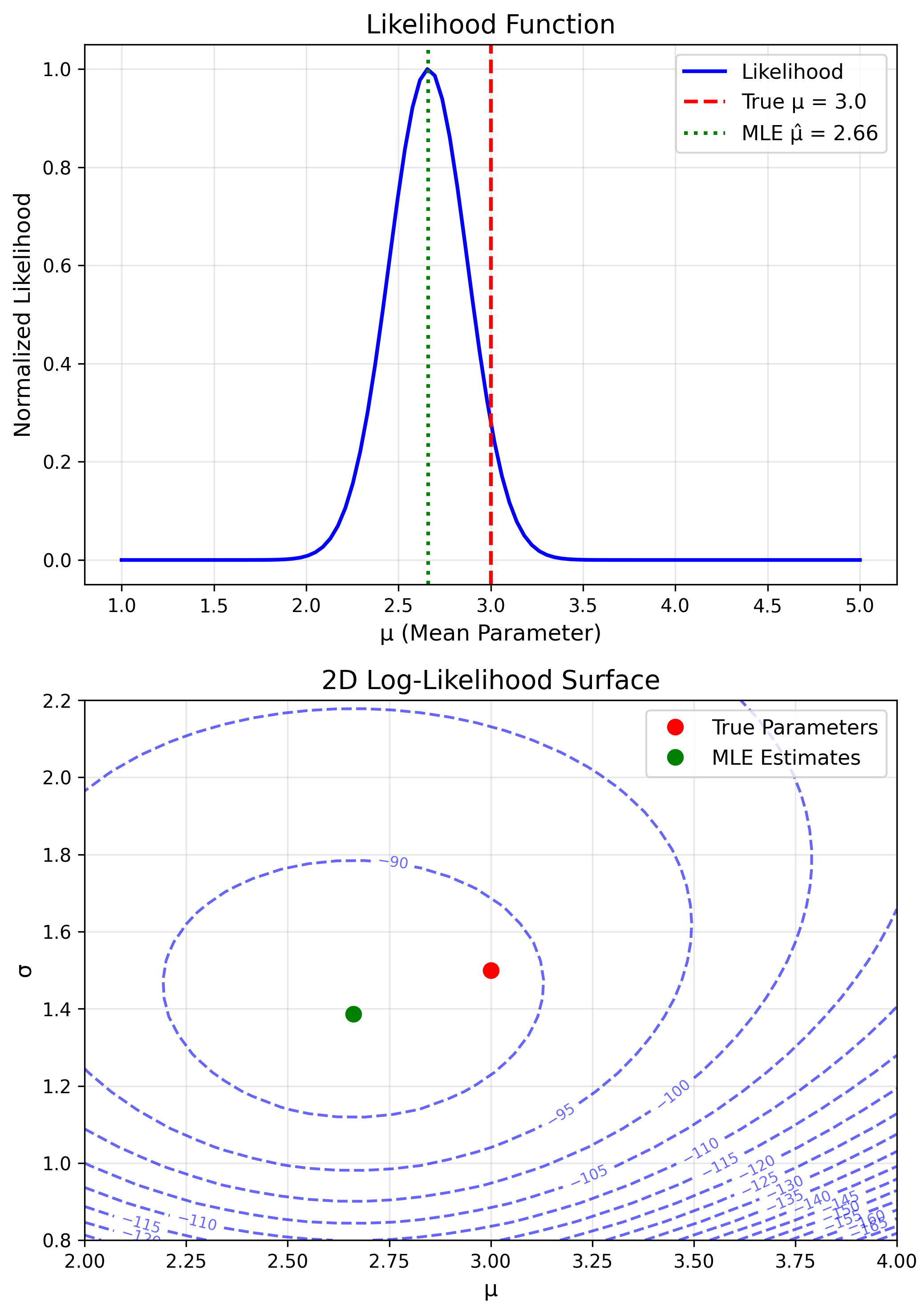
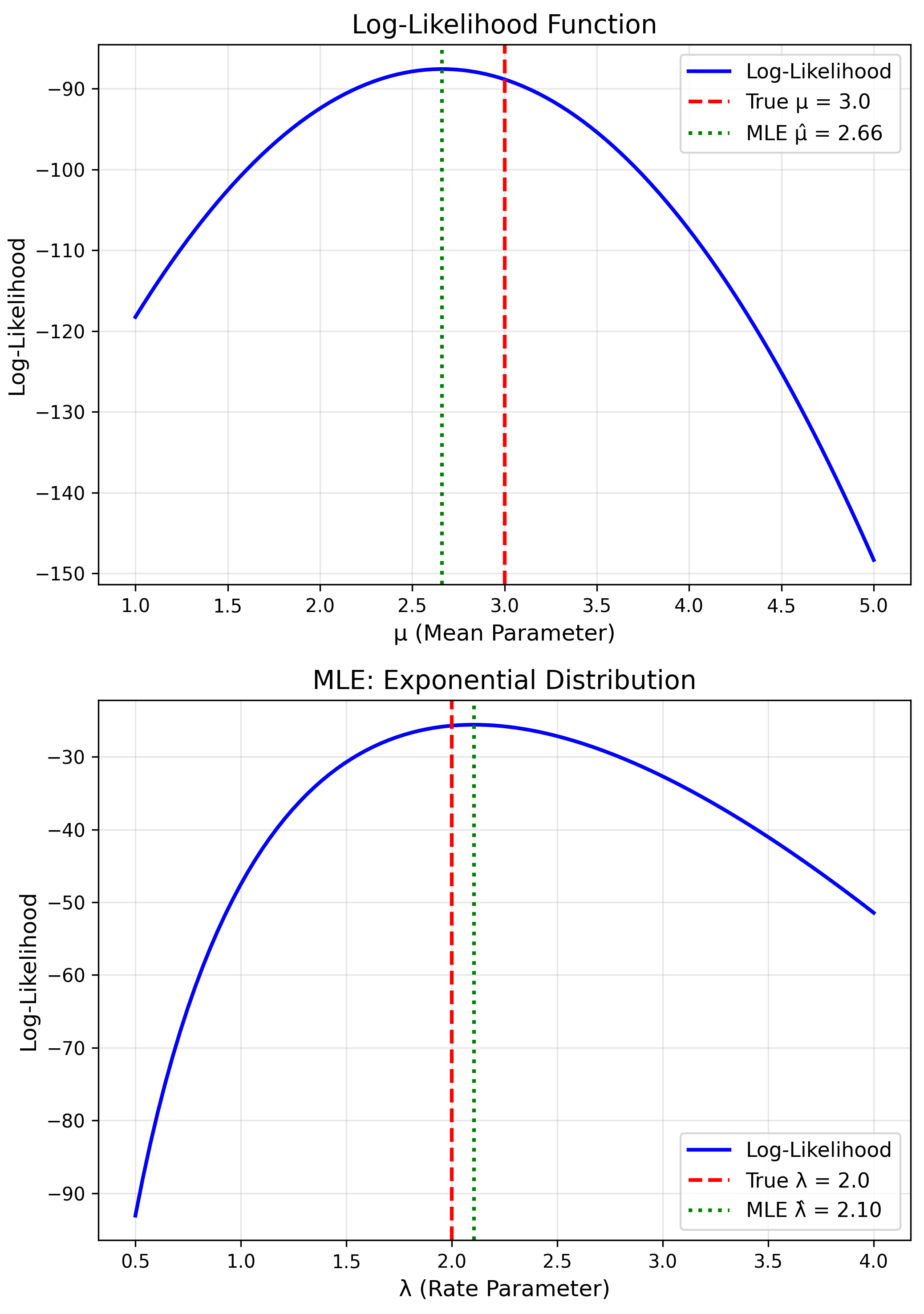
Find parameters that make observed data most likely.
The Likelihood Function
Likelihood
$$L(\theta) = \prod_{i=1}^n f(x_i | \theta)$$Log-Likelihood
$$\ell(\theta) = \sum_{i=1}^n \log f(x_i | \theta)$$Finding the MLE
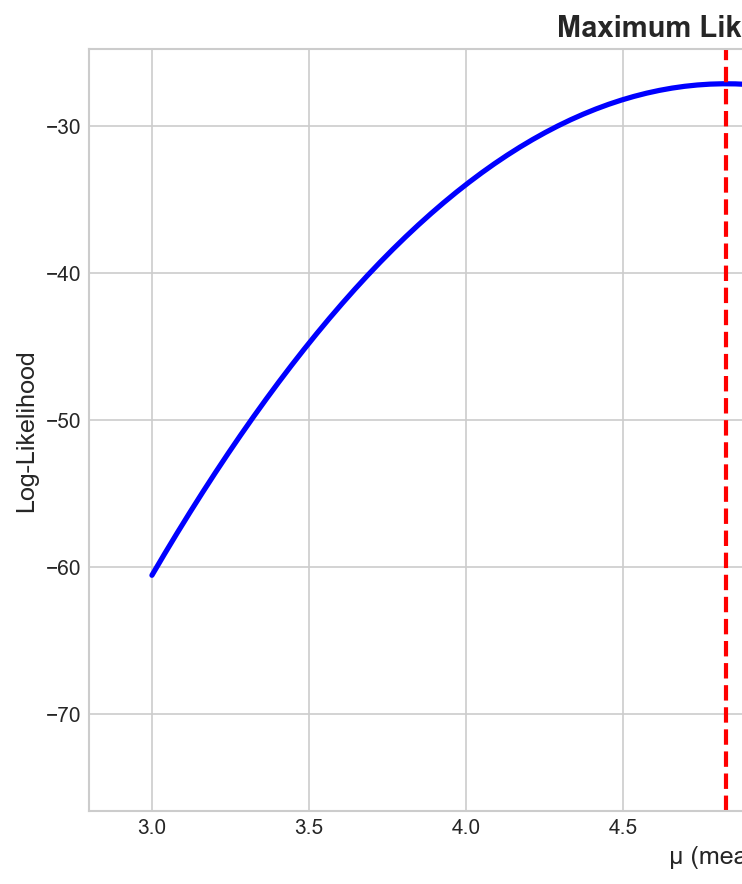
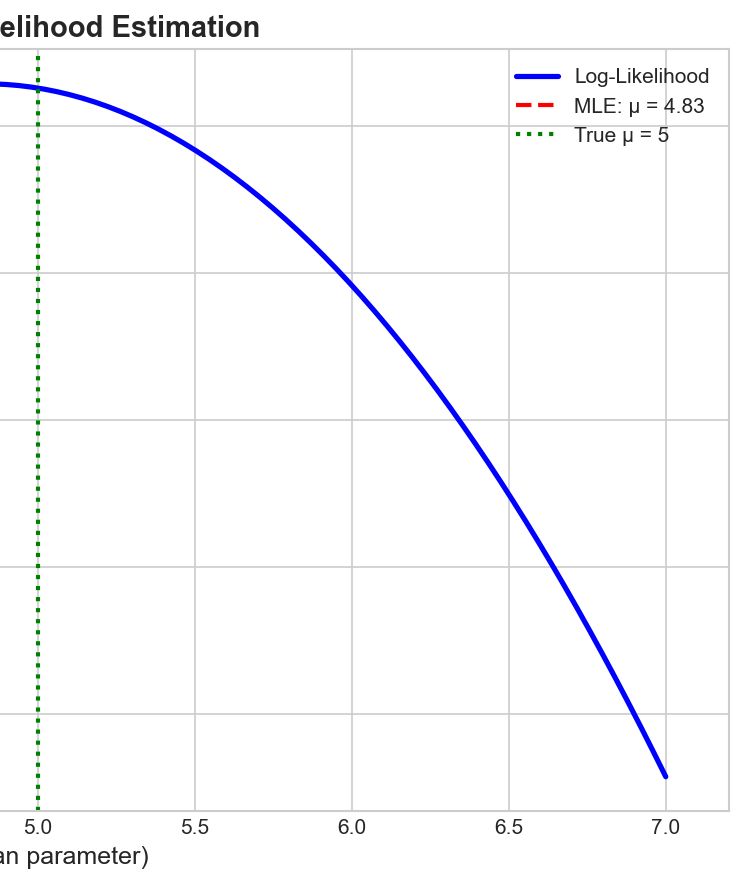
MLE
$$\hat{\theta}_{MLE} = \arg\max_\theta \ell(\theta)$$Method: Solve $\frac{d\ell}{d\theta} = 0$
MLE: Normal Distribution
Estimate $\mu$ and $\sigma^2$ for $N(\mu, \sigma^2)$
MLE Solutions
$$\hat{\mu}_{MLE} = \bar{x}$$ $$\hat{\sigma}^2_{MLE} = \frac{1}{n}\sum_{i=1}^n(x_i - \bar{x})^2$$MLE: Poisson Distribution
Log-likelihood
$\ell(\lambda) = (\sum x_i)\log\lambda - n\lambda$
Score
$\frac{d\ell}{d\lambda} = \frac{\sum x_i}{\lambda} - n = 0$
MLE
$$\hat{\lambda} = \bar{x}$$Same as MoM for Poisson!
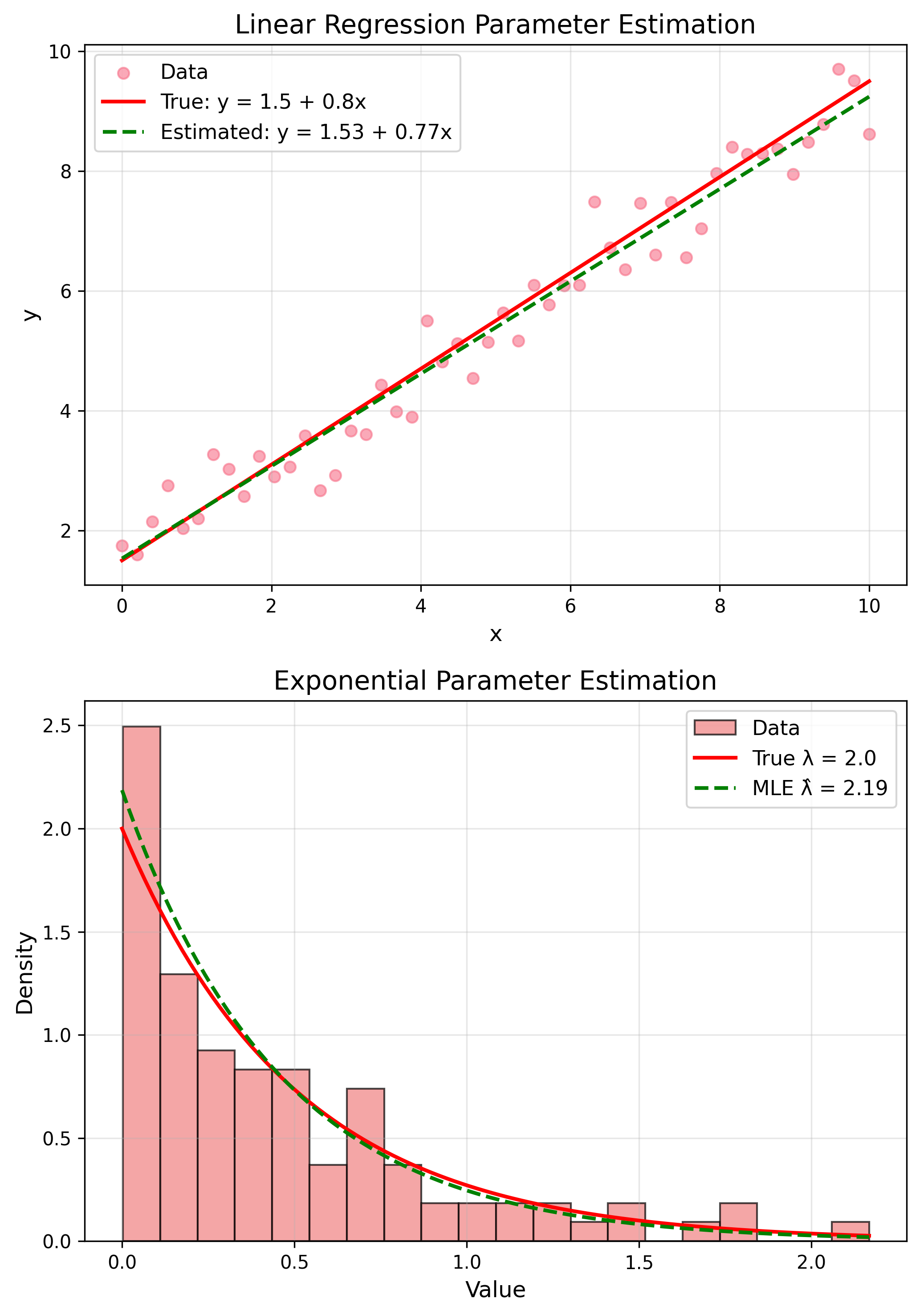
MLE: Exponential Distribution
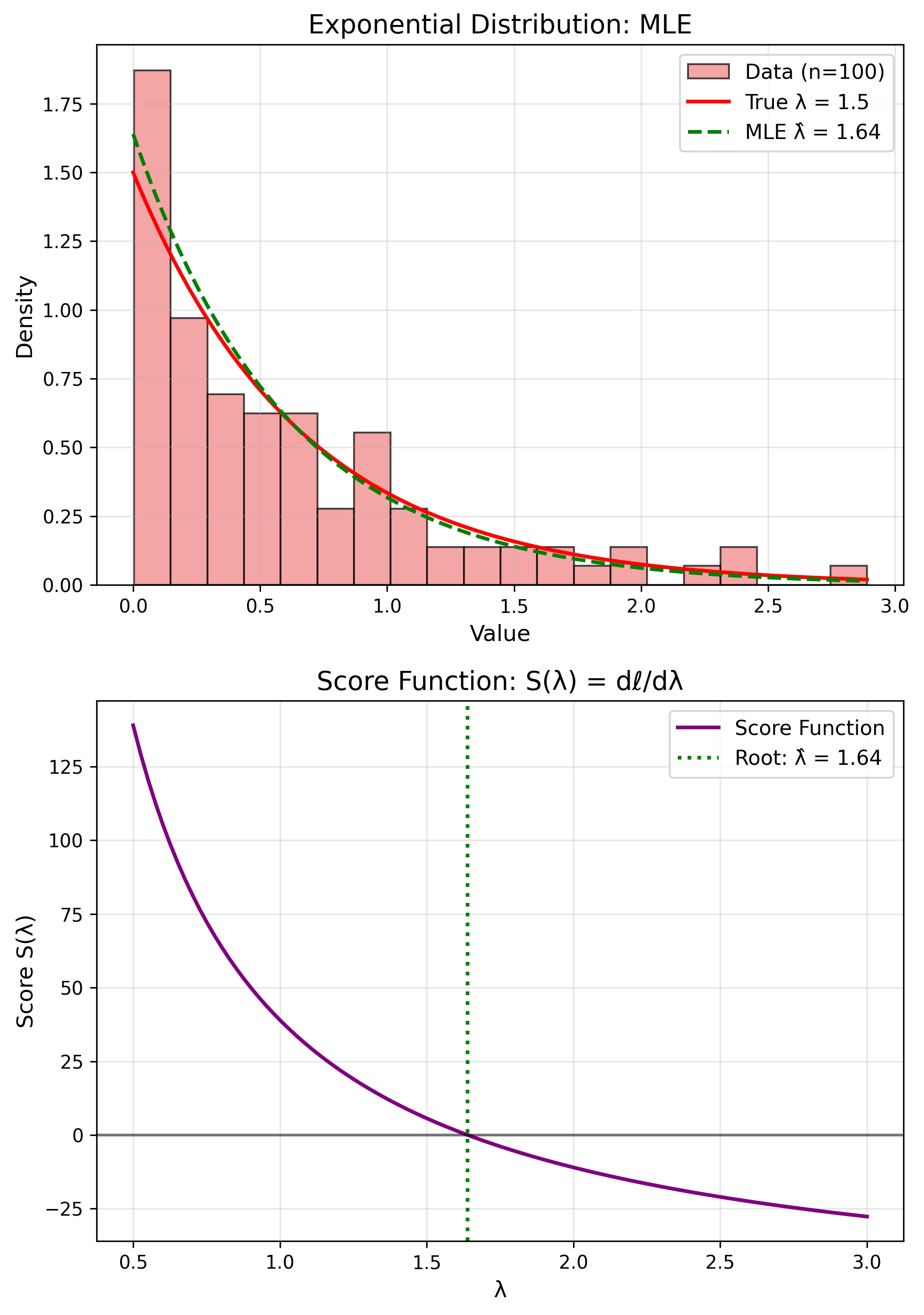
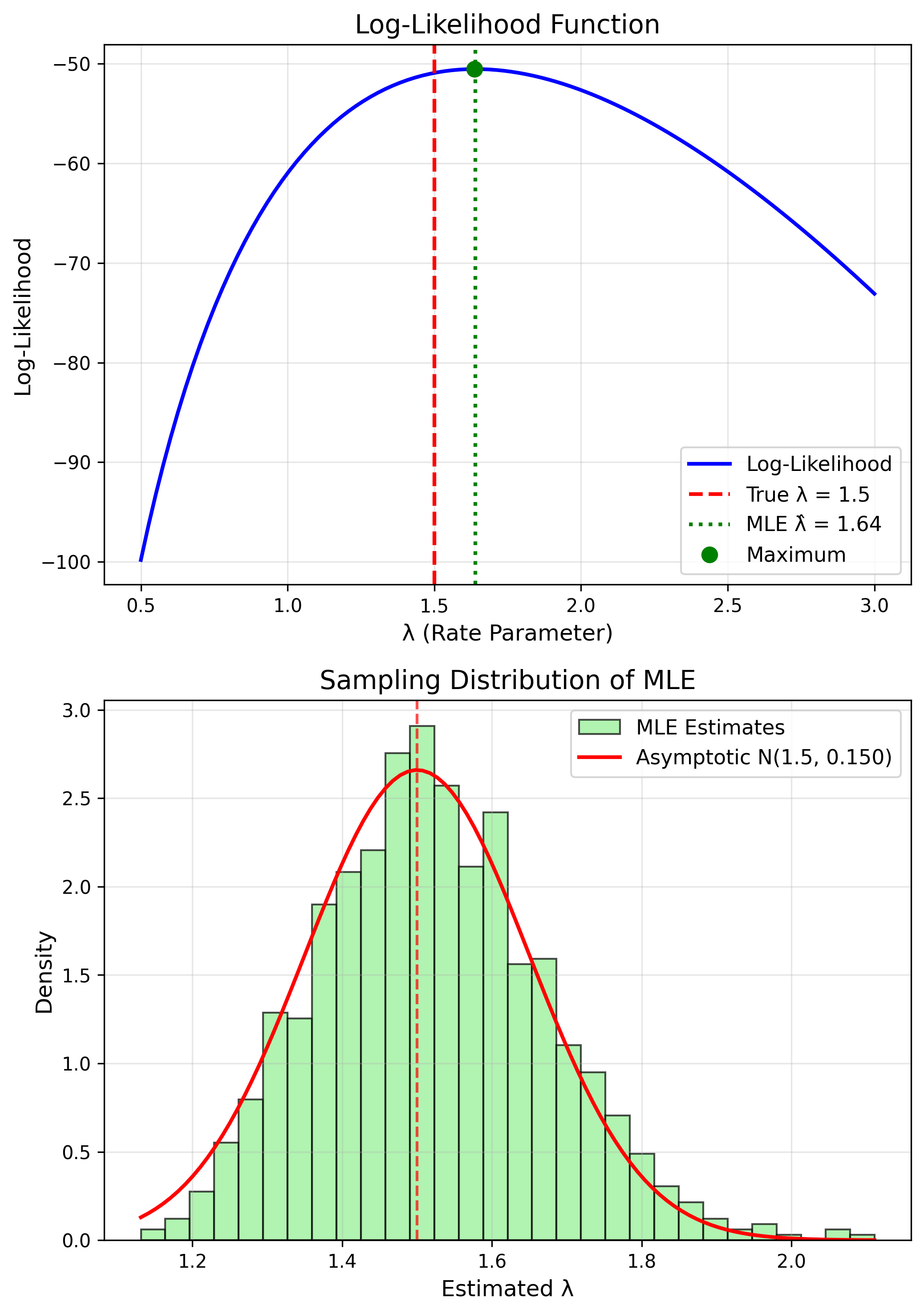
$f(x) = \lambda e^{-\lambda x}$
MLE
$$\hat{\lambda} = \frac{1}{\bar{x}}$$MLE Properties
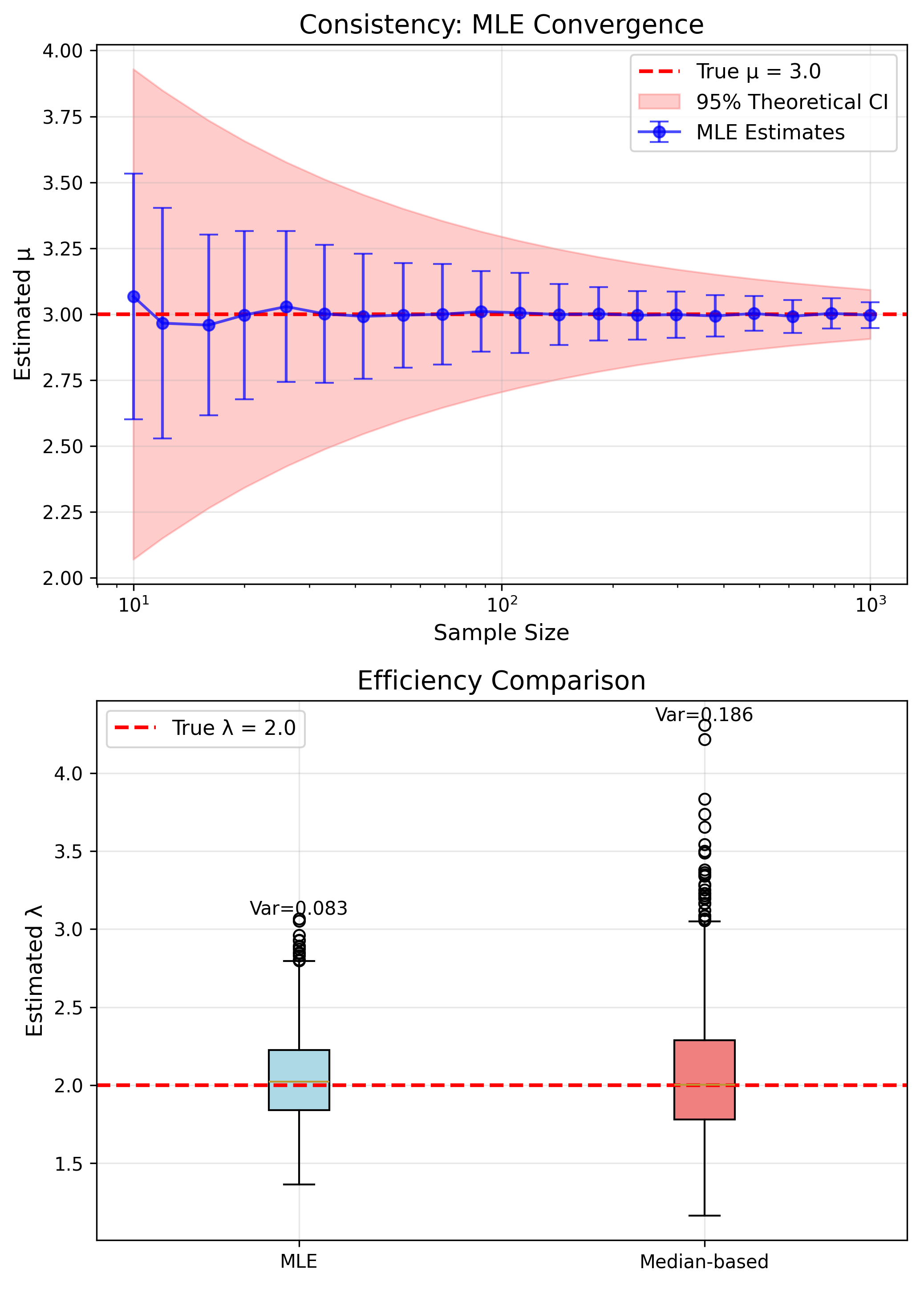
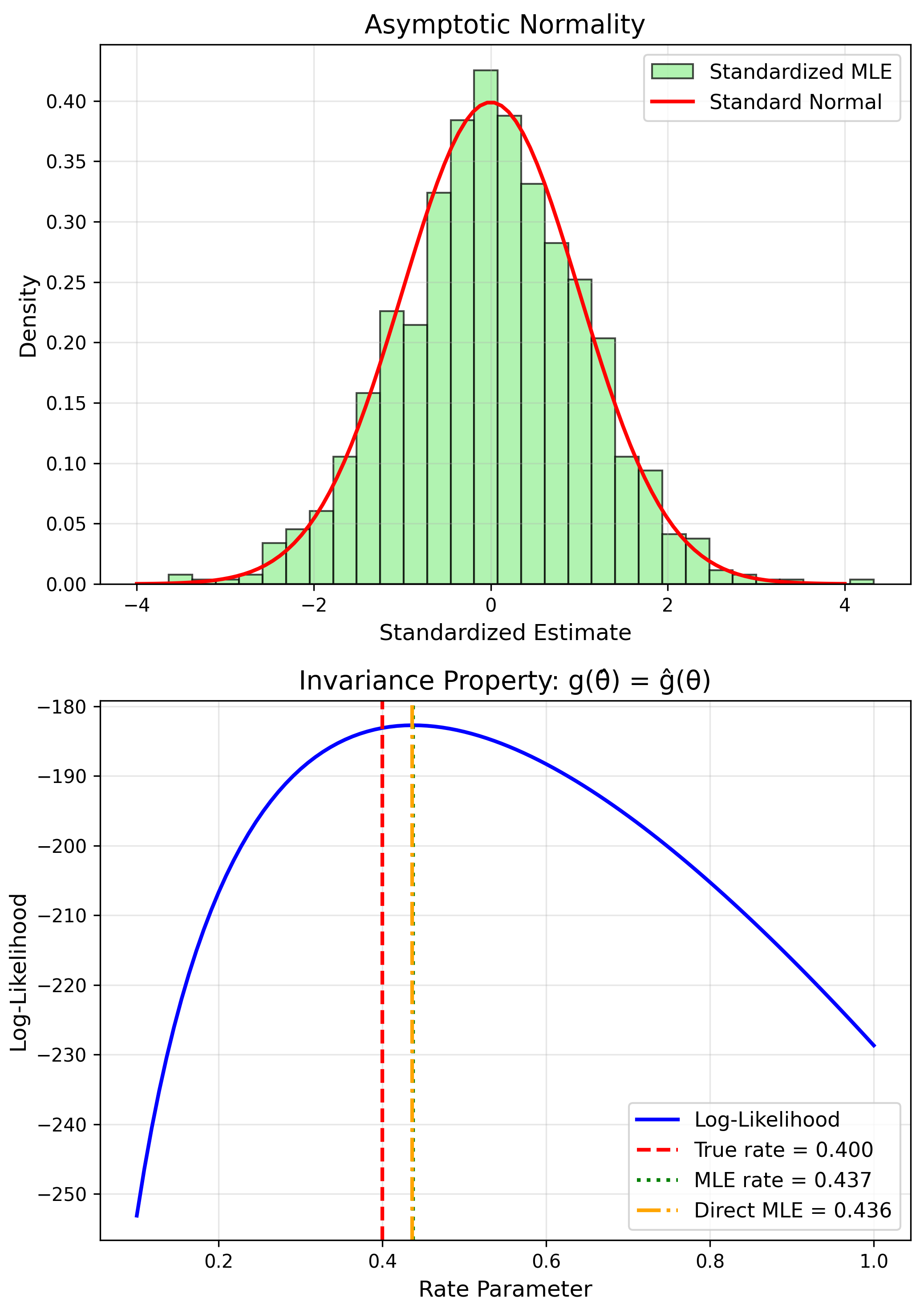
- Consistent: $\hat{\theta} \to \theta$
- Asymptotically Normal
- Efficient: Min variance
- Invariant: $g(\hat{\theta})$ is MLE of $g(\theta)$
Fisher Information
Fisher Information
$$I(\theta) = -E\left[\frac{d^2\ell}{d\theta^2}\right]$$Cramér-Rao Bound
$Var(\hat{\theta}) \geq \frac{1}{I(\theta)}$
Higher information = lower variance
Numerical MLE Methods
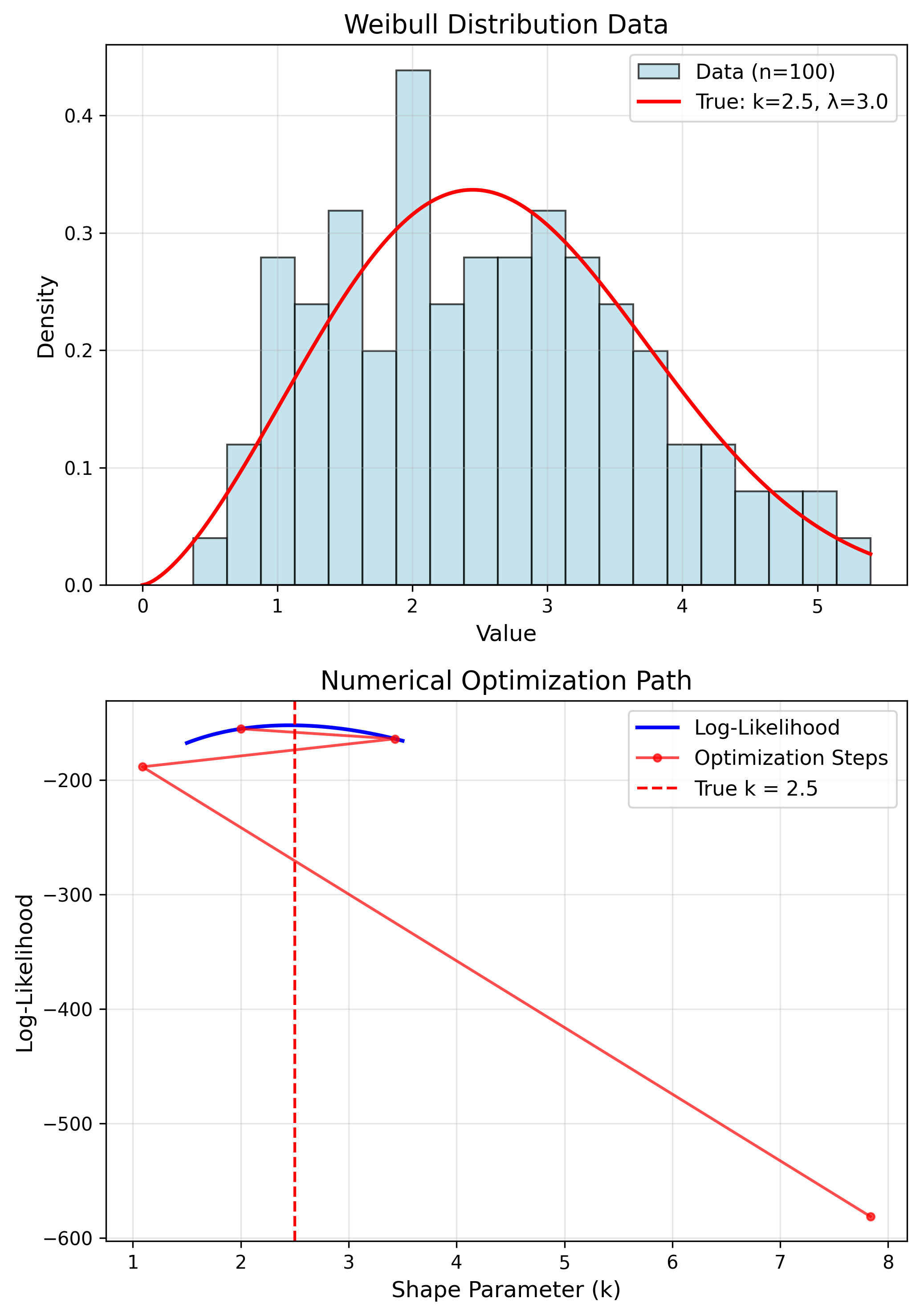
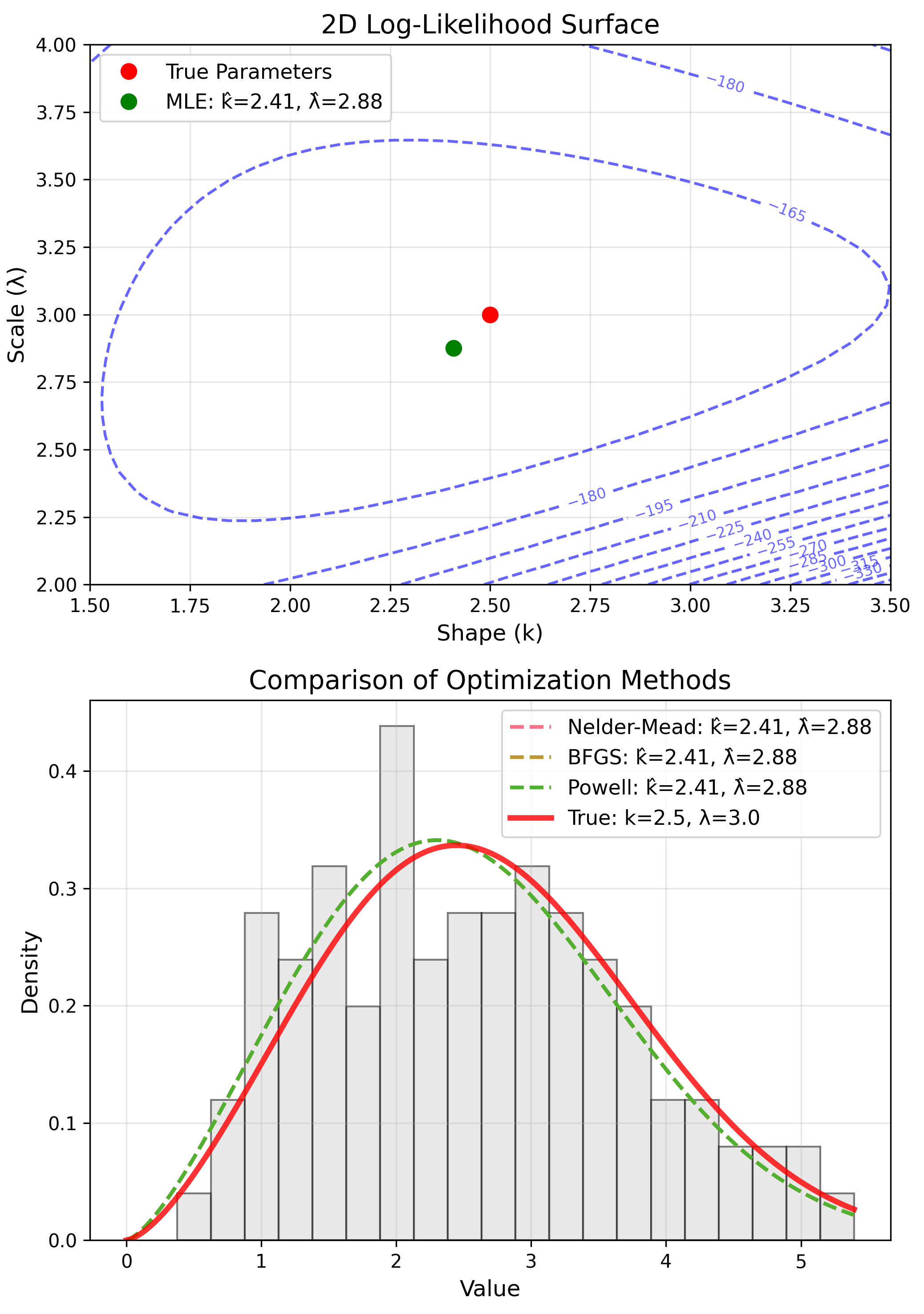
No closed-form solution
- Newton-Raphson
- Gradient ascent
- EM algorithm
MoM vs MLE: Comparison


| MoM | MLE | |
|---|---|---|
| Speed | Fast | Varies |
| Efficiency | Lower | Optimal |
| Complexity | Simple | Complex |
Efficiency Comparison
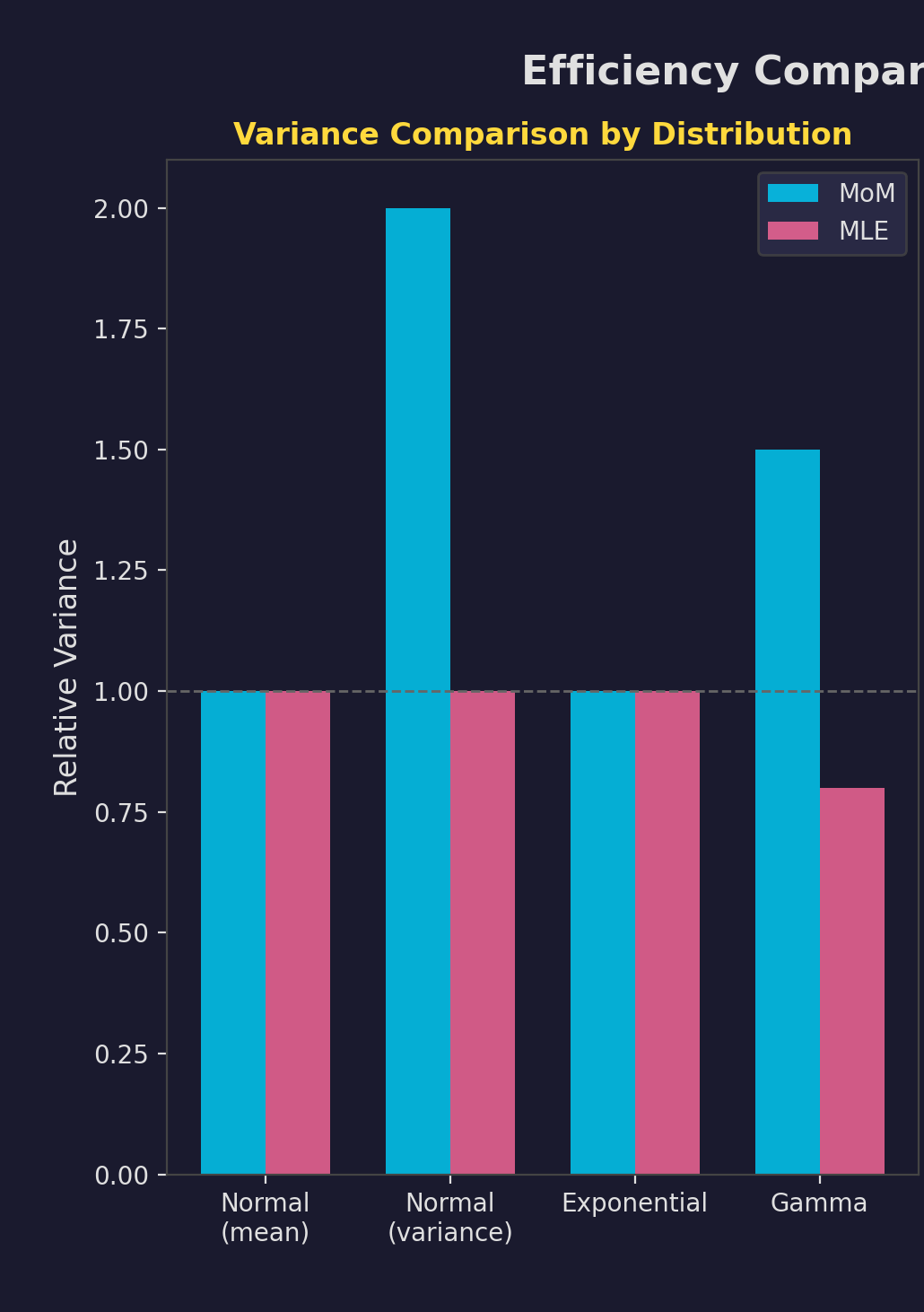
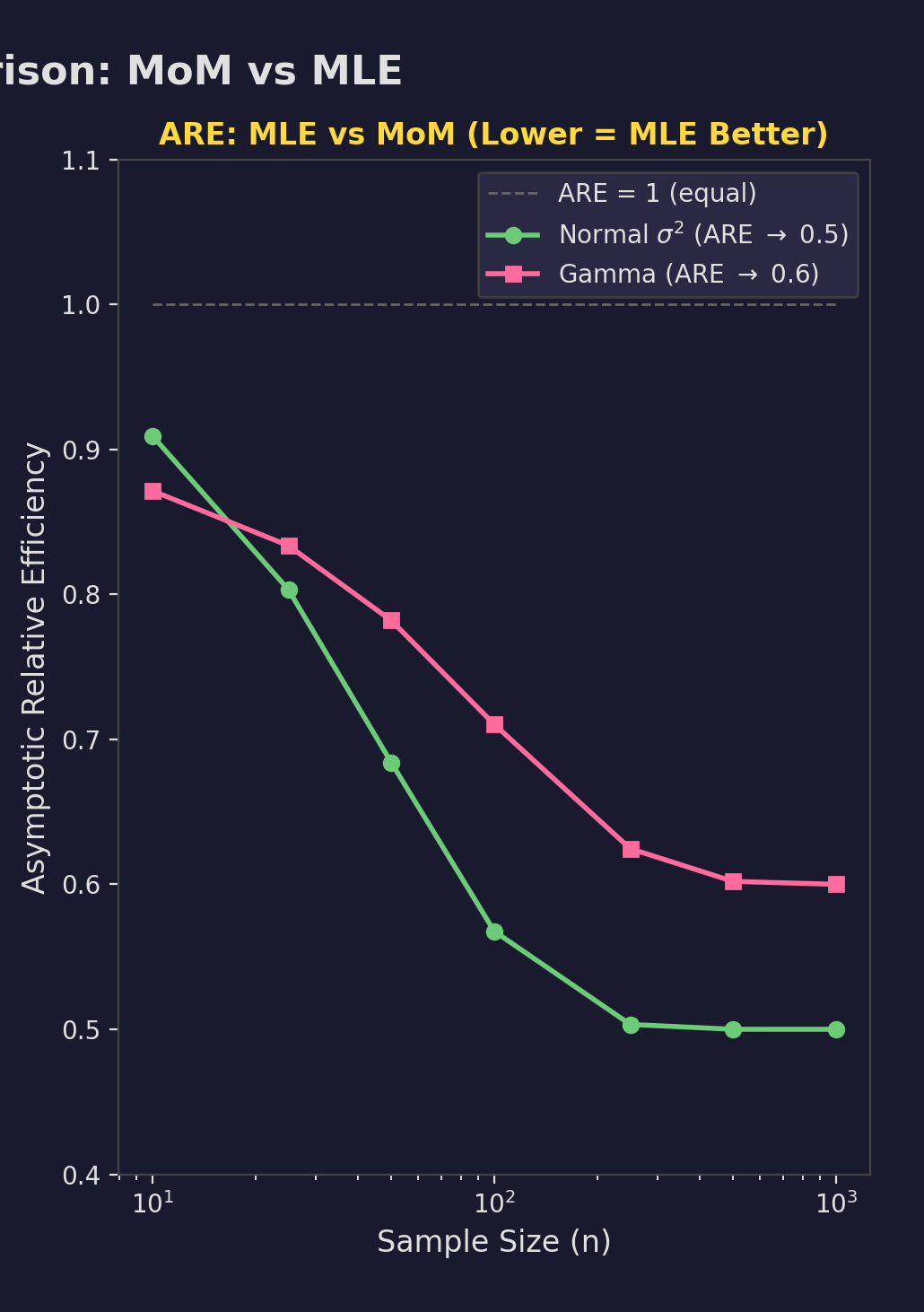
Relative Efficiency
$$ARE = \frac{Var_{MLE}}{Var_{MoM}}$$- Normal $\mu$: ARE = 1
- Normal $\sigma^2$: ARE = 0.5
- Gamma: MLE wins
When to Use Which?
Quick estimates, starting values, simple distributions
Optimal estimates, inference, model comparison
Use MoM estimates as starting values for MLE optimization.
Application: Linear Regression
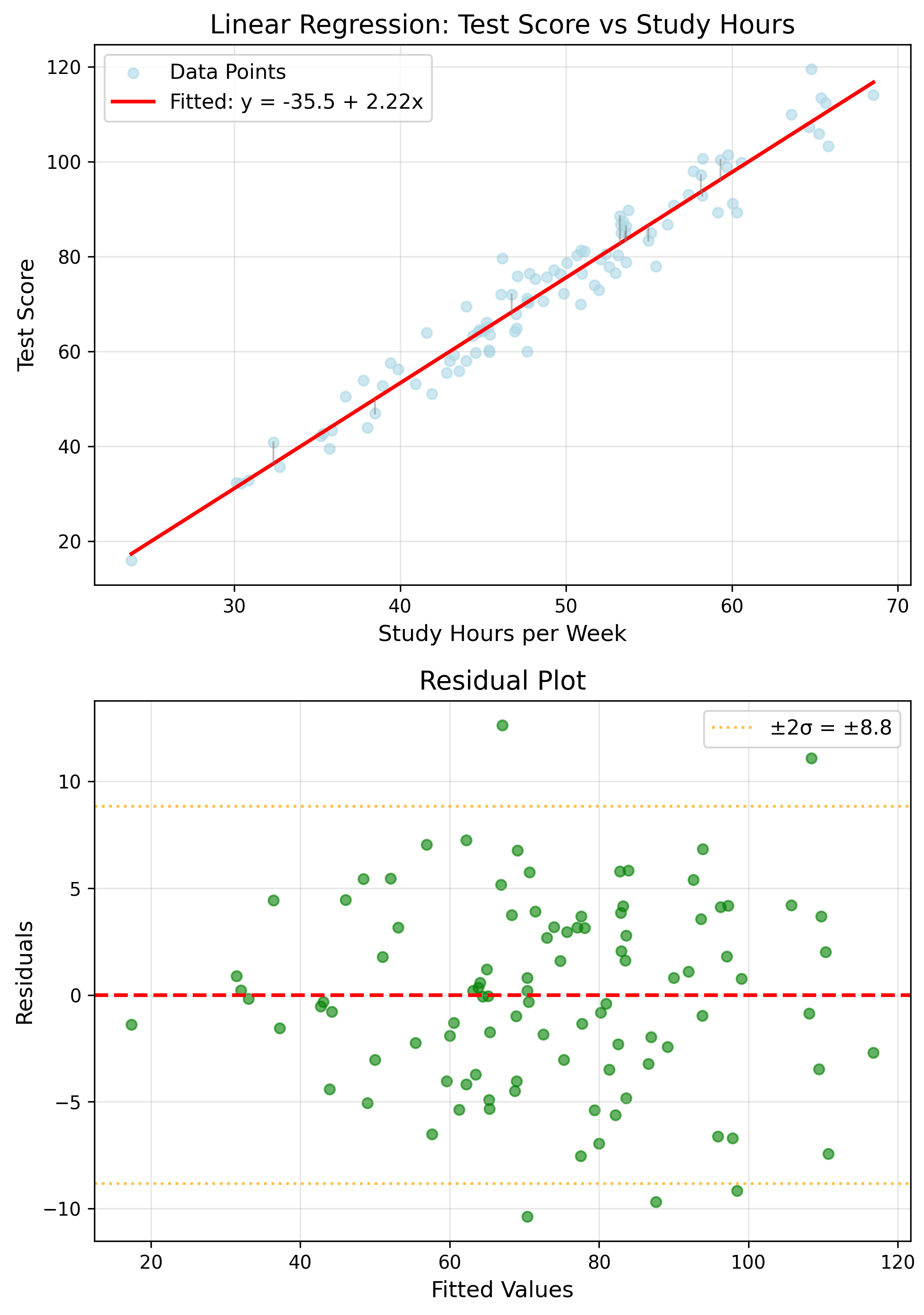
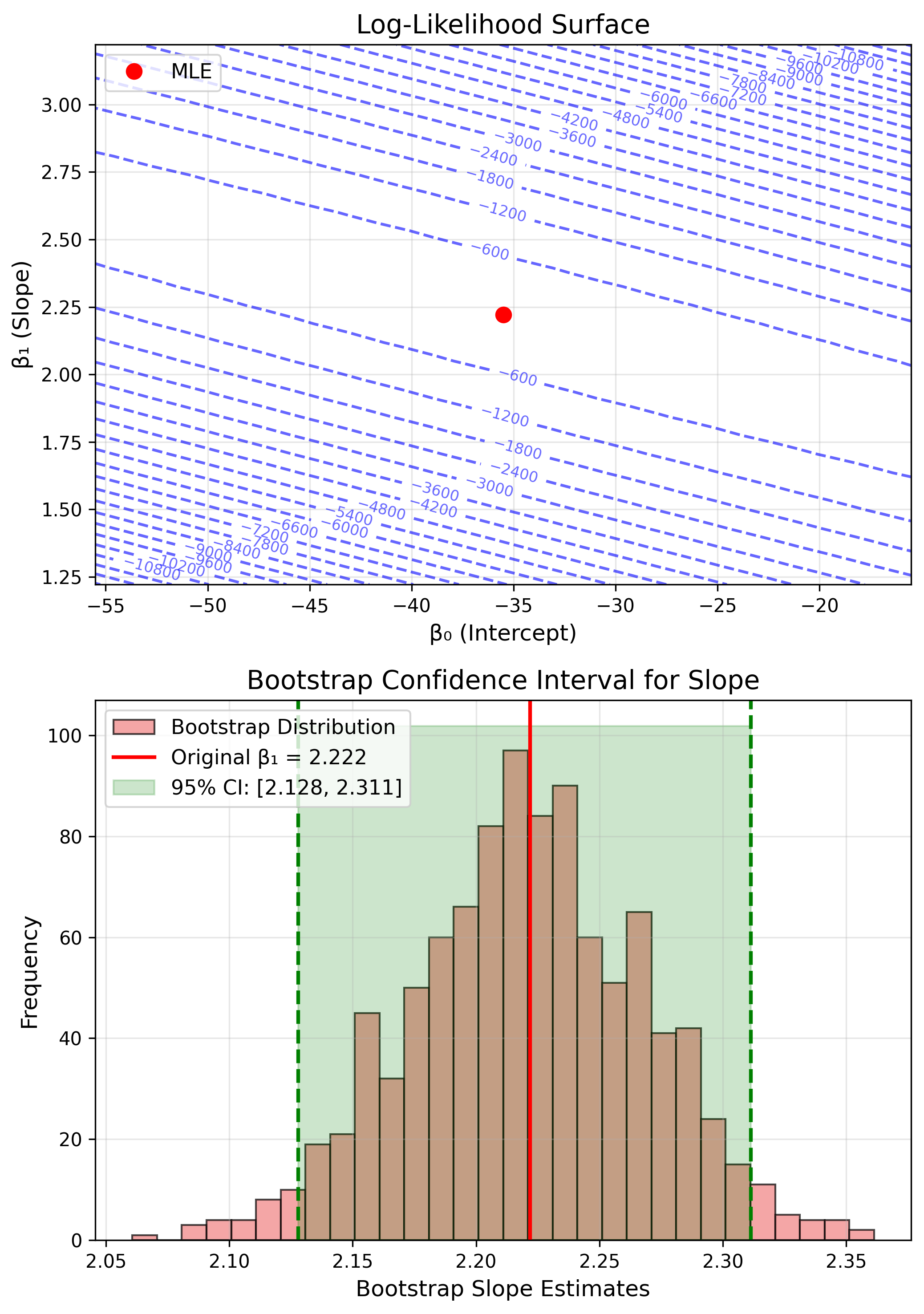
$y = \beta_0 + \beta_1 x + \epsilon$
Estimates
$\hat{\beta}_1 = \frac{\sum(x_i-\bar{x})(y_i-\bar{y})}{\sum(x_i-\bar{x})^2}$
Application: Logistic Regression
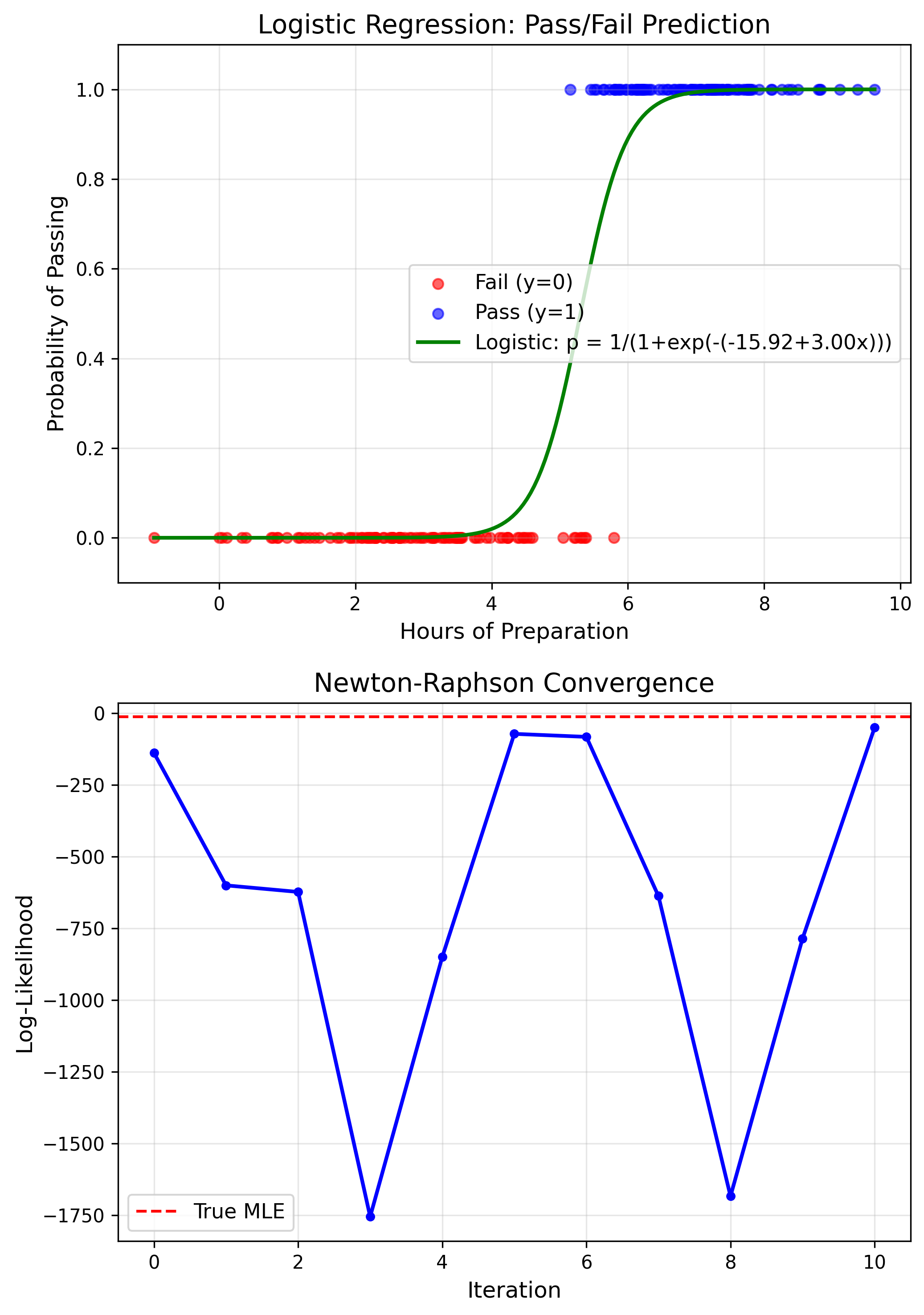
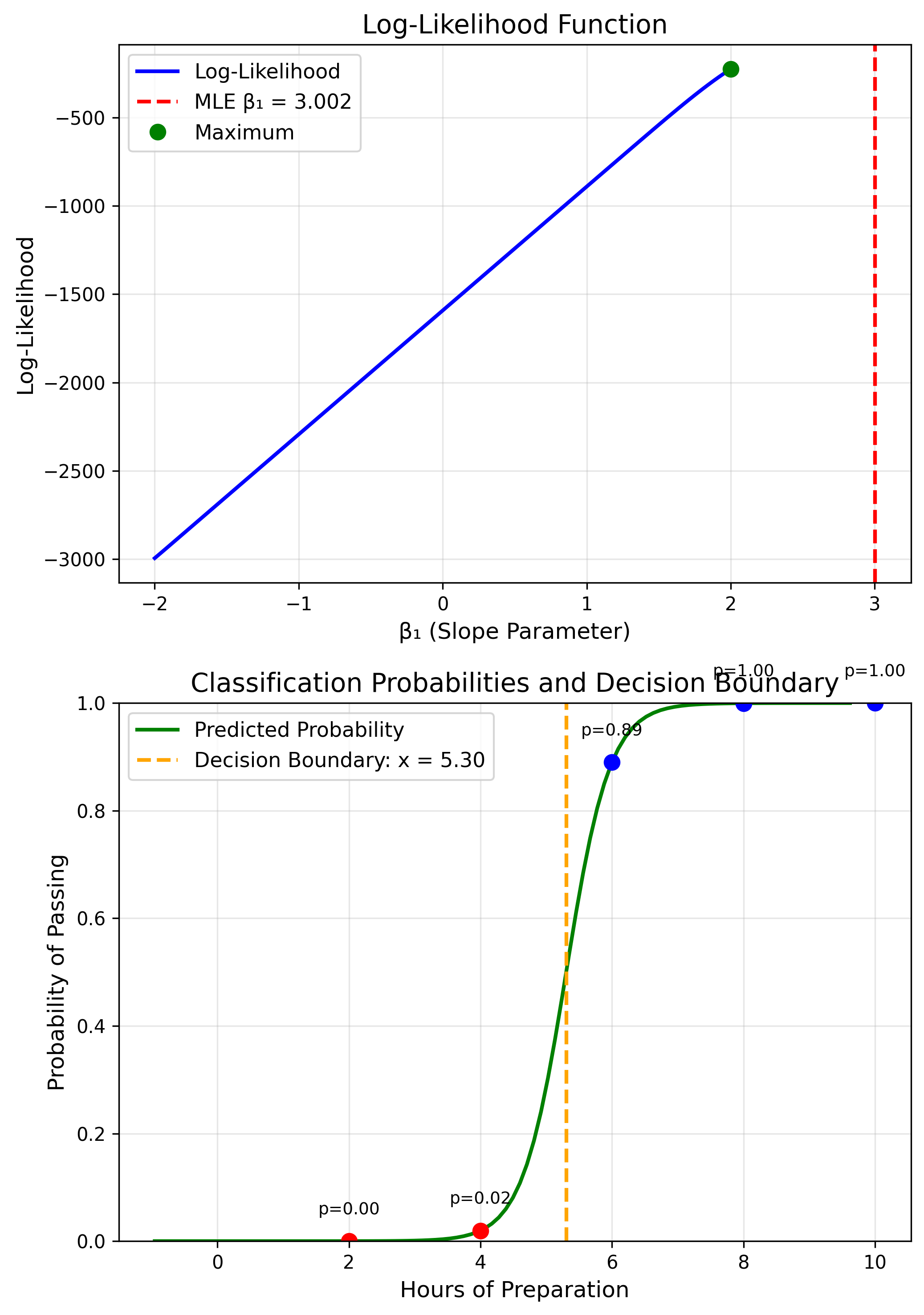
$P(Y=1) = \frac{1}{1+e^{-(\beta_0+\beta_1 X)}}$
No closed-form; requires numerical optimization.
Application: Gaussian Mixtures
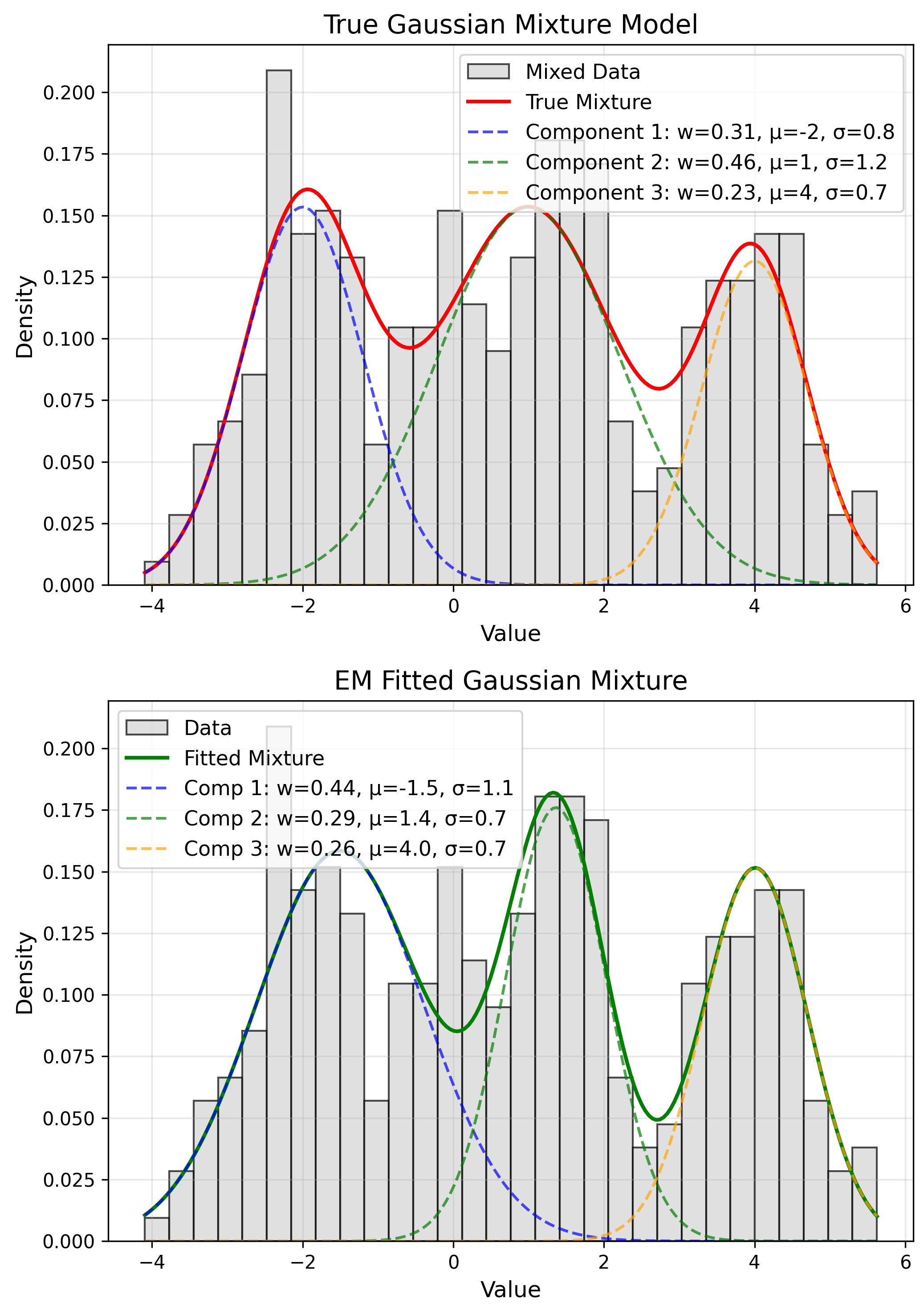
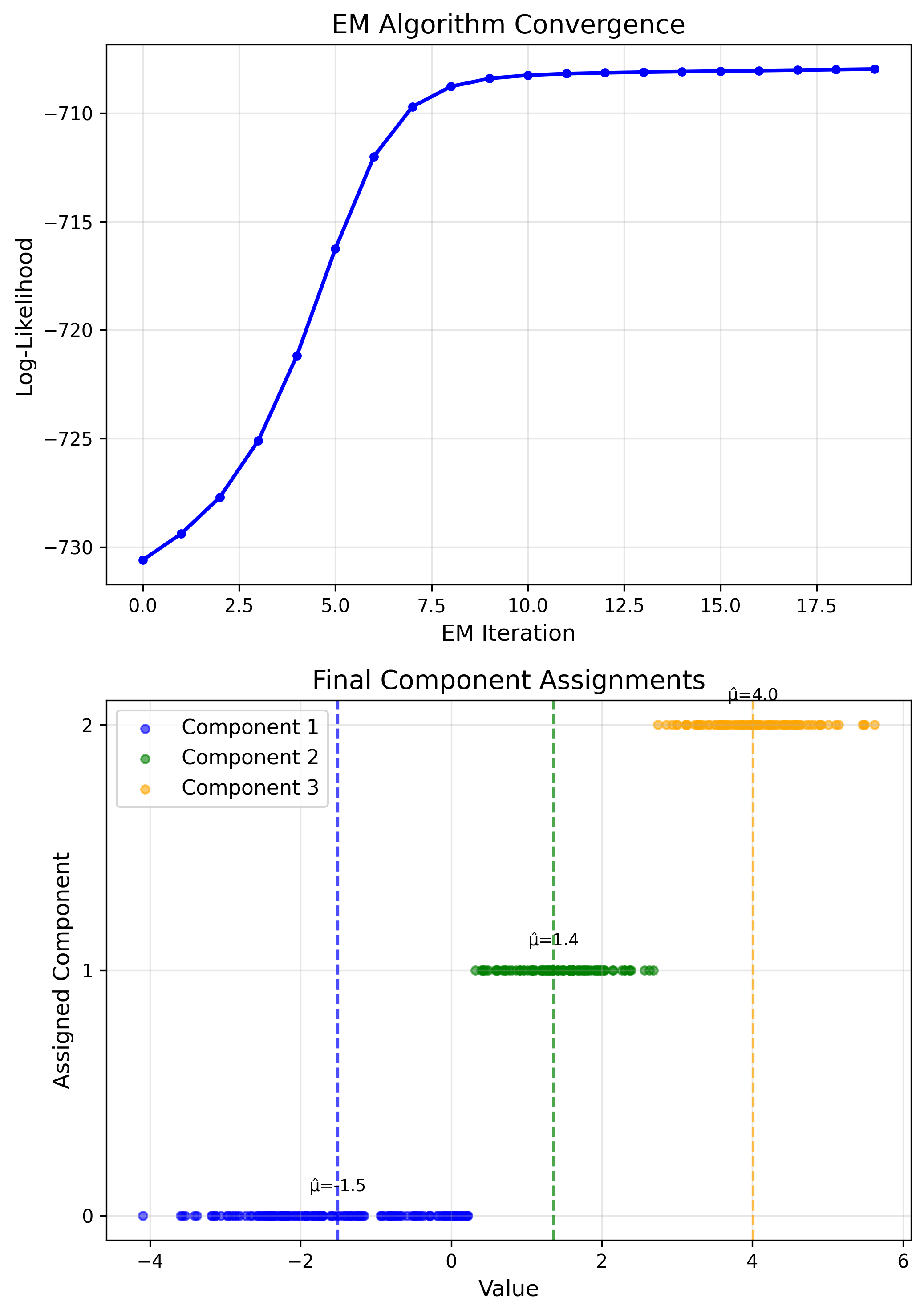
$f(x) = \sum_k \pi_k N(x|\mu_k, \sigma_k^2)$
EM Algorithm
E: Compute assignments
M: Update params
Application: Time Series (ARIMA)
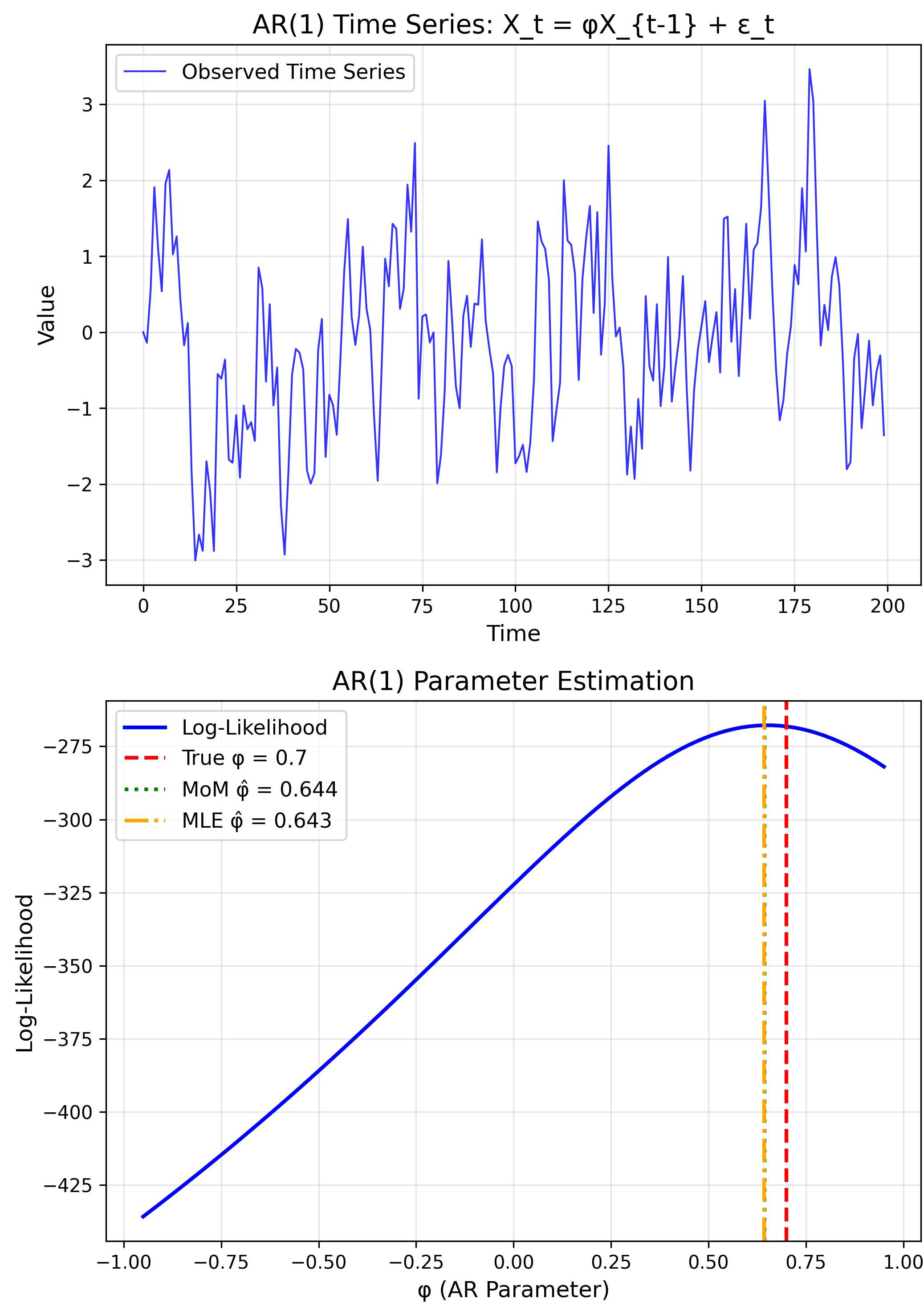
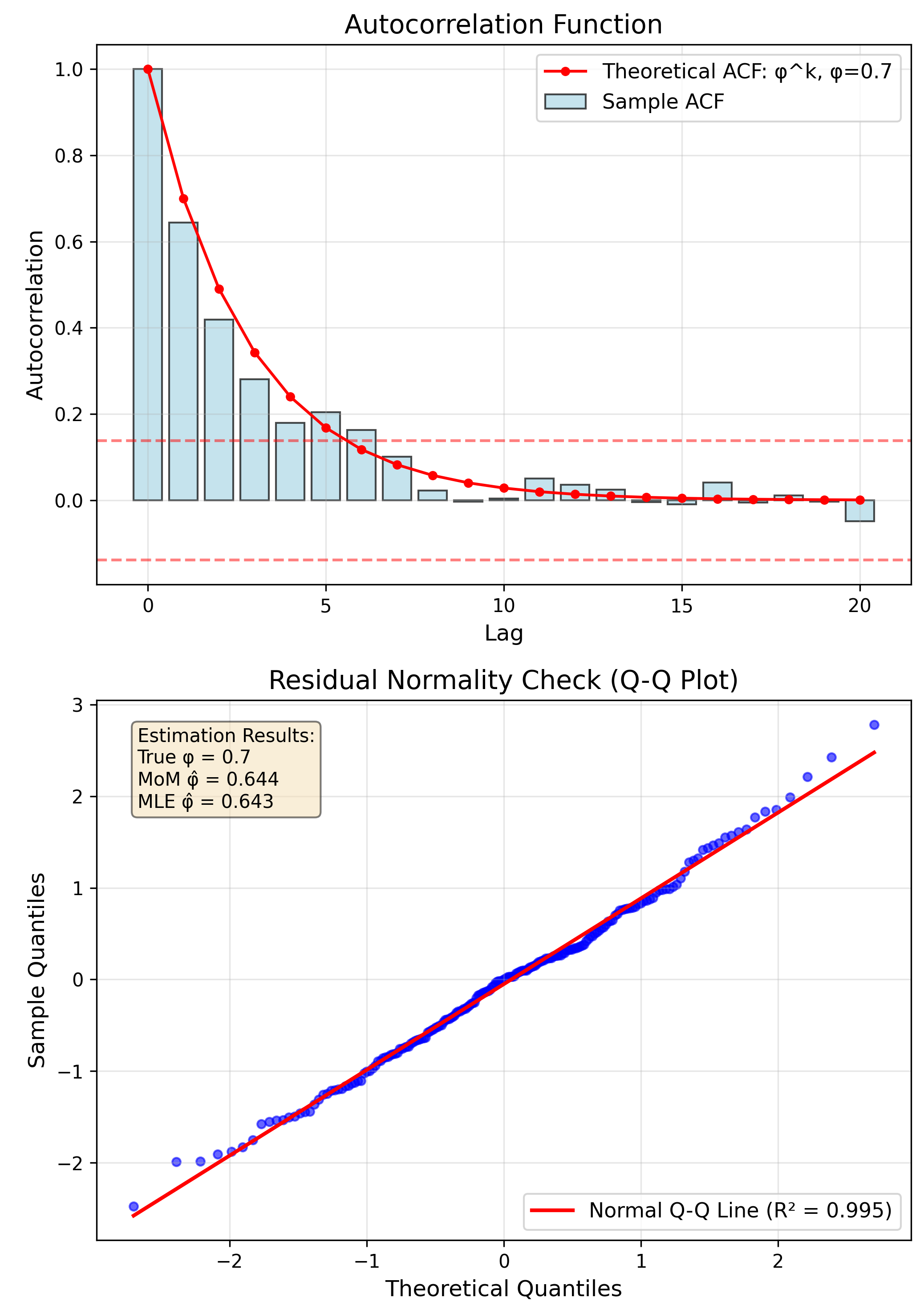
MoM
Yule-Walker equations
MLE
Kalman filter + optimization
Robust Estimation
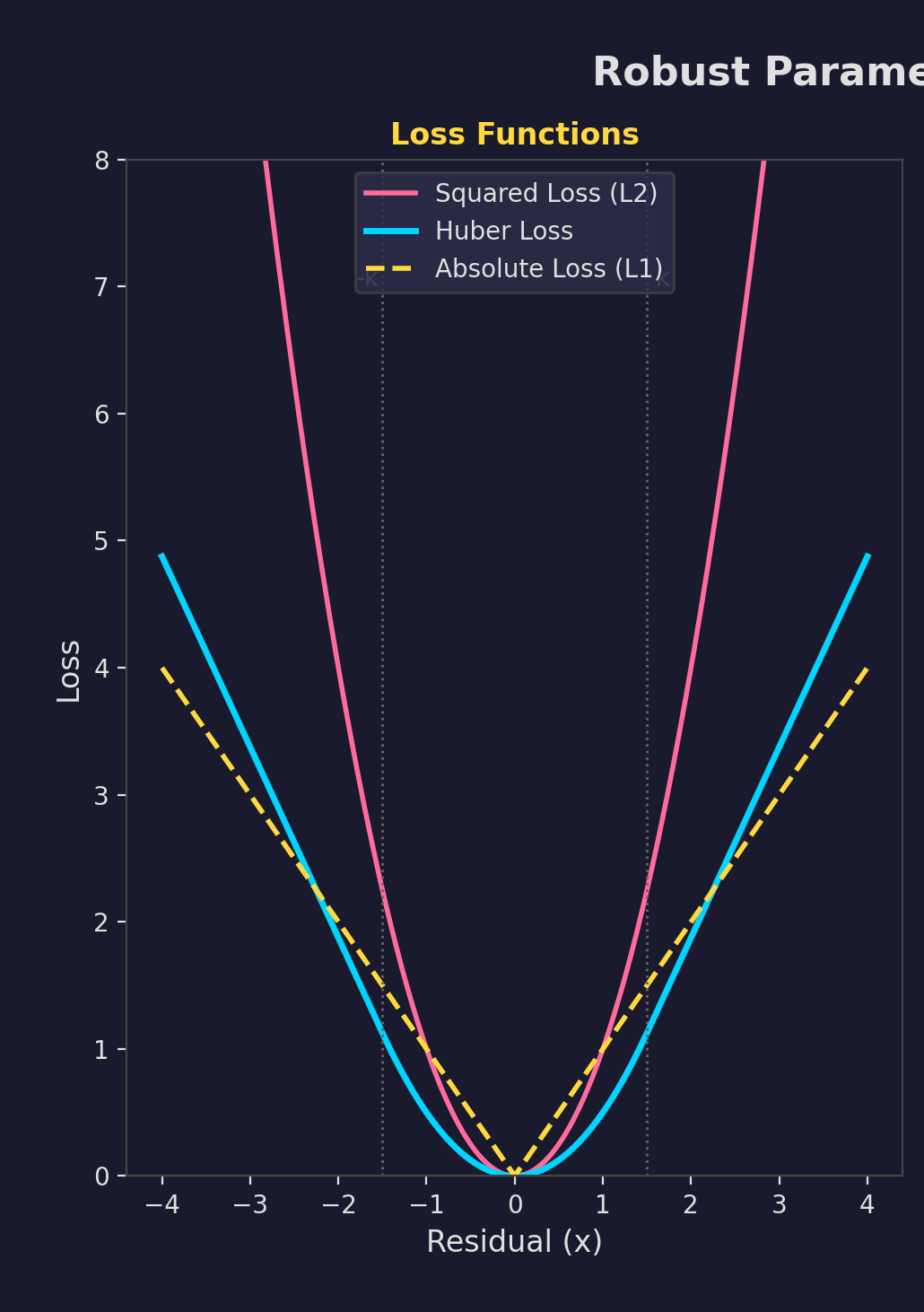
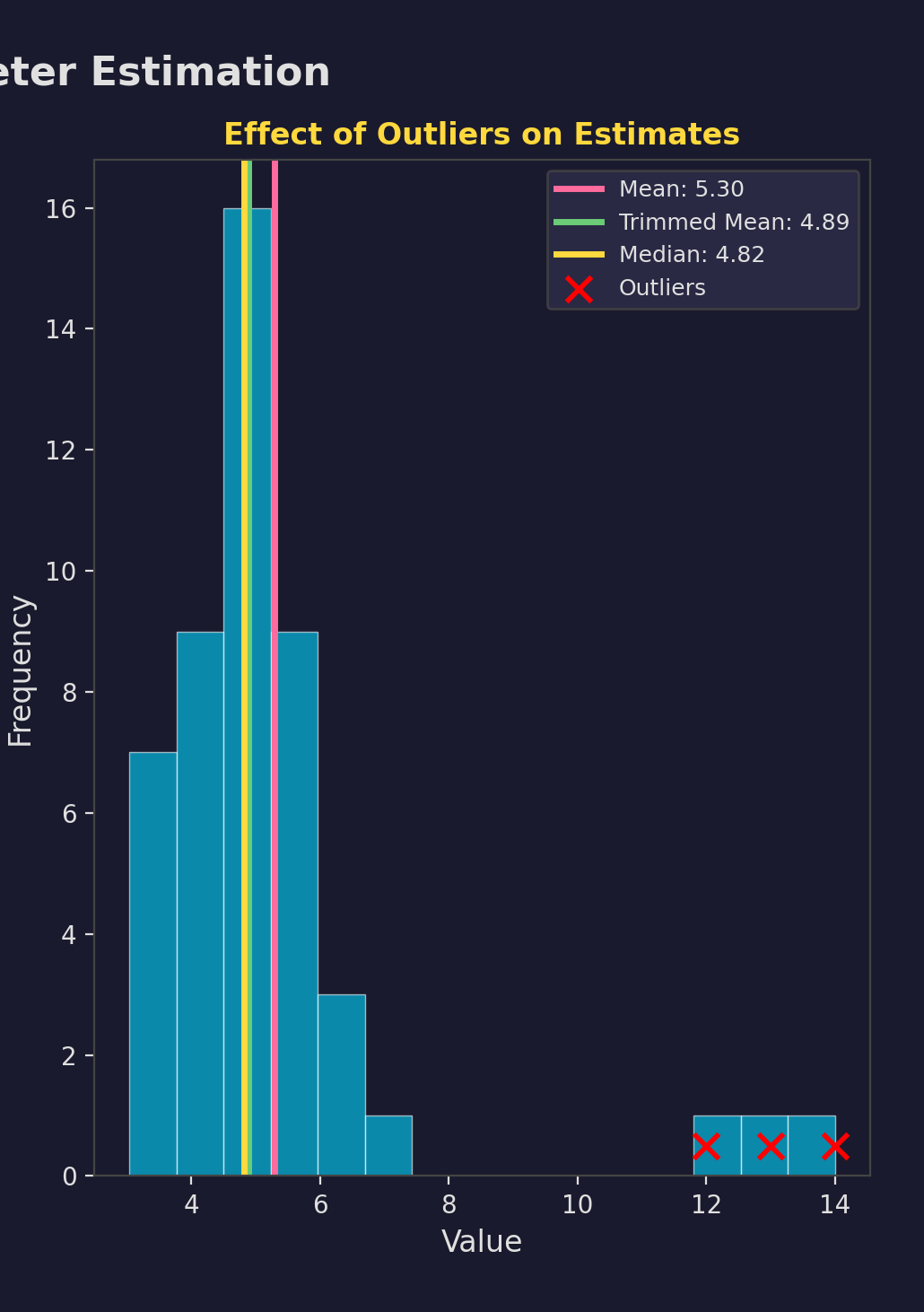
MLE sensitive to outliers
- M-estimators
- Huber loss
- Trimmed means
Bootstrap Estimation
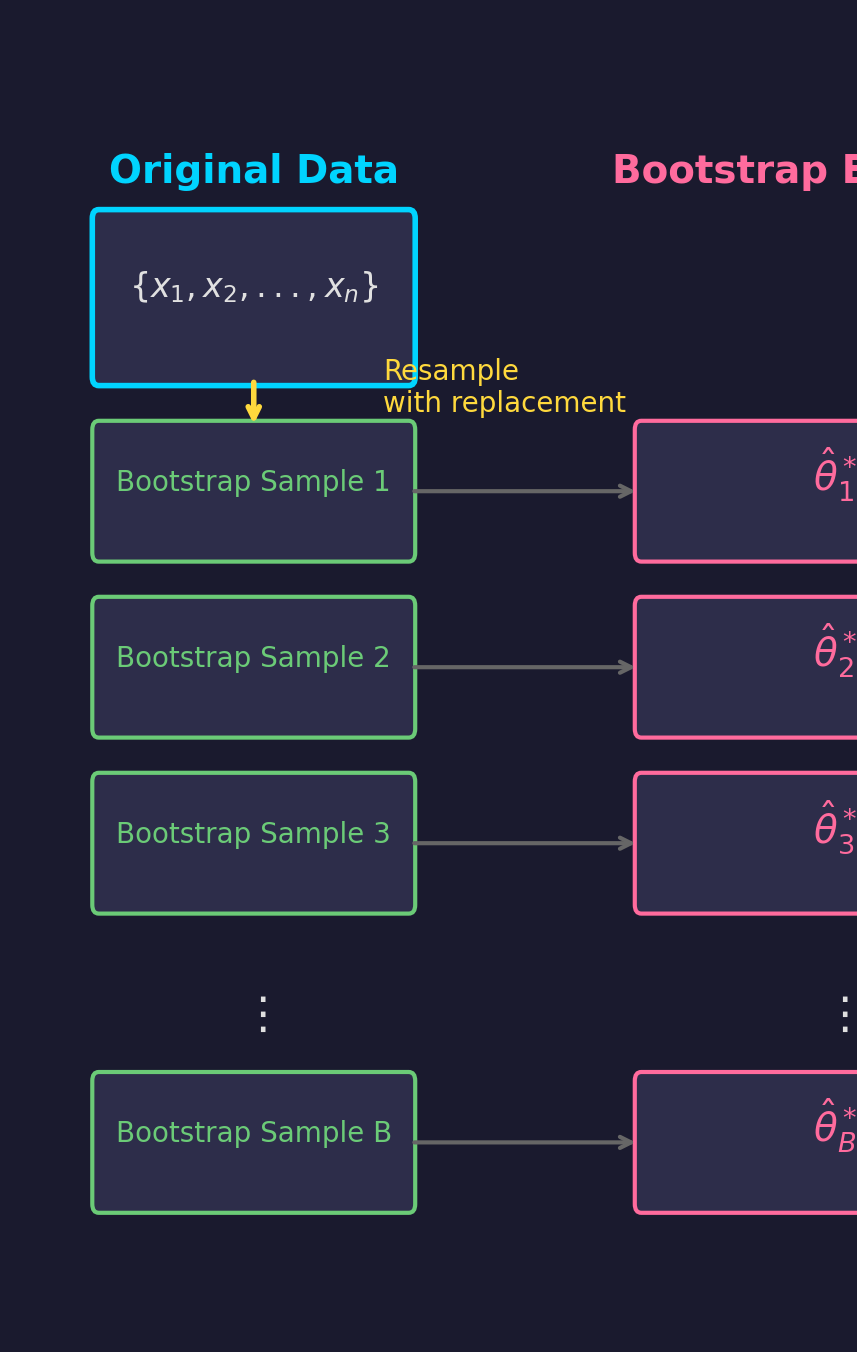
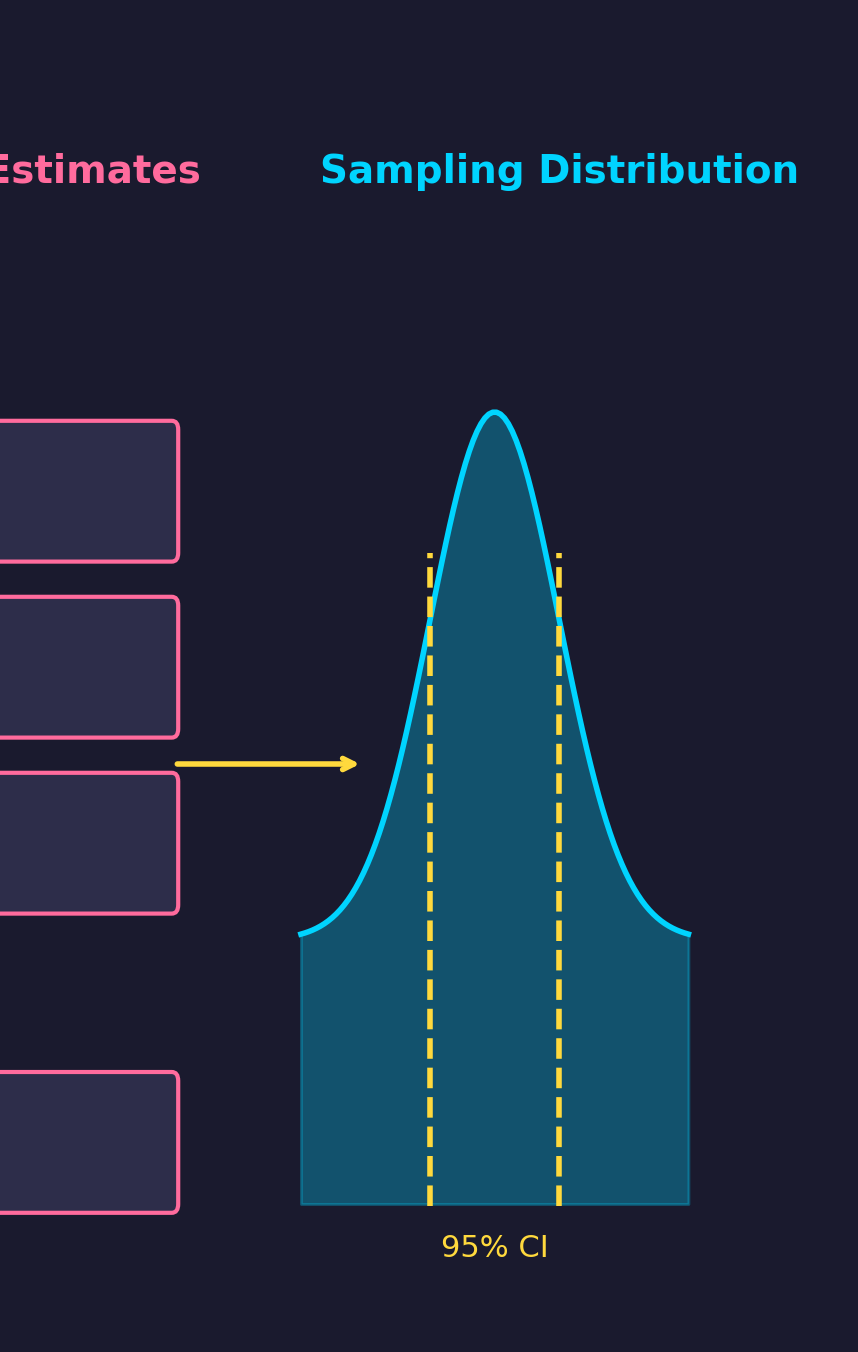
Resample from data to estimate uncertainty.
- Draw $B$ bootstrap samples
- Compute $\hat{\theta}_b^*$ for each
- Use distribution for inference
Model Selection Criteria
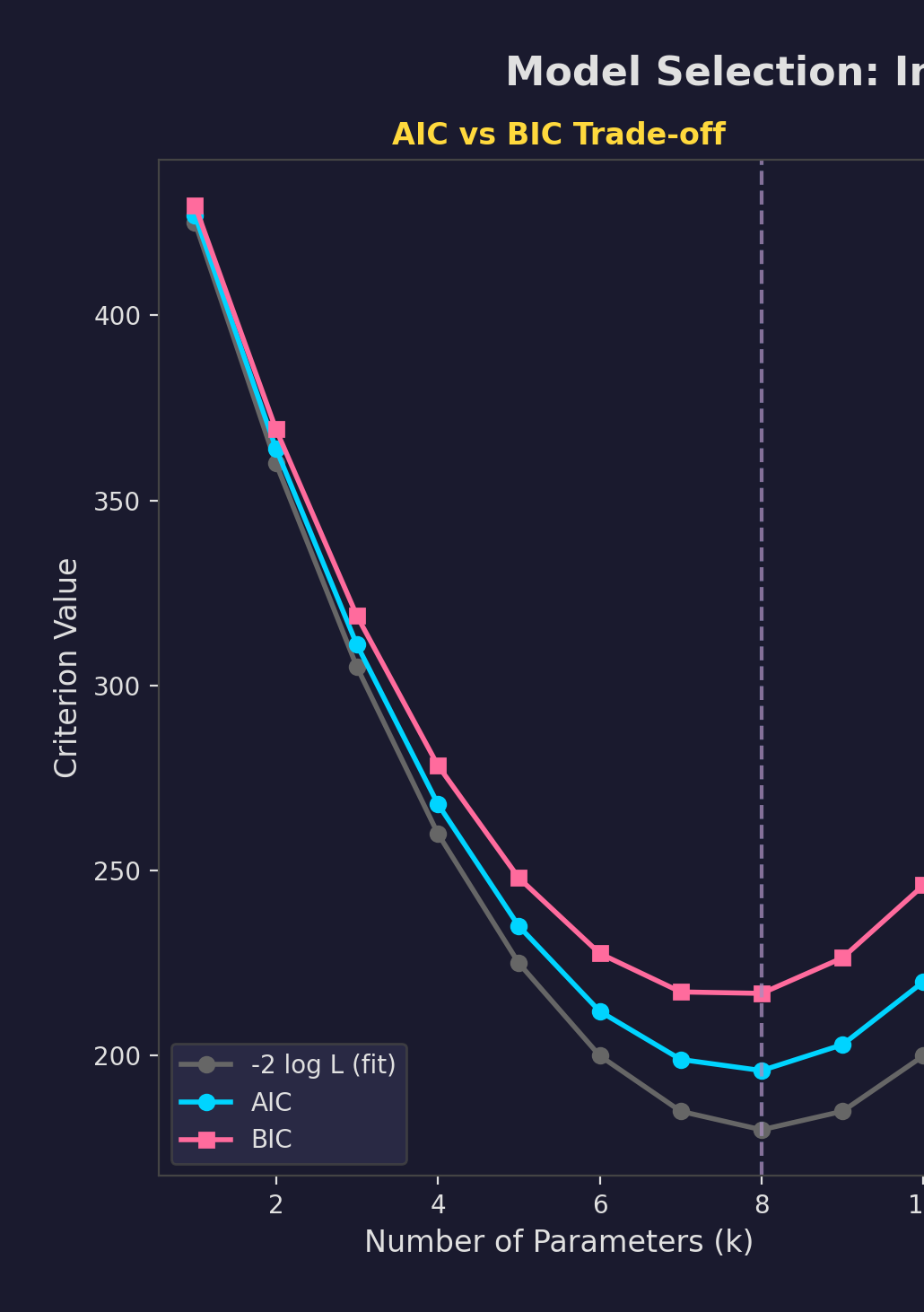

Information Criteria
$AIC = -2\ell + 2k$
$BIC = -2\ell + k\log n$
Lower is better
Diagnostic Tools
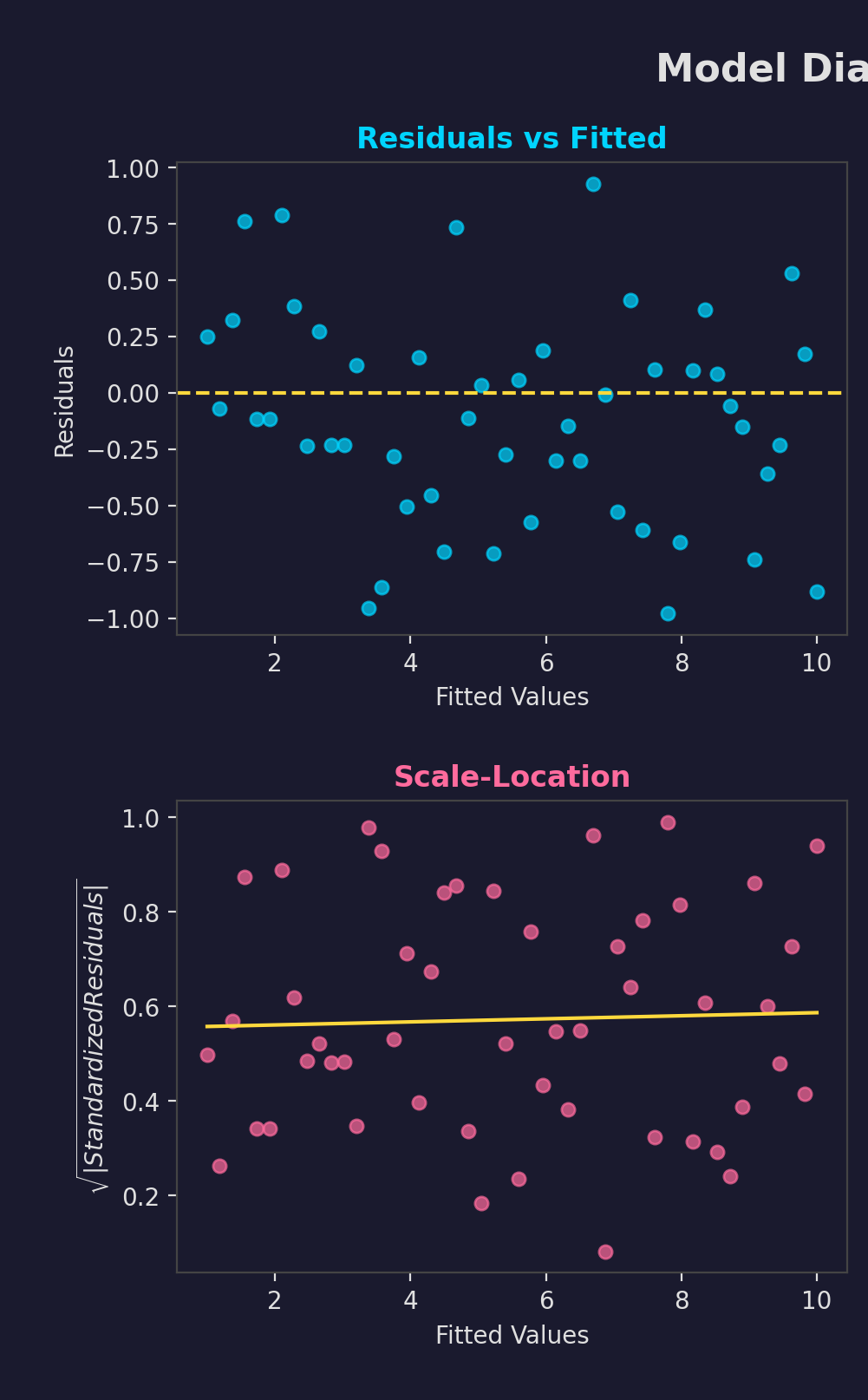
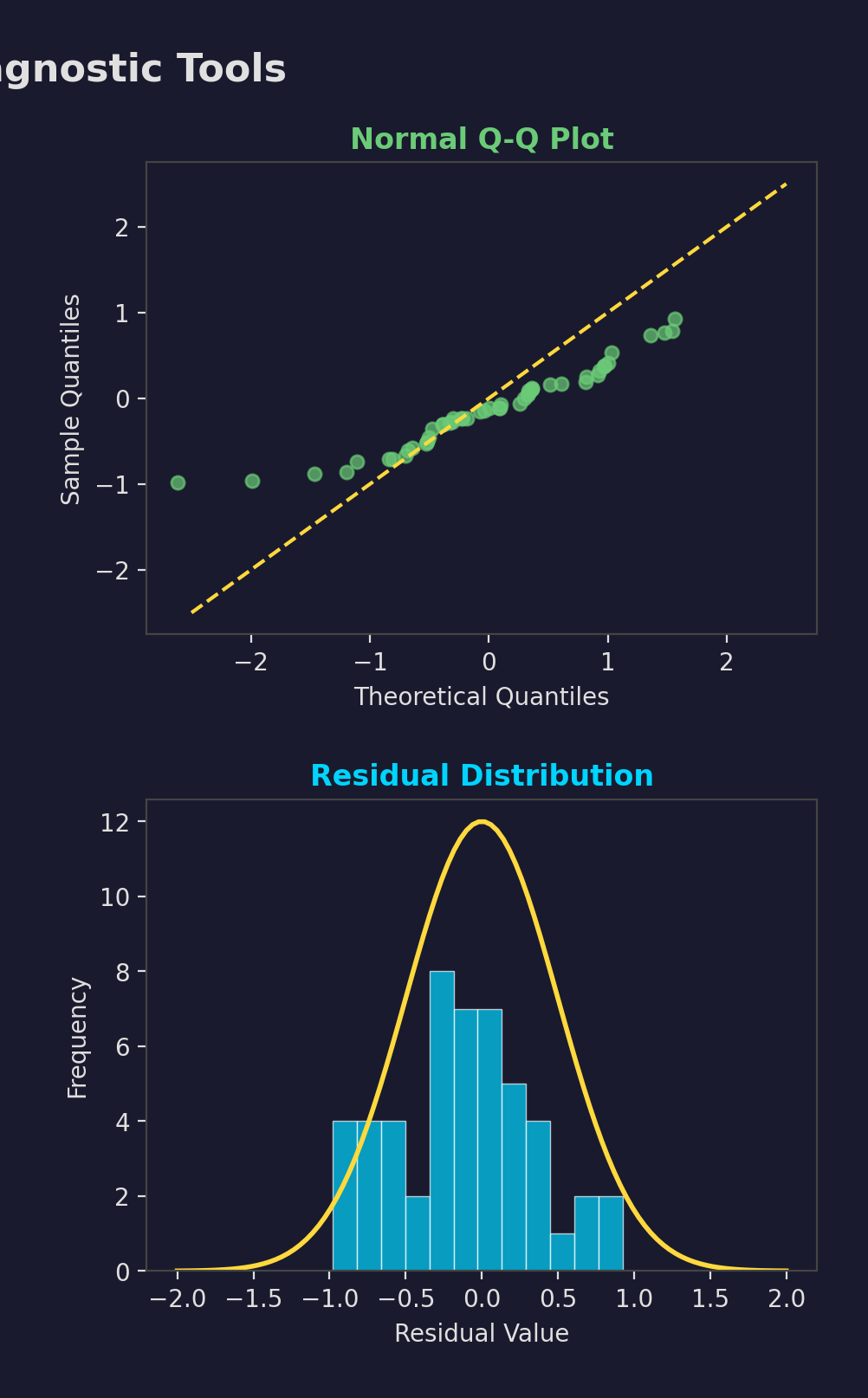
- Residual plots
- Q-Q plots
- Goodness-of-fit tests
- Cross-validation
Computational Tools
- Python: scipy, statsmodels
- R: optim(), maxLik
- Bayesian: Stan, PyMC
- DL: PyTorch, TensorFlow
Common Pitfalls
Wrong Distribution
Use EDA and goodness-of-fit tests
Small Samples
Use bootstrap or Bayesian
Outliers
Use robust methods
Overfitting
Use AIC/BIC, cross-validation
Best Practices
- Start with MoM estimates
- Use MoM as MLE starting values
- Validate assumptions
- Report confidence intervals
- Check diagnostics
Key Takeaways
Match moments. Simple, quick, good for starting values.
Maximize likelihood. Optimal, efficient, asymptotically normal.
Parameter estimation is fundamental to statistical modeling and ML!
Next Steps
Advanced Topics
GMM, Regularization, Bayesian MCMC
Practice Tools
scipy.optimize, statsmodels, PyMC
Ready for Module 2: Linear Regression
End of Module 01
Parameter Estimation
Questions?