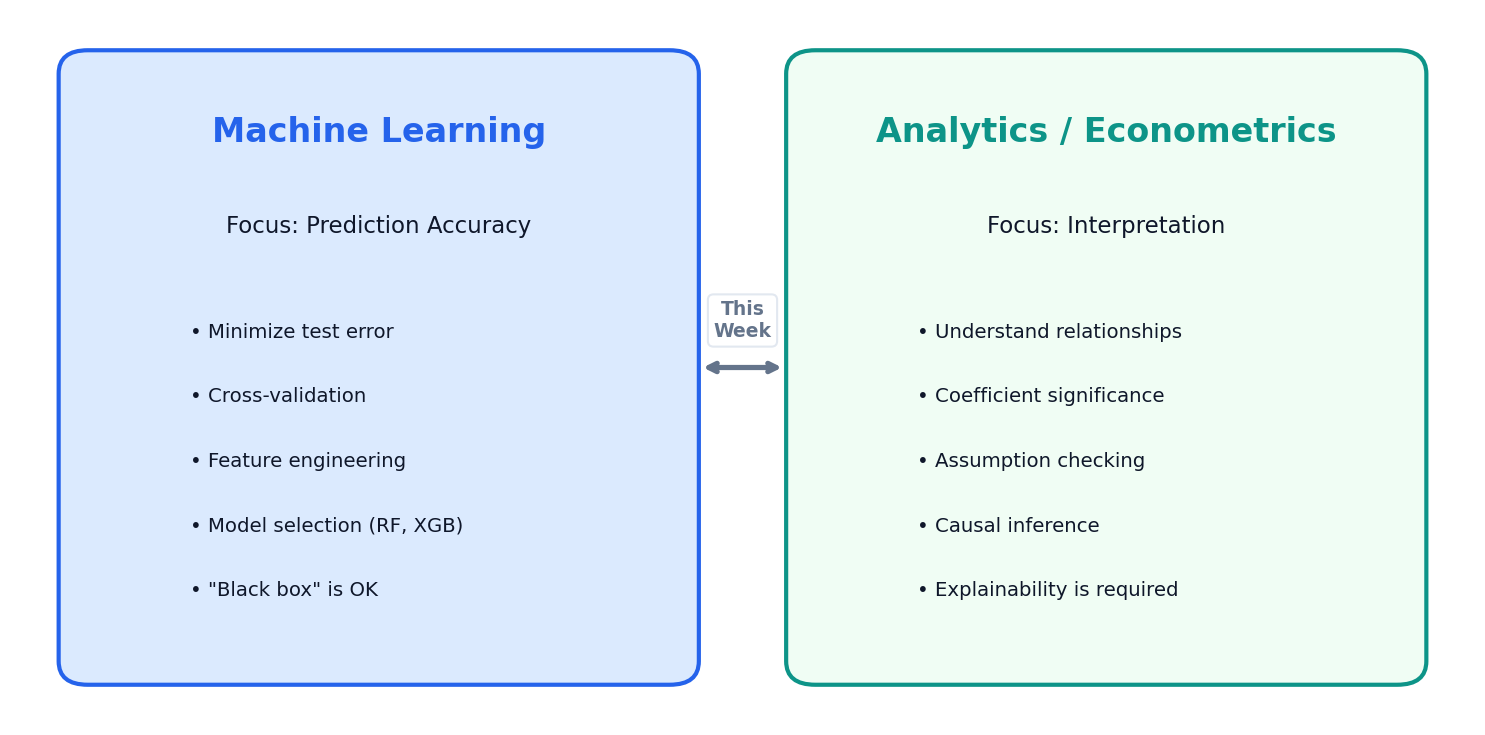
ML Predicts; Analytics Explains
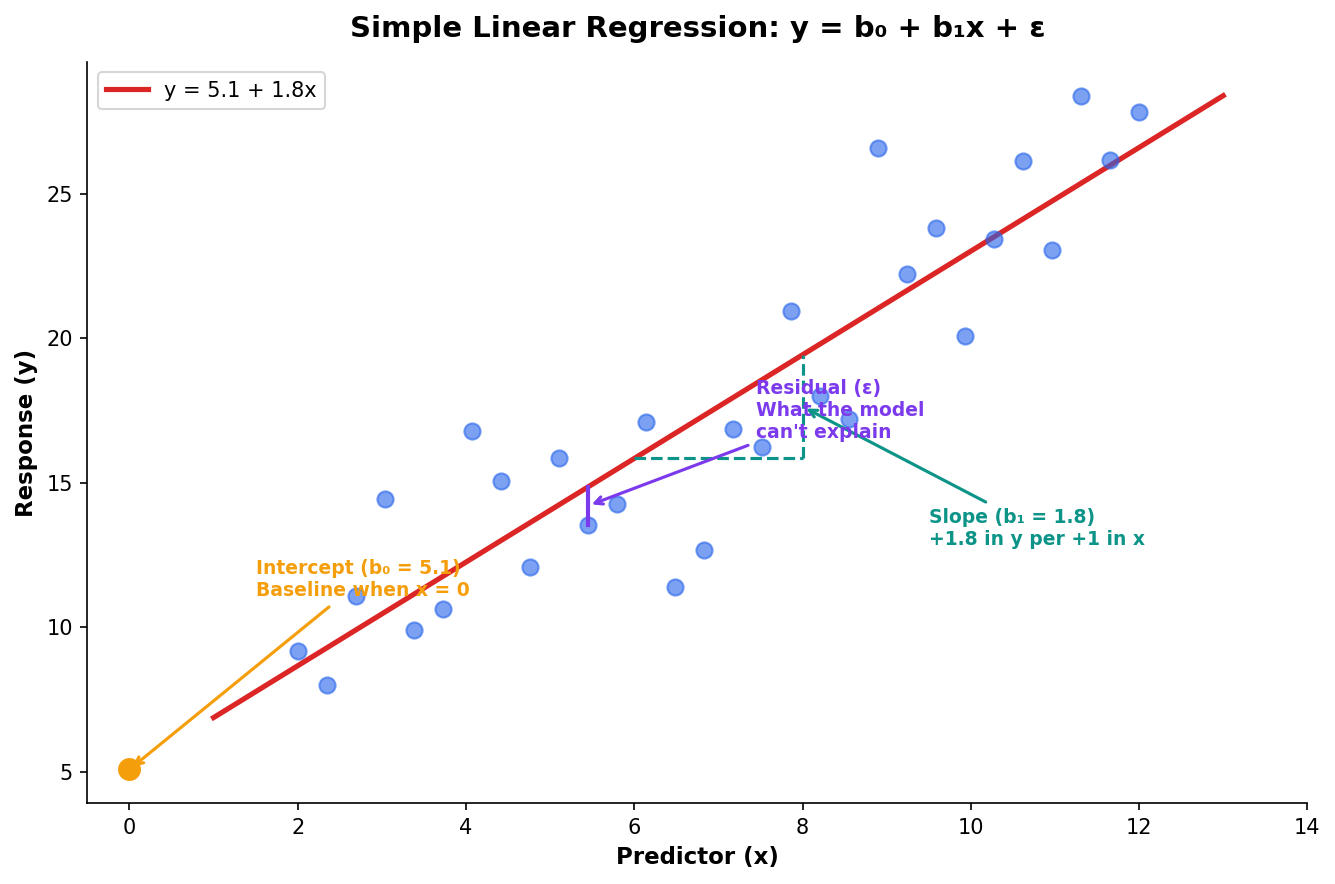
The Regression Equation Tells a Story
Every regression equation has three characters: the baseline (b₀), the effects (b₁, b₂…), and the unexplained (ε). Together they tell a story about what drives the outcome.
The Intercept (b₀)
The predicted value when all predictors are zero — often a theoretical baseline.
The Slope (b₁)
The change in y for a 1-unit increase in x, holding everything else constant.
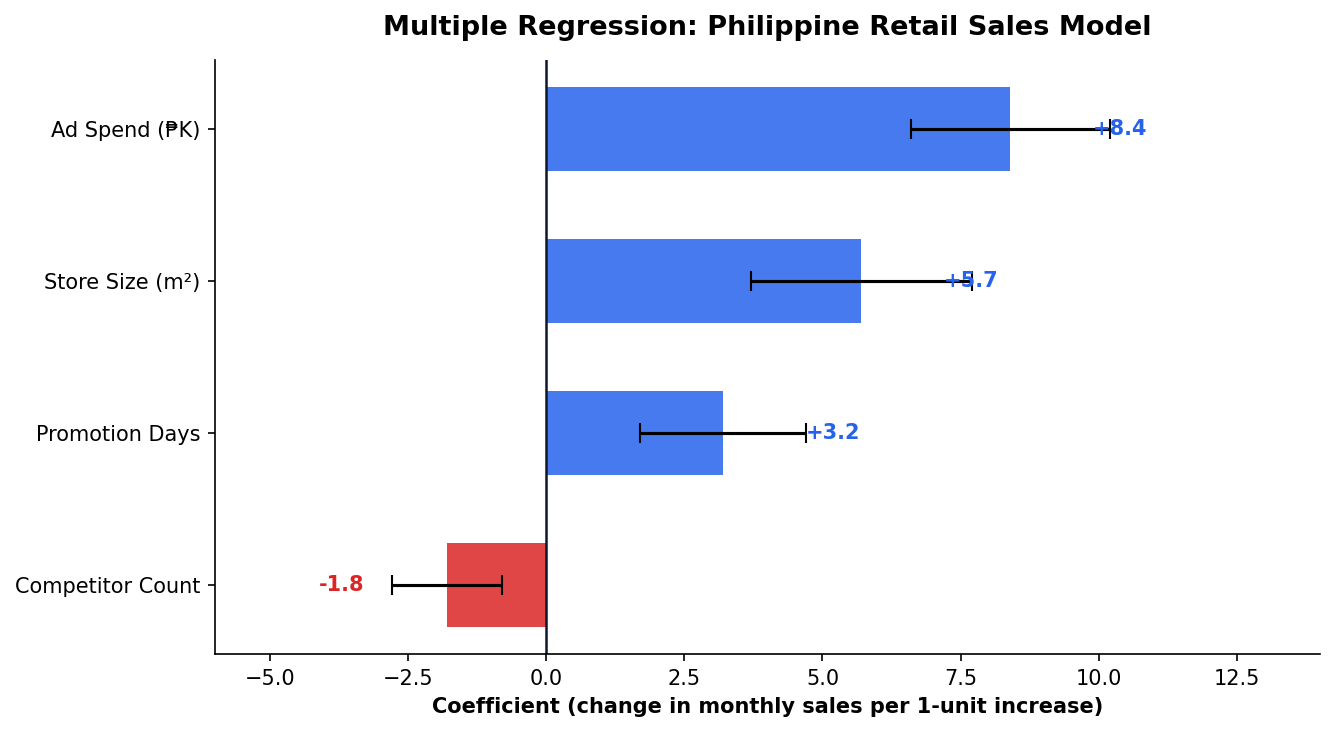
Each Coefficient Is a Ceteris Paribus Statement
LINE: Four Assumptions You Must Check

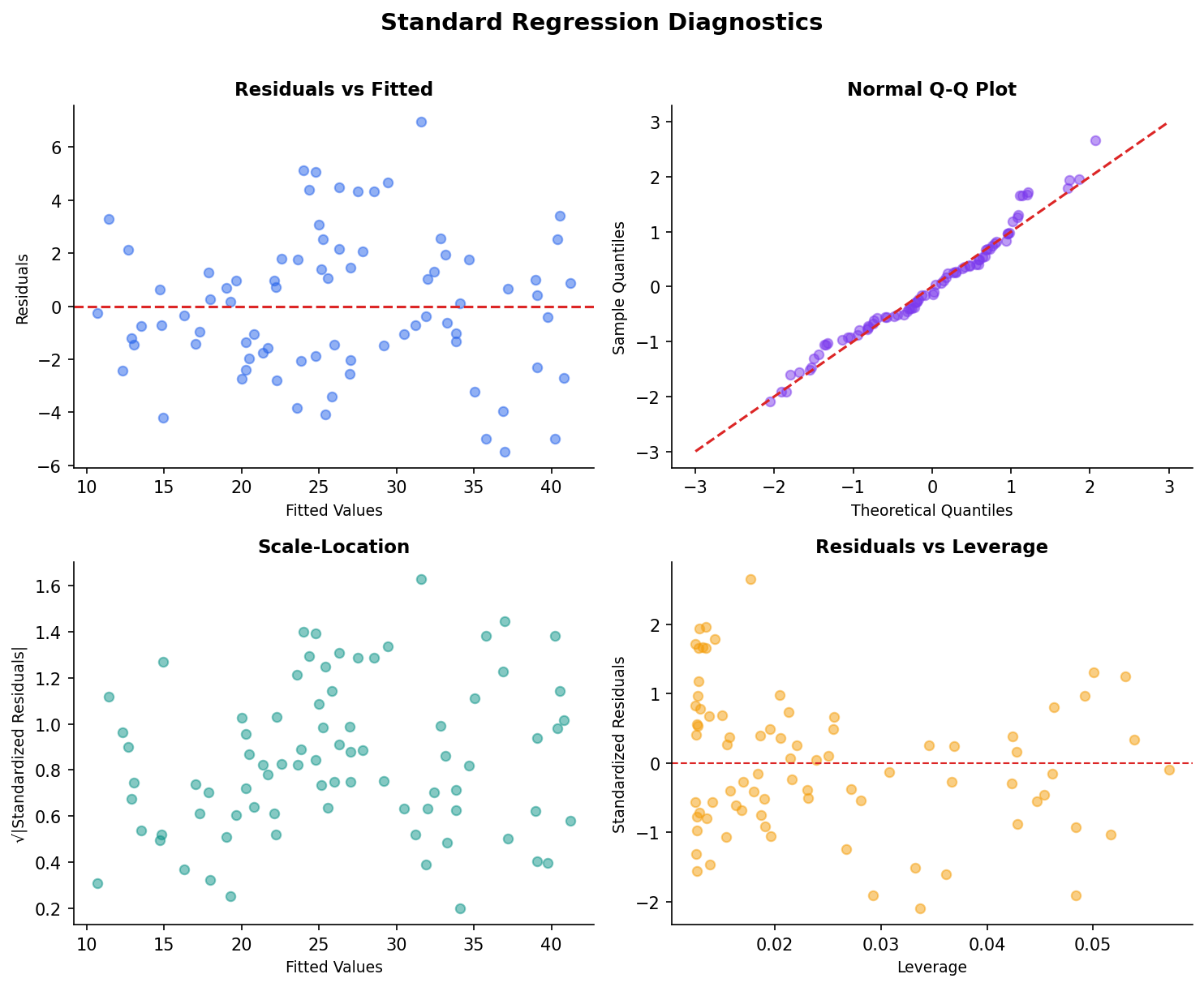
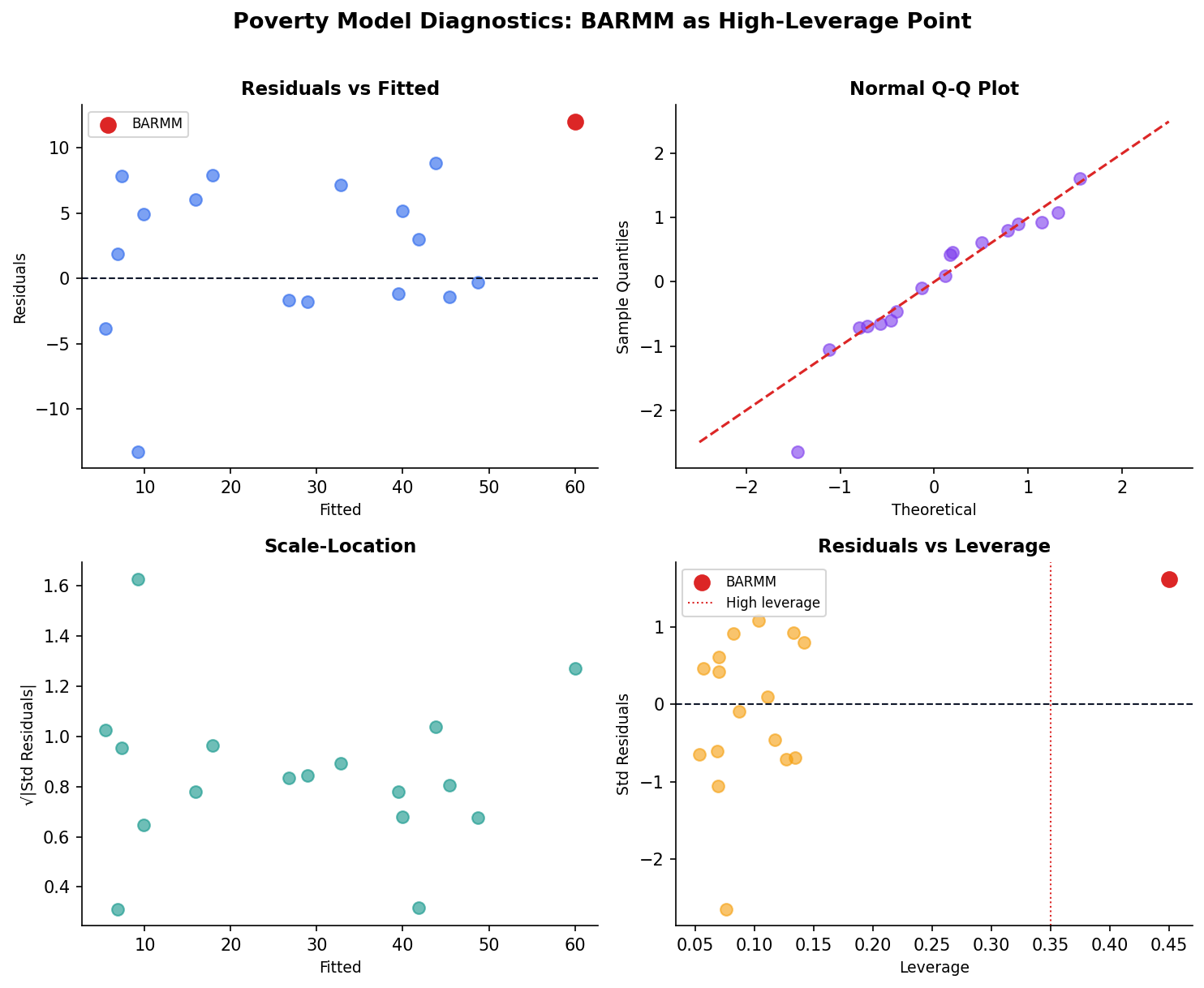
Residual Plots Reveal Hidden Problems
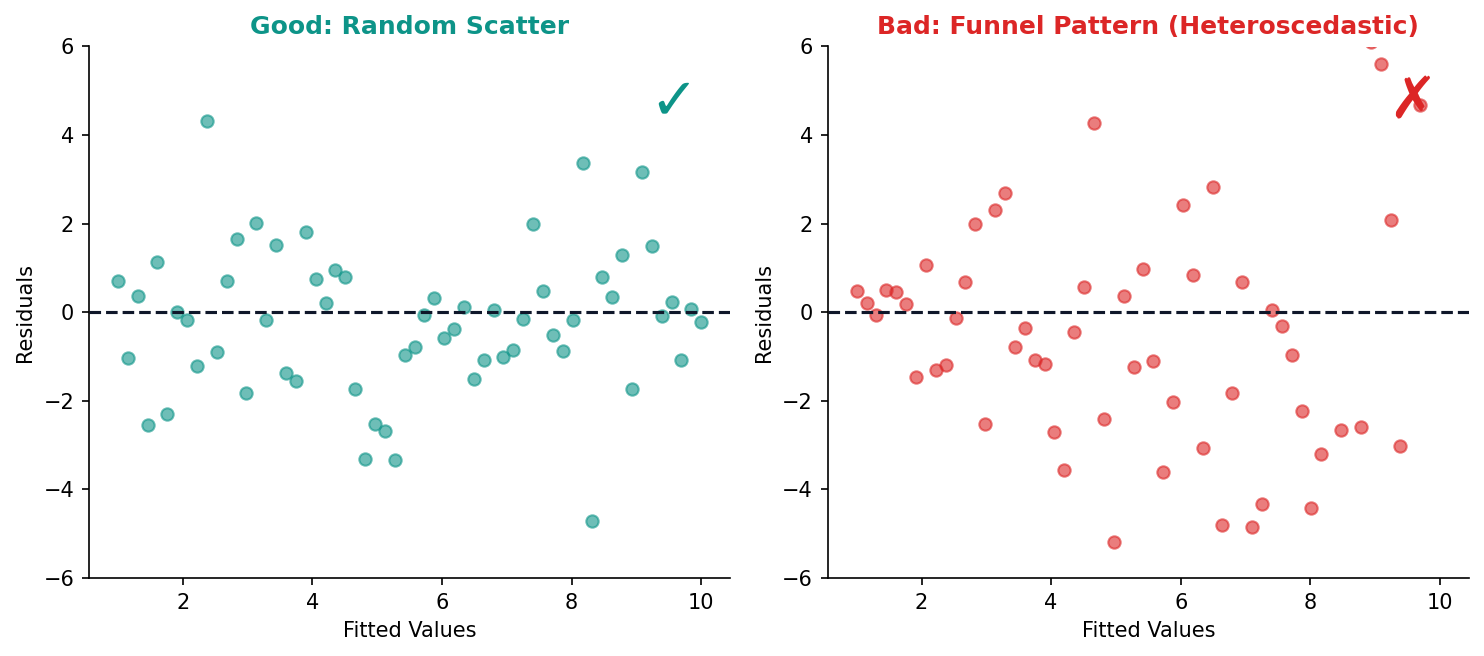
Good Residuals vs Bad Residuals
The residual plot is your first diagnostic check. Random scatter means the model’s assumptions hold. Patterns reveal specific problems.
Random scatter around zero — assumptions met.
Funnel shape — variance increases with x (heteroscedasticity). Fix: log-transform y or use robust standard errors.
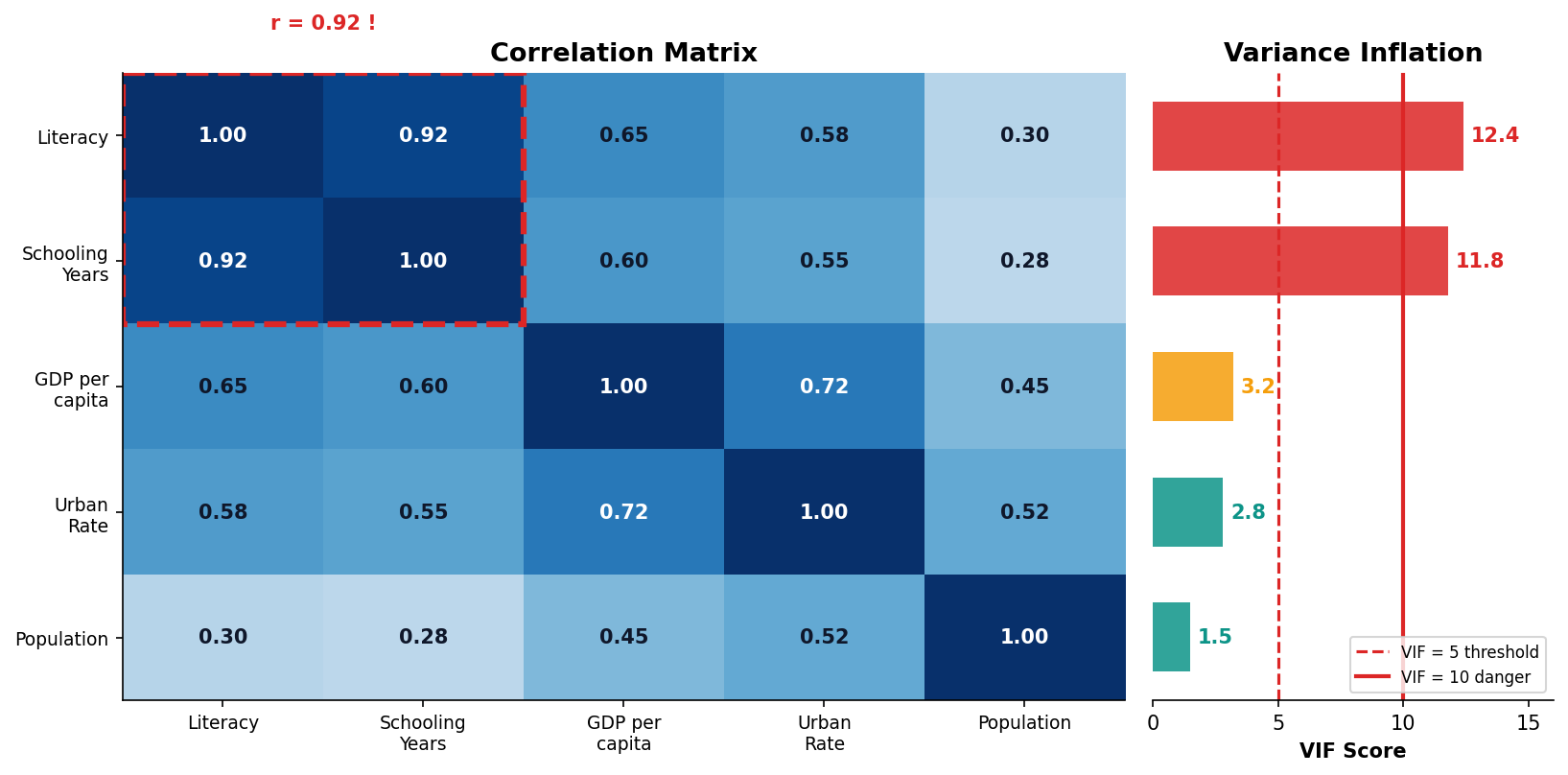
Multicollinearity Inflates Your Standard Errors
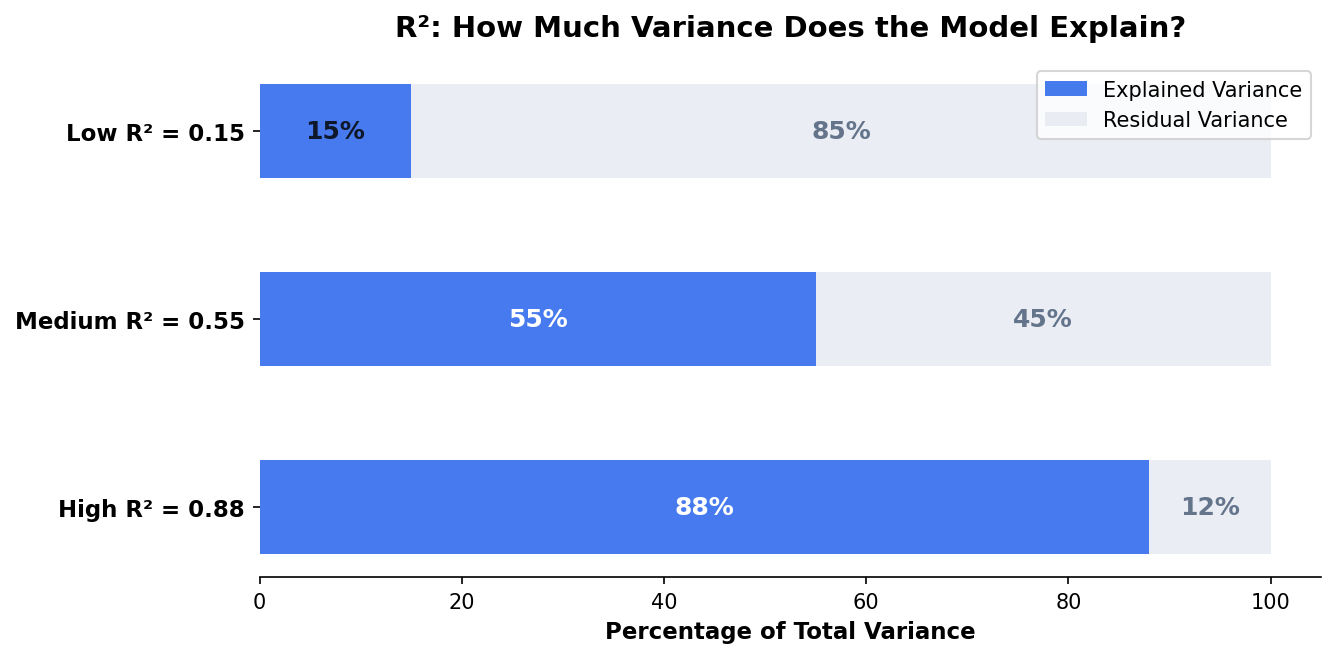
R² Measures Explained Variance
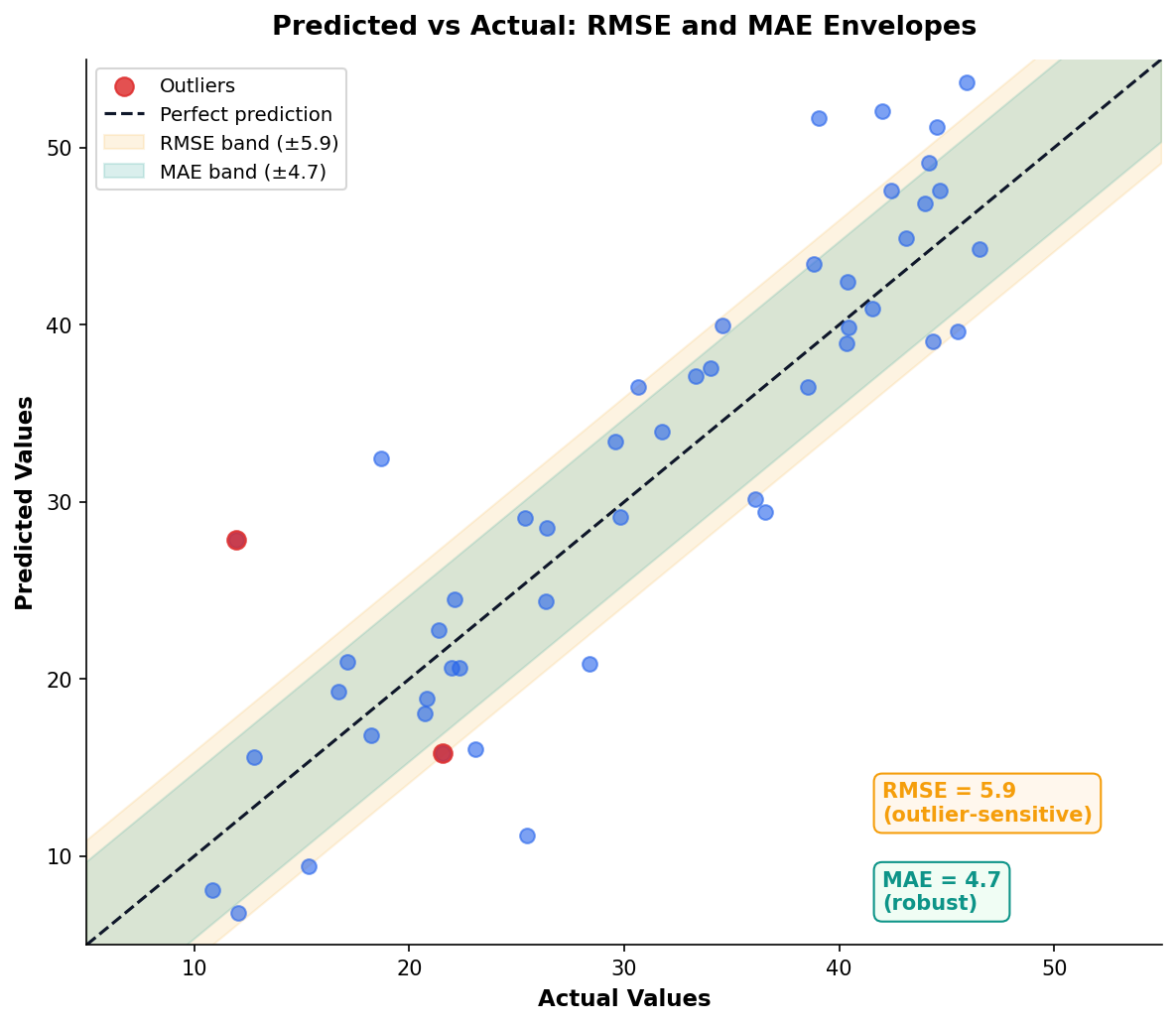
RMSE and MAE: Error in Units You Care About
Both measure prediction error in the same units as your outcome variable. RMSE penalizes large errors more heavily; MAE treats all errors equally.
| Metric | Strength | Weakness |
|---|---|---|
| RMSE | Sensitive to outliers | Penalizes big misses |
| MAE | Robust to outliers | Ignores error magnitude |
Practical Rule
Report both. If RMSE >> MAE, you have outlier predictions that need investigation.
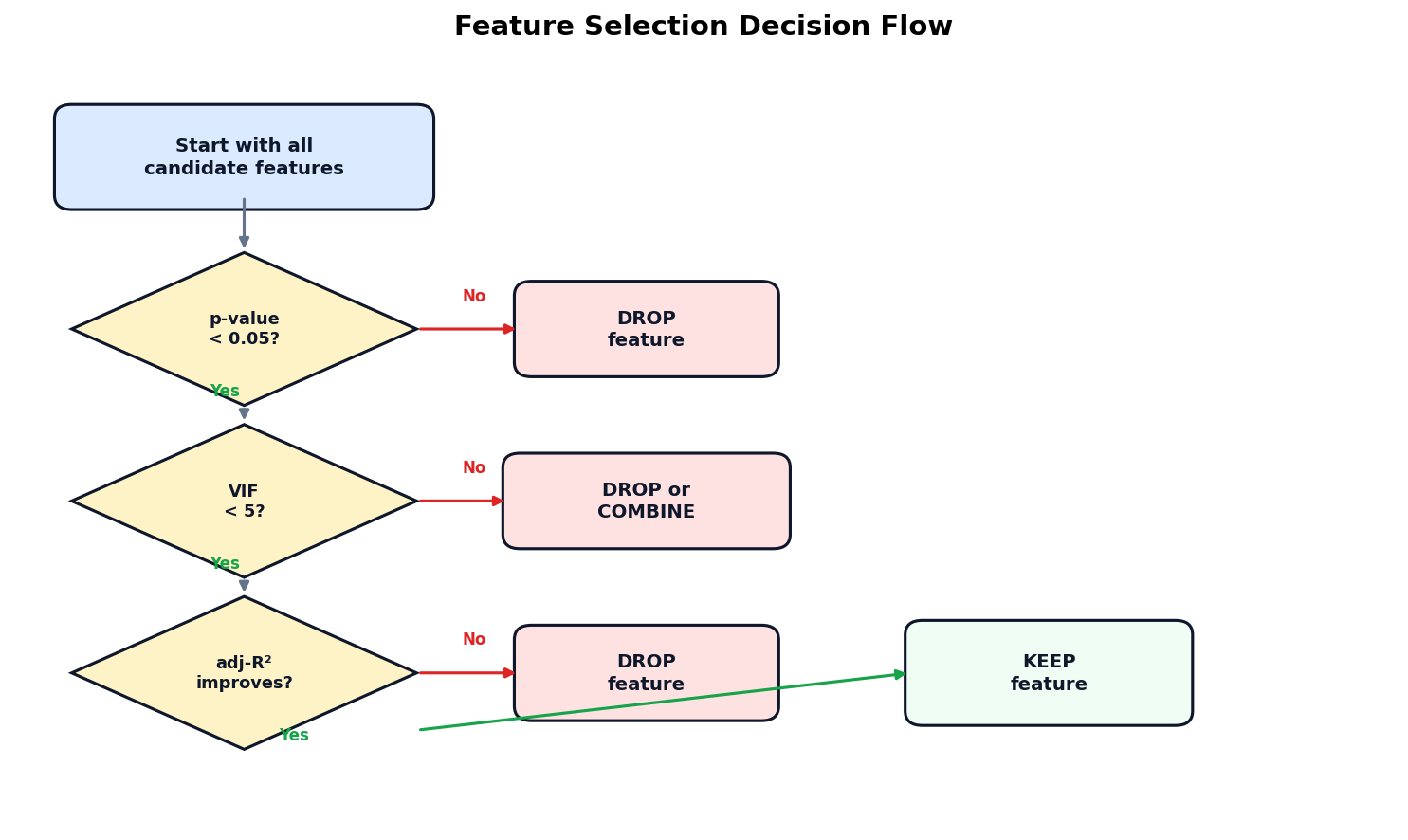
Feature Selection: Which Predictors Earn Their Place?
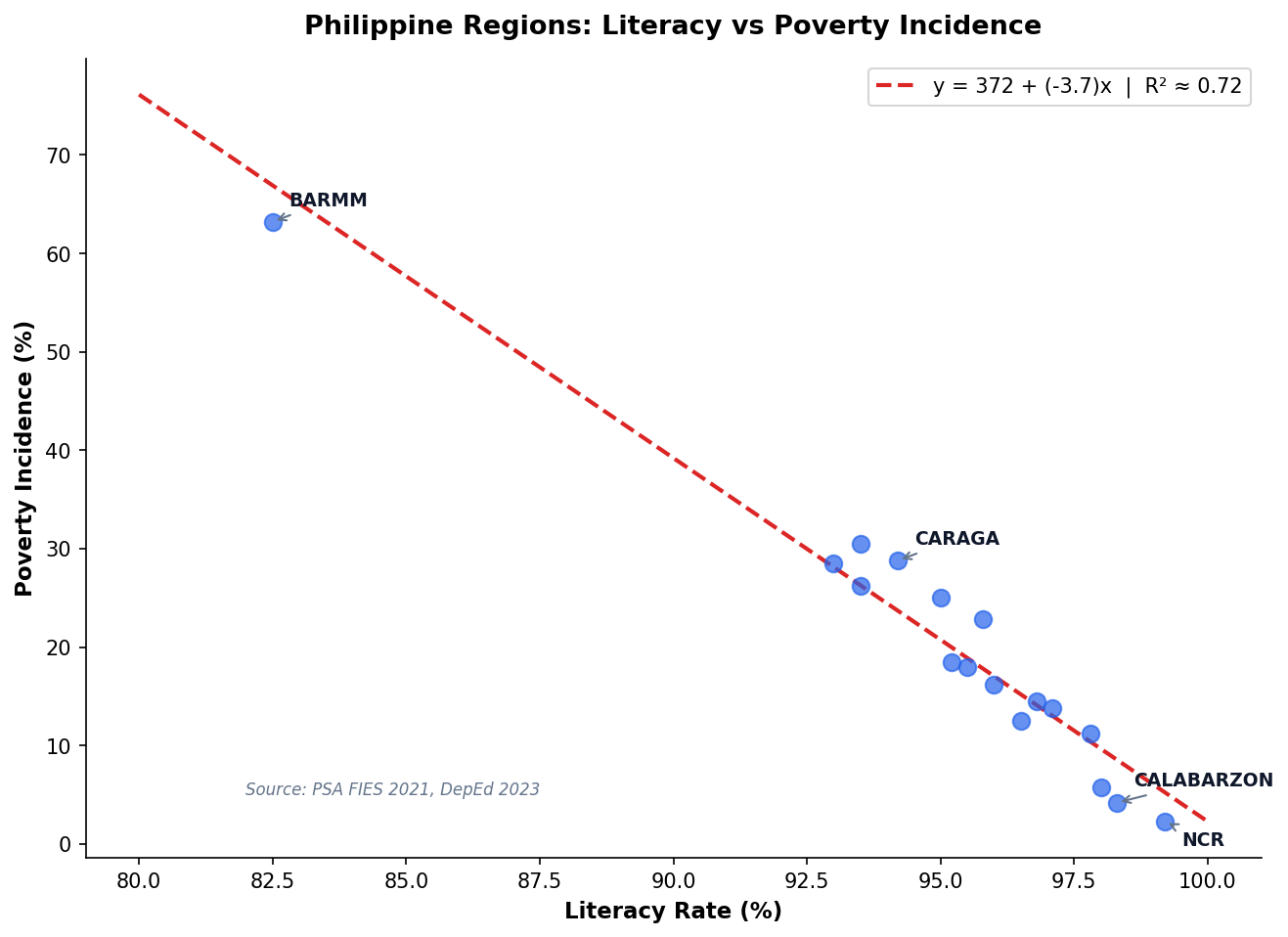
Philippine Regional Poverty: A Regression Case Study
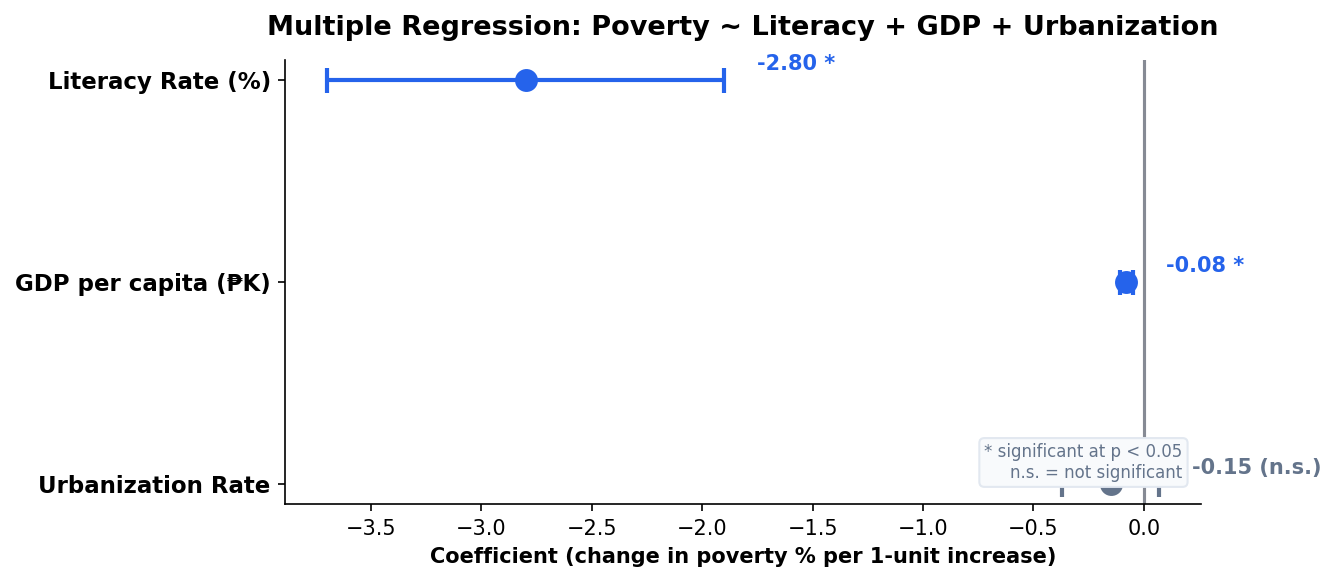
Multiple Predictors Paint a Richer Picture
Adding GDP per capita and urbanization rate to the literacy model:
| Predictor | Coeff. | Note |
|---|---|---|
| Literacy Rate | −2.80* | Strongest predictor |
| GDP per capita | −0.08* | Significant but small effect |
| Urbanization | −0.15 | Not significant after controlling for GDP |
Key Insight
Urbanization becomes non-significant once GDP is in the model — suggesting urbanization’s effect on poverty operates through economic output, not independently.
Diagnostics for the Poverty Model
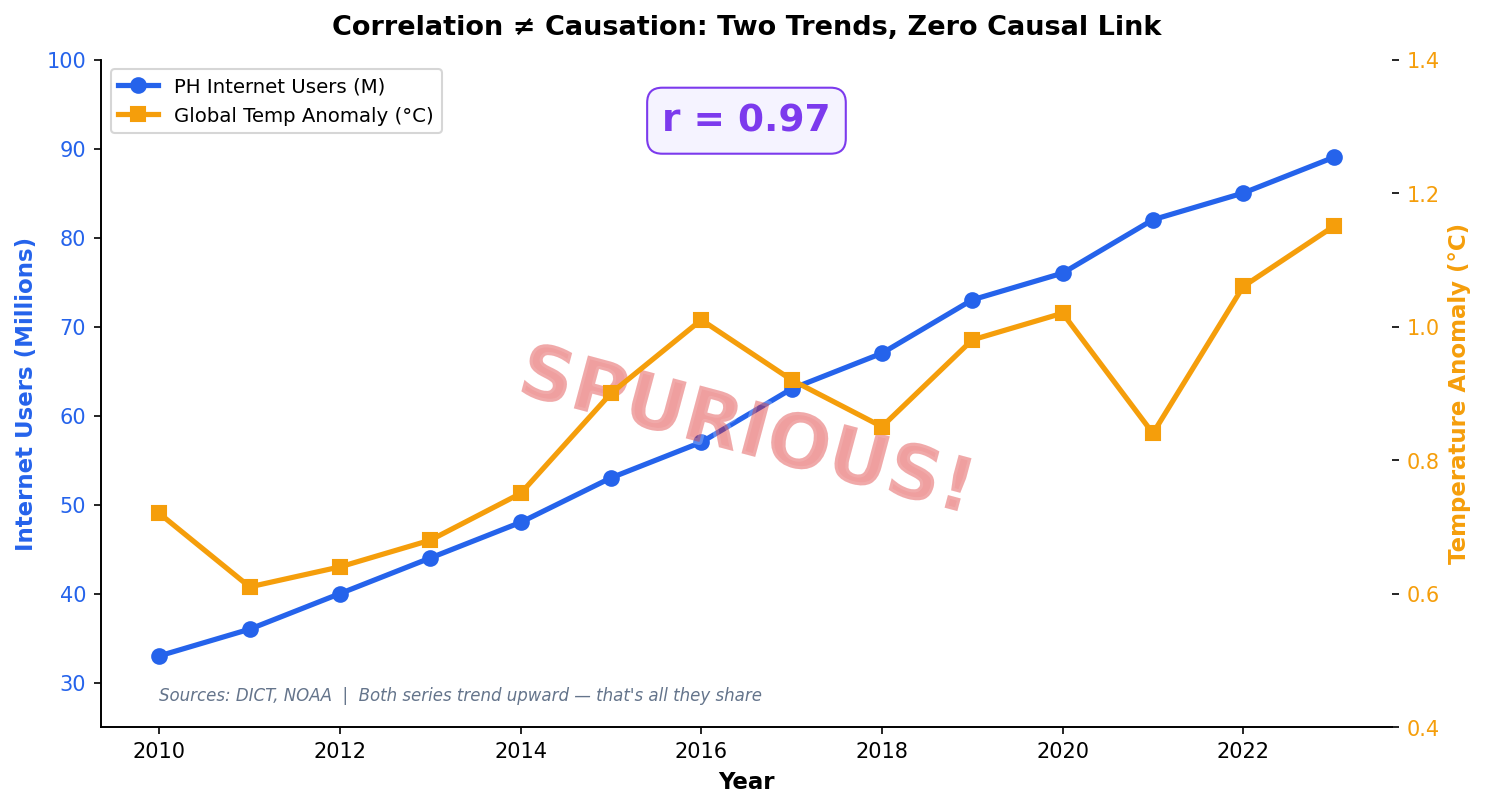
Correlation Does Not Imply Causation
A regression coefficient tells you that X and Y move together after controlling for other variables. It does not tell you that X causes Y.
When Can We Claim Causation?
Randomized controlled trials, natural experiments, or instrumental variables. Observational regression alone — no matter how high the R² — cannot prove causation.
The Analyst’s Responsibility
Always use language like “associated with” or “predicts,” never “causes” or “leads to,” when reporting regression results from observational data.
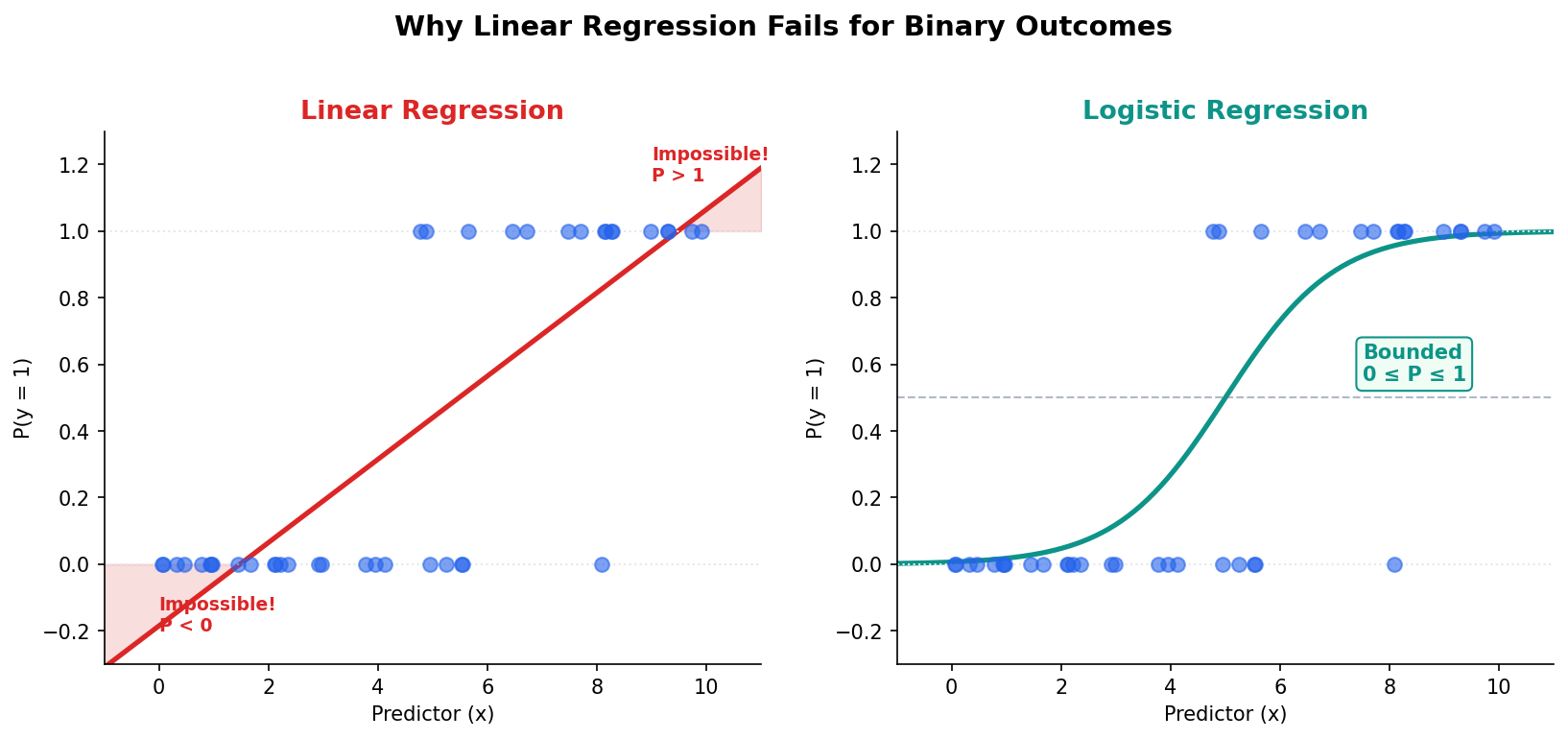
Linear Regression Cannot Predict Probabilities
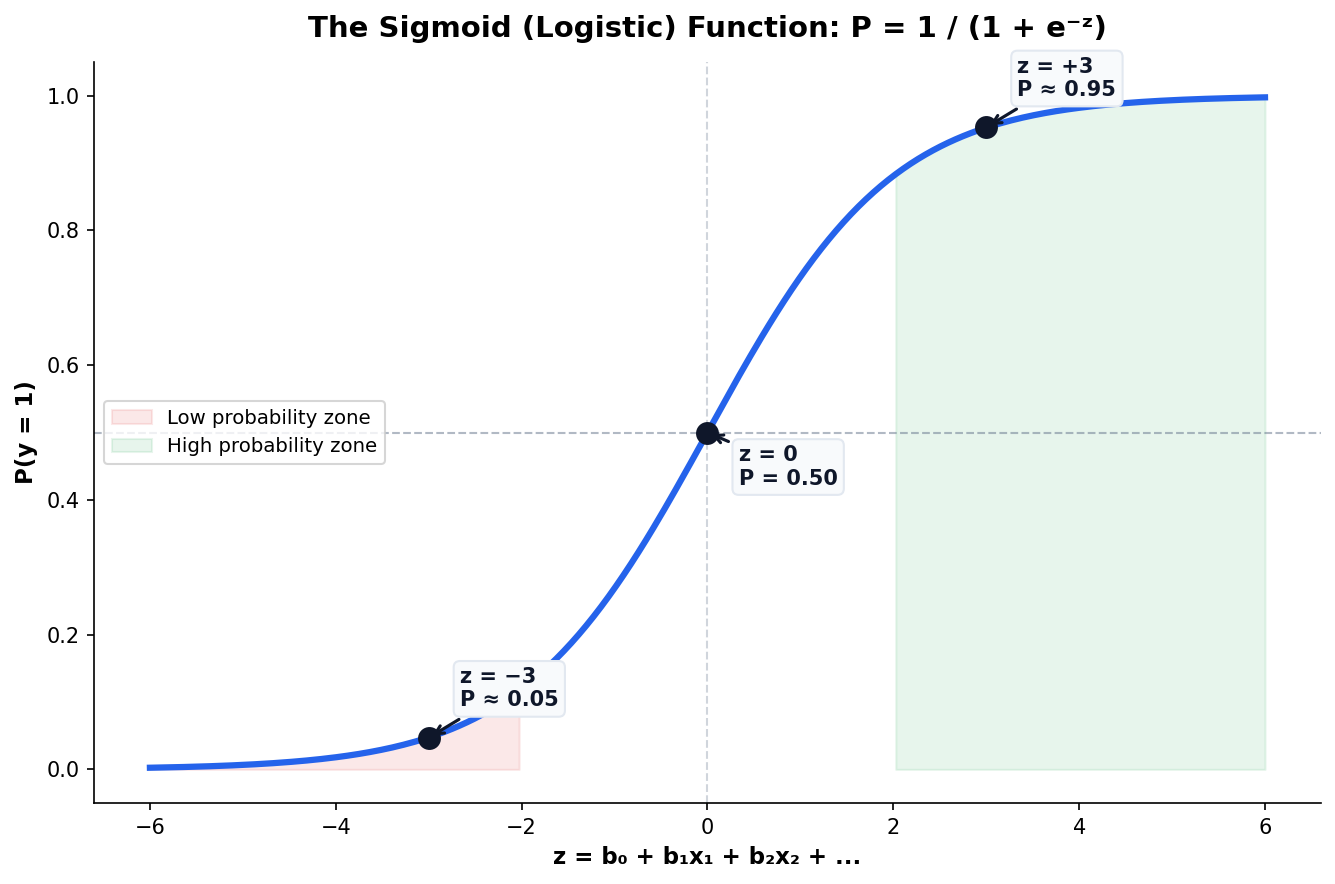
The Sigmoid Curve Maps Any Score to a Probability
The logistic function transforms any real-valued score z into a probability P between 0 and 1. The S-shape ensures smooth transitions near the decision boundary.
Why Sigmoid?
Natural for binary outcomes: as evidence increases, probability approaches 1 asymptotically but never exceeds it.
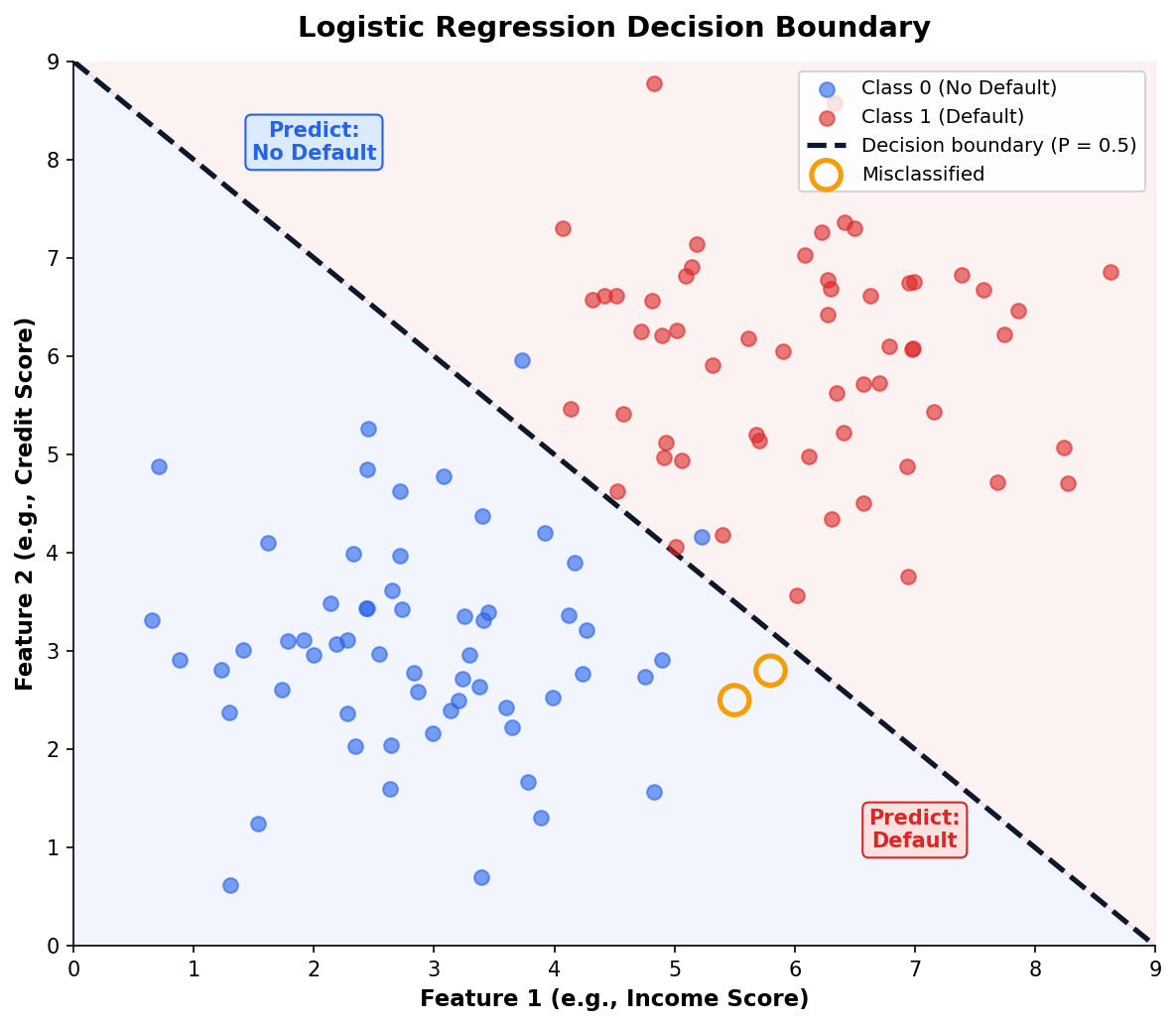
The Decision Boundary
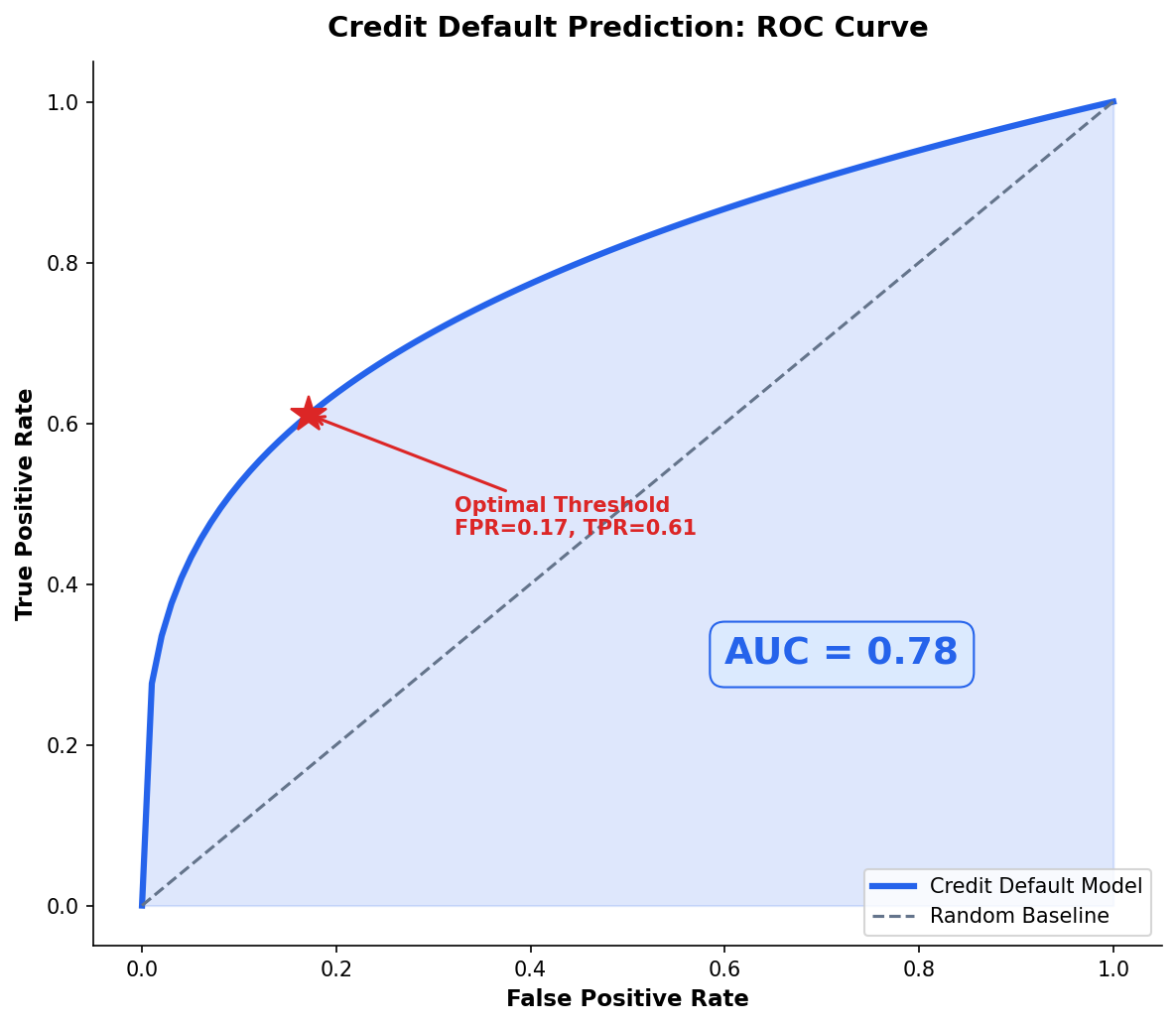
Where P crosses 0.5 is the default classification threshold — but it’s rarely the optimal one for real problems.
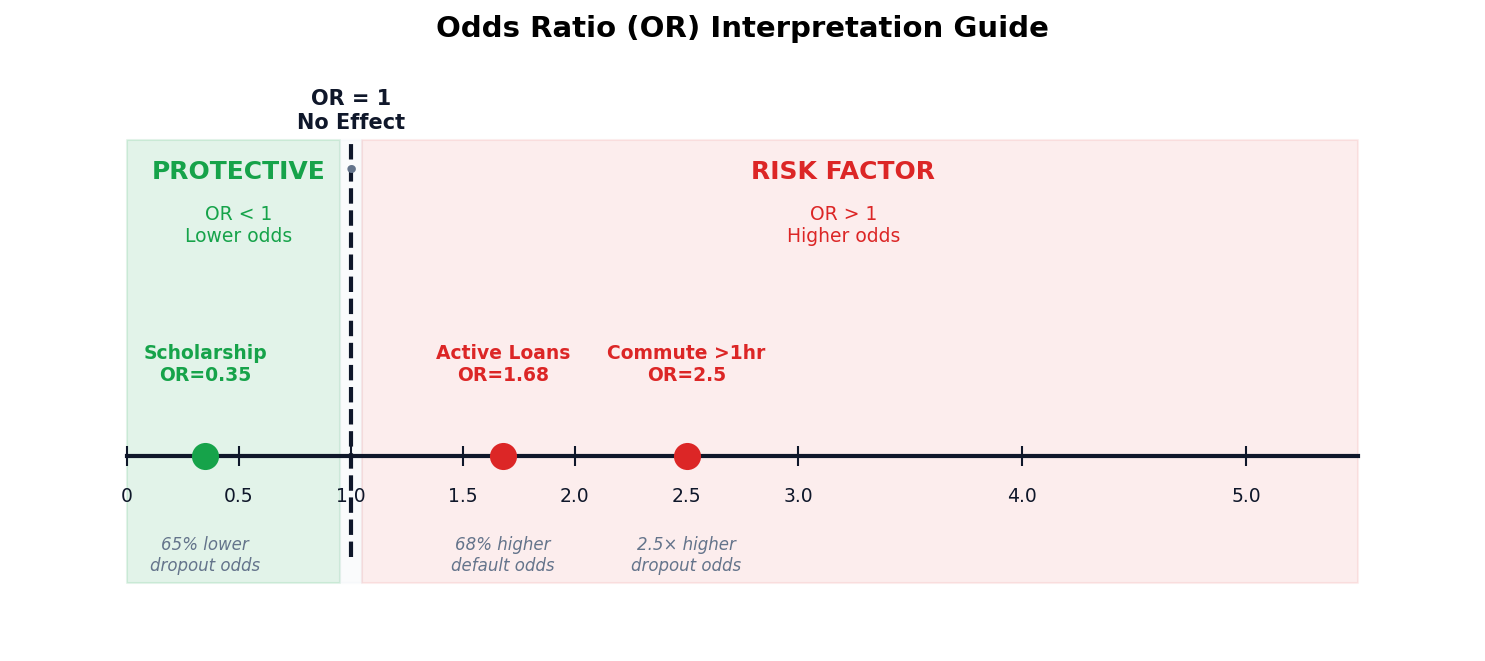
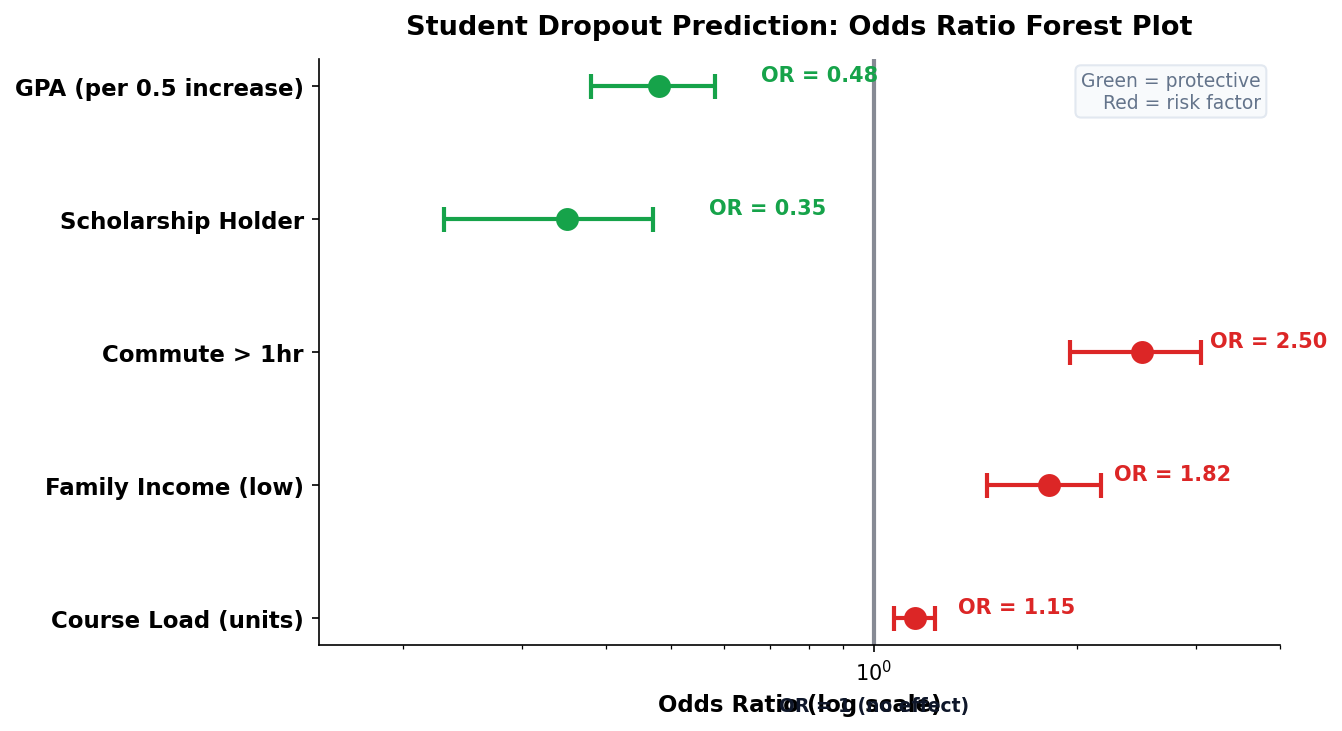
Odds Ratios Make Coefficients Interpretable
In logistic regression, we exponentiate the coefficient (e𝗛) to get the odds ratio. This tells stakeholders how much the odds change per unit increase in the predictor.
How to Read Odds Ratios
OR = 1: no effect. OR > 1: increases odds. OR < 1: decreases odds. OR = 2.5 means the odds are 2.5× higher for a 1-unit increase.
Example
A scholarship holder has OR = 0.35 for dropout — meaning 65% lower odds of dropping out compared to non-scholarship students.
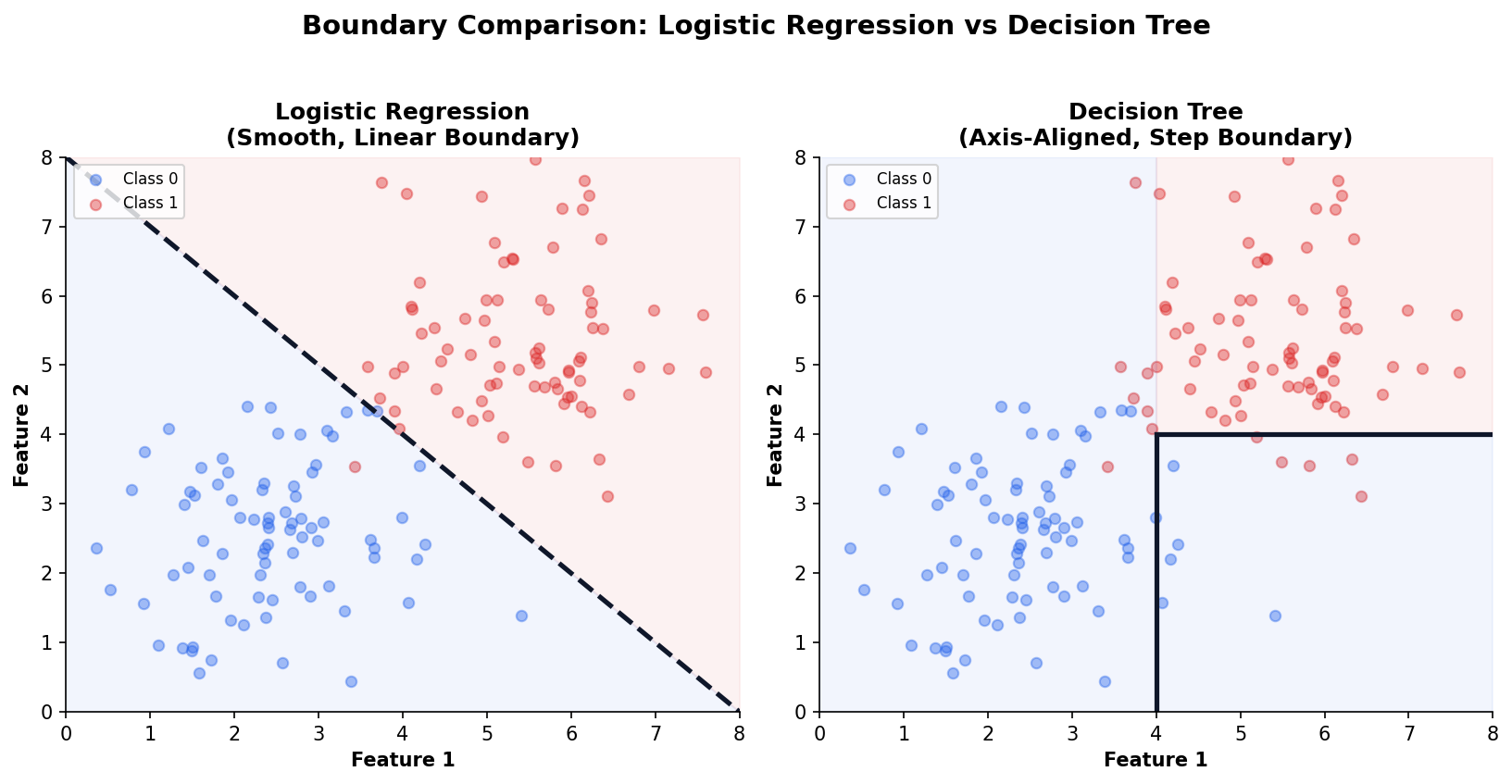
Decision Boundaries Separate the Outcomes
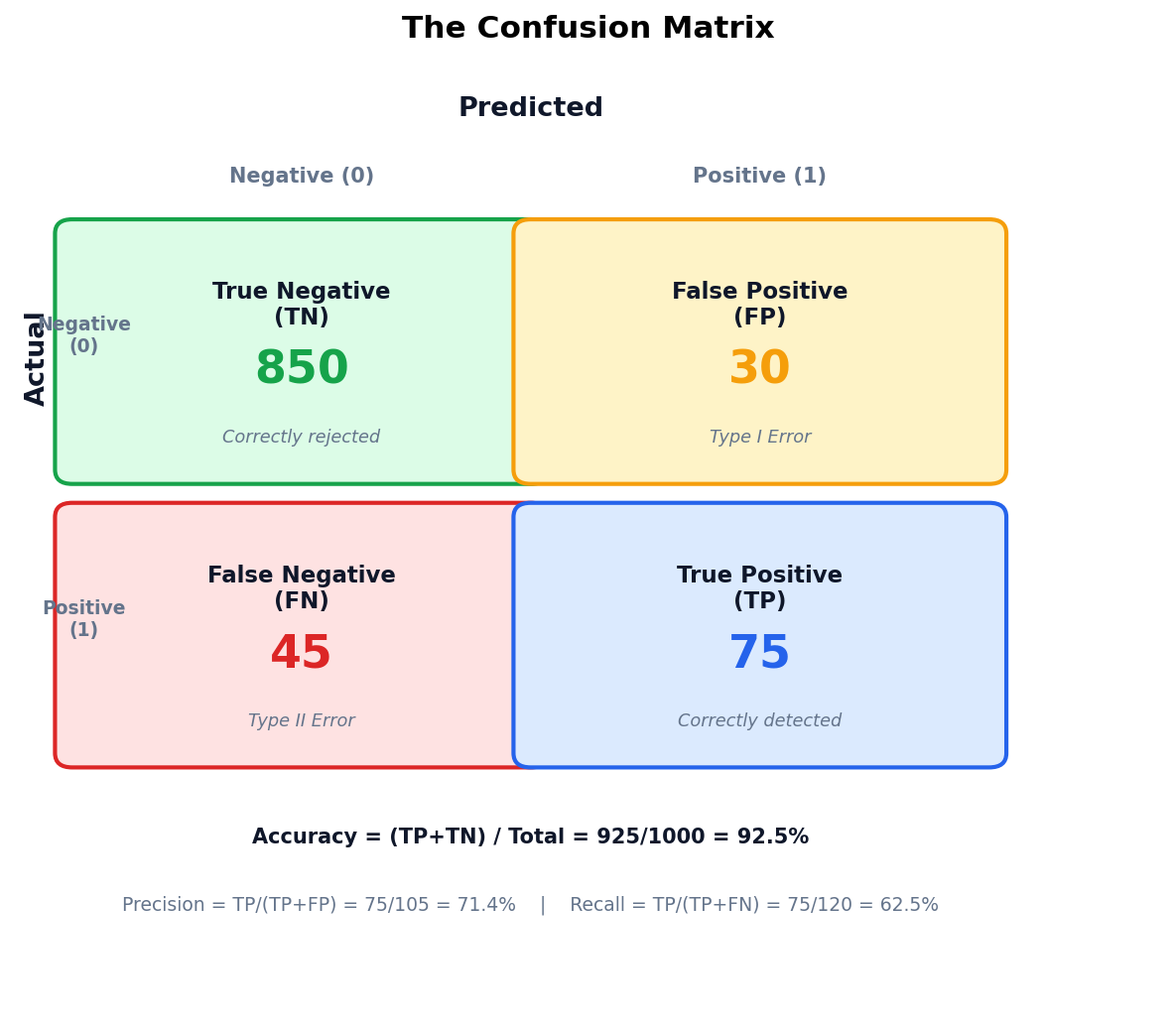
The Confusion Matrix: Every Classifier’s Report Card
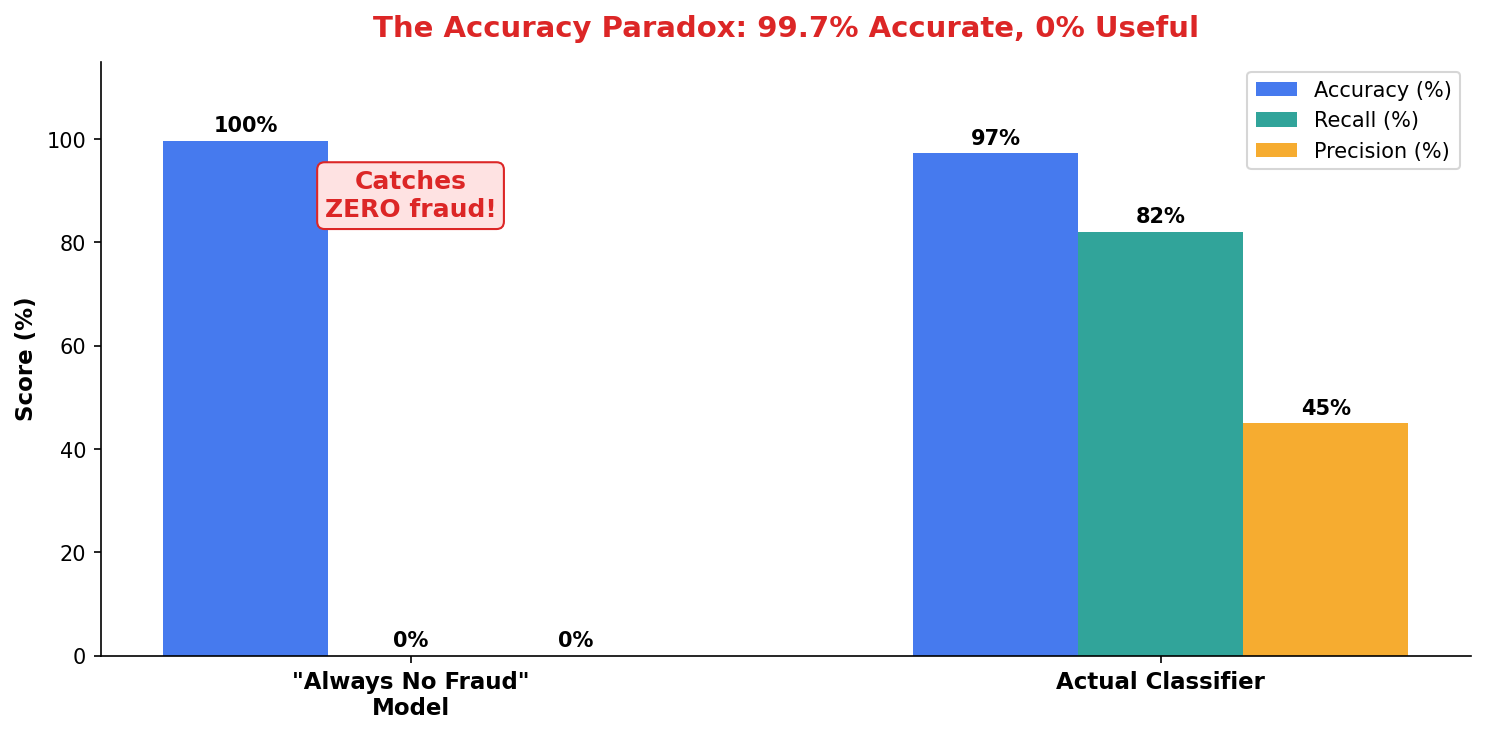
Accuracy Misleads When Classes Are Imbalanced
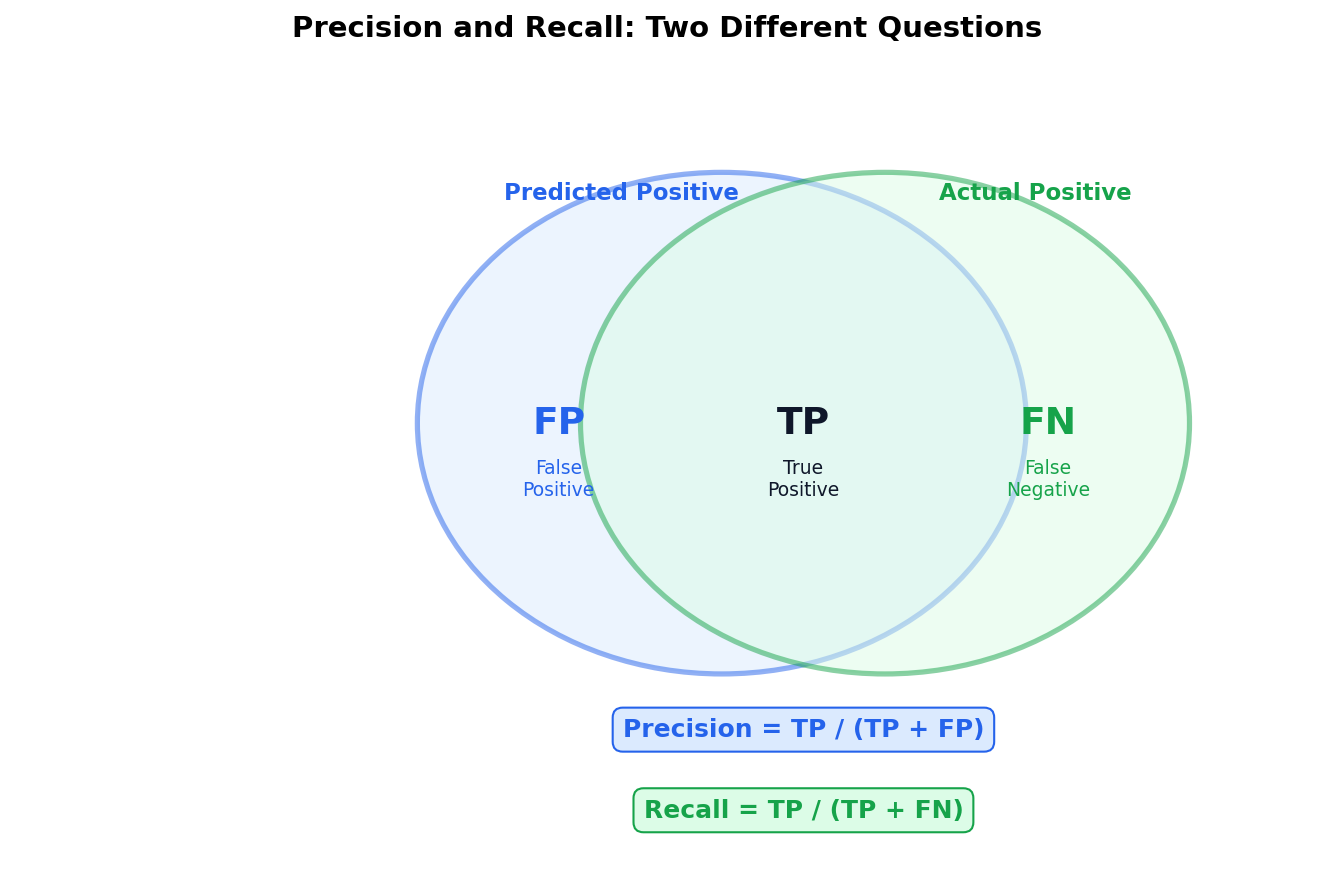
Precision and Recall Answer Different Questions
Precision asks: “Of everything I flagged, how much was correct?” Recall asks: “Of everything that was positive, how much did I catch?”
Spam filter — don’t block legitimate email. Cost of FP > cost of FN.
Disease screening — don’t miss sick patients. Cost of FN > cost of FP.
F1 Score
Harmonic mean of precision and recall. Use when you need to balance both and can’t afford to optimize one at the expense of the other.
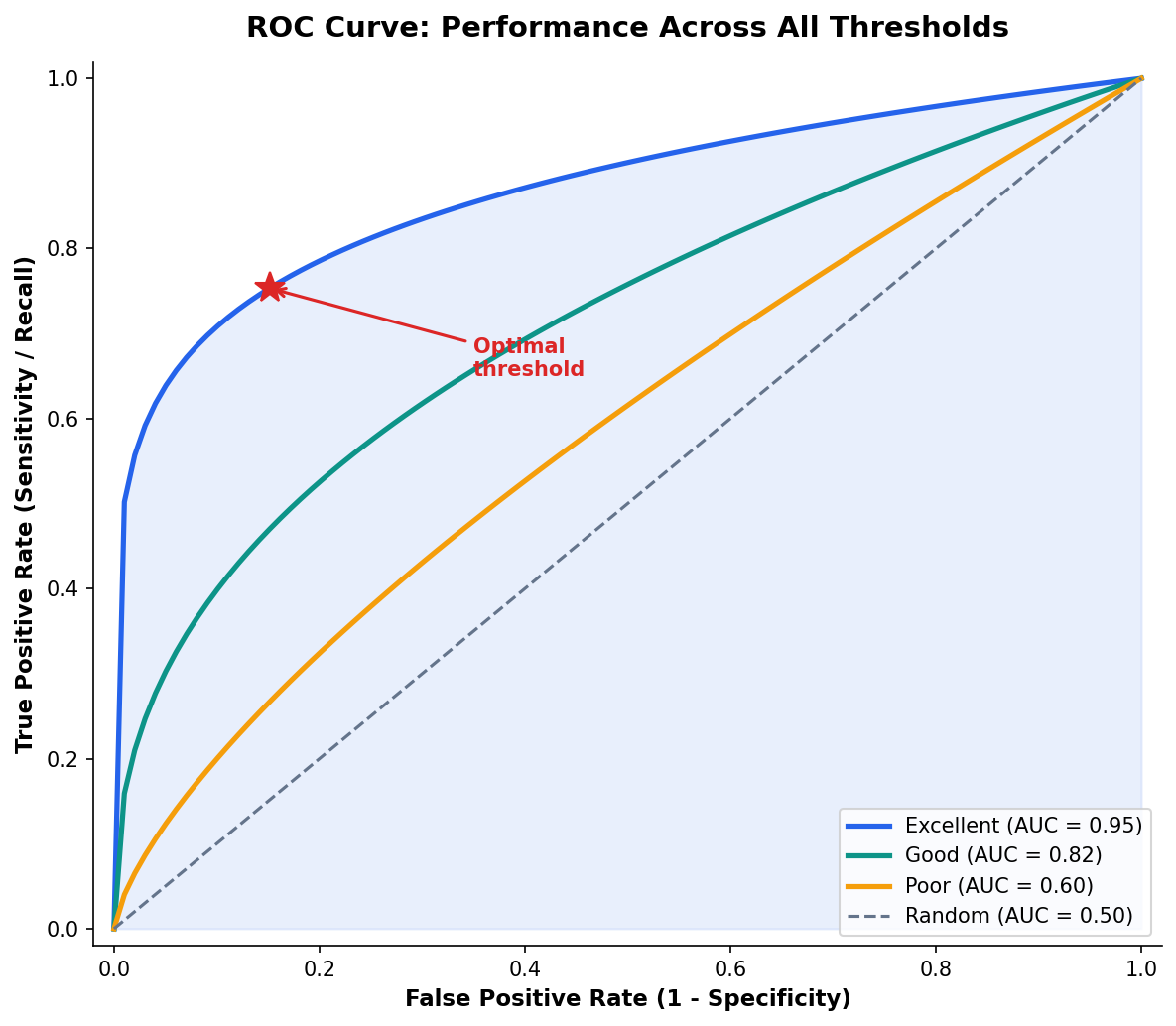
The ROC Curve Summarizes Performance Across All Thresholds
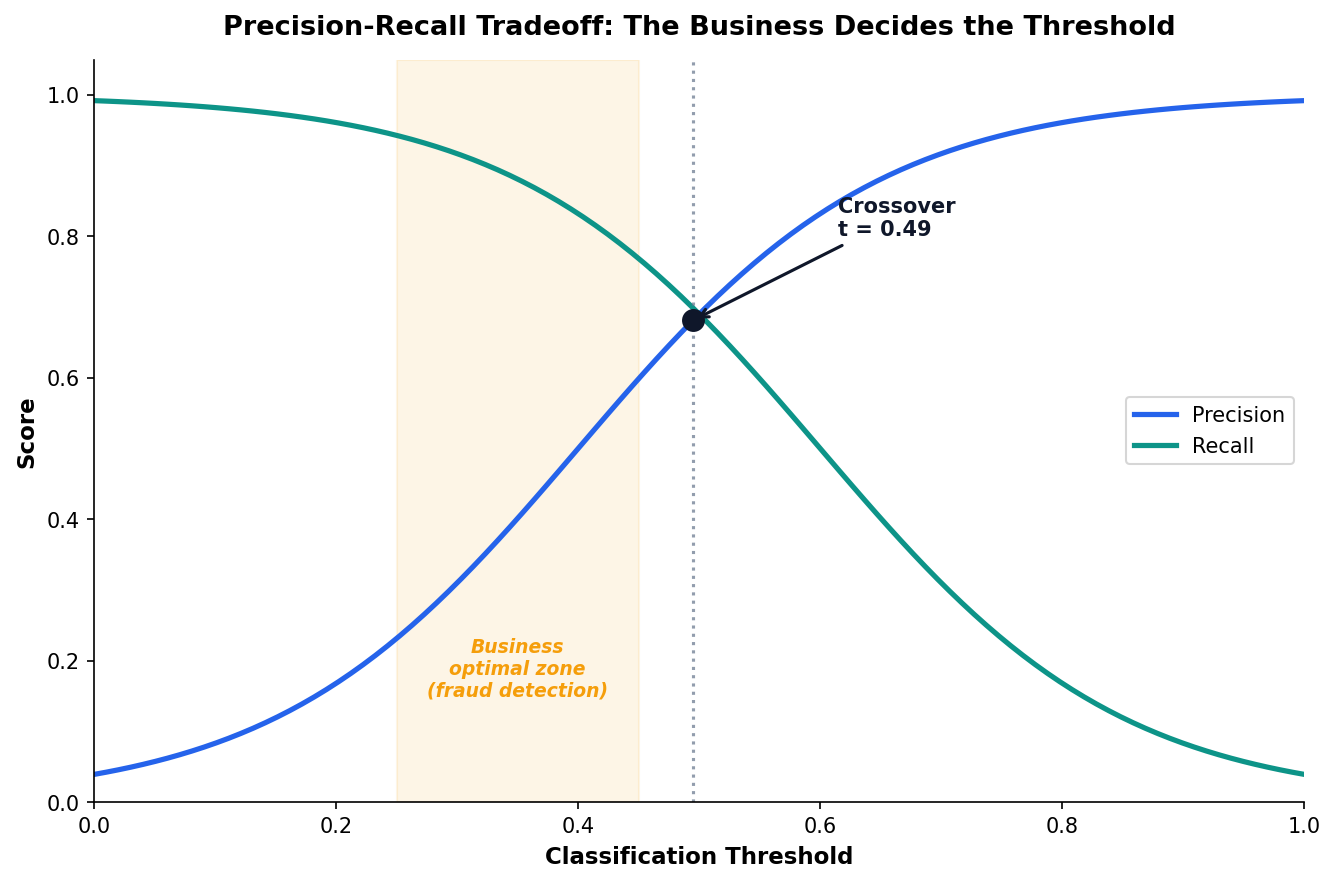
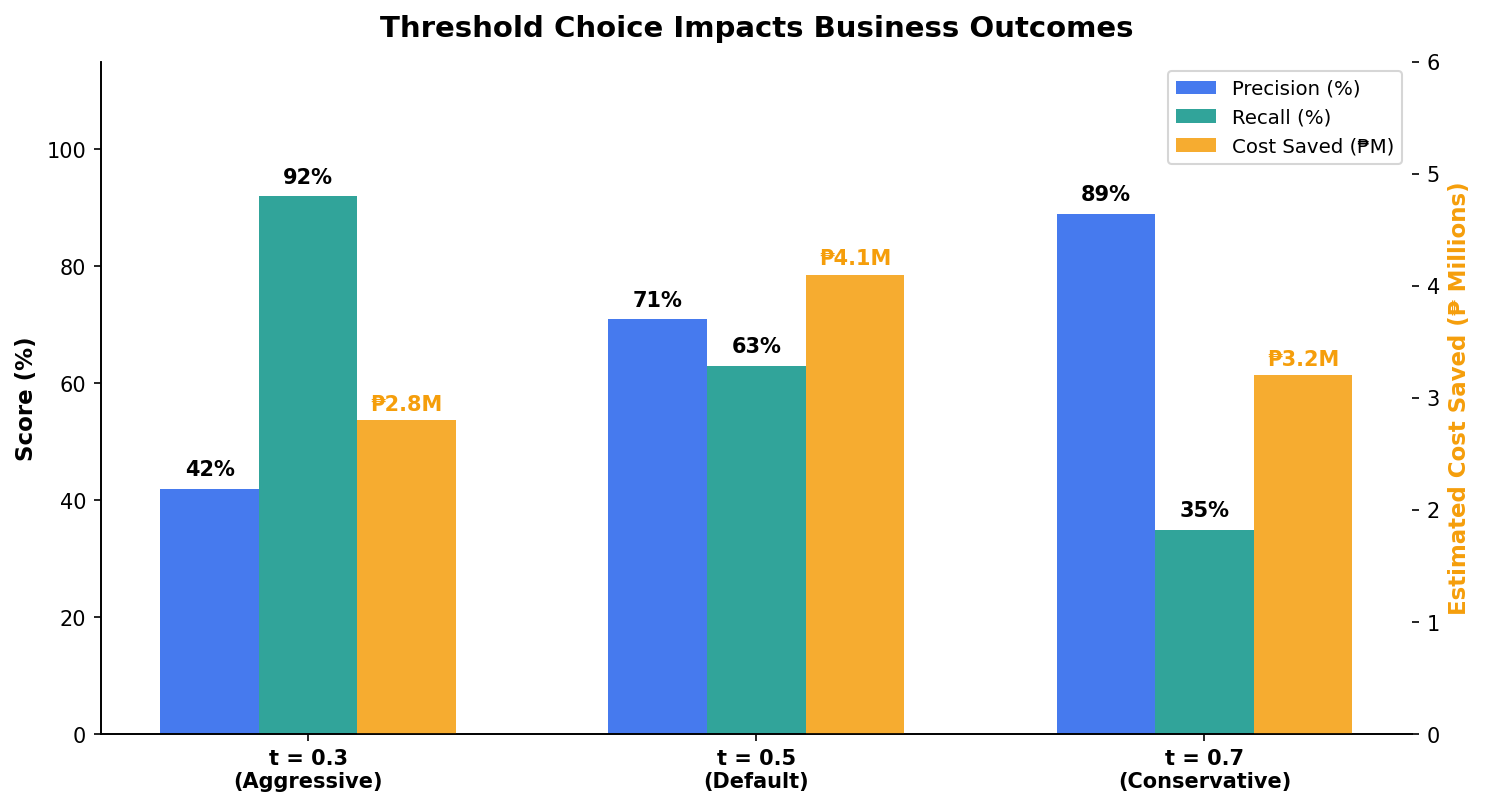
Threshold Tuning: The Business Decides, Not the Algorithm
Predicting Student Dropout: A UP Cebu Scenario
Credit Default Prediction for Philippine Lenders
BSP-regulated consumer lending (GCash GLoan, Bayad Center) requires explainable models per BSP Circular 855.
| Feature | OR | Interpretation |
|---|---|---|
| Monthly Income | 0.62 | Higher income → lower default odds |
| Outstanding Balance | 1.45 | Higher balance → higher risk |
| Employment Length | 0.78 | Longer tenure → lower risk |
| Active Loans | 1.68 | More loans → 68% higher default odds |
Regulatory Context
BSP requires that lending models be explainable to regulators and consumers. Logistic regression’s odds ratios satisfy this requirement directly.
From Odds Ratios to Actionable Recommendations
The analyst’s job: translate OR = 1.68 into “every additional active loan increases default risk by 68%.”
Decision Matrix
Low risk (P < 0.3): auto-approve. Medium (0.3–0.7): manual review. High (P > 0.7): auto-reject. Thresholds set by business, not by data science.
The Deliverable
A stakeholder-ready table mapping model output to business actions — not a confusion matrix.
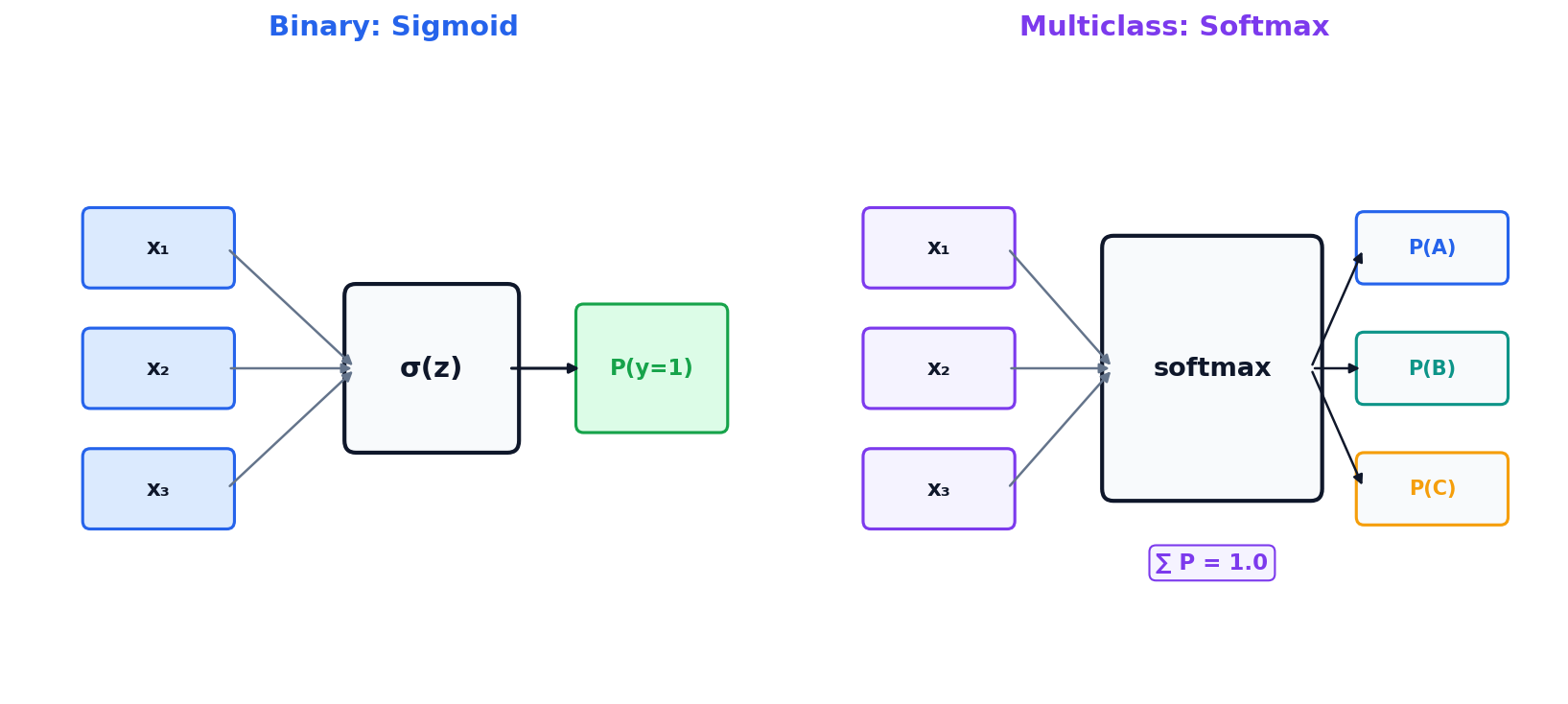
Multiclass Extension: Softmax Regression
When the outcome has more than two categories (e.g., customer segment A/B/C), the sigmoid extends to softmax — one probability per class, summing to 1.
Brief Mention
If you have 3+ classes, use softmax. For most analytics use cases, binary logistic regression covers the majority of decision problems.
Week 8 Preview
Decision trees handle multiclass naturally and don’t require the linearity assumption. Next week we explore when trees beat regression.
Logistic Regression vs Decision Trees: When to Use Which
Both can classify. The choice depends on your data and your audience.
| Criterion | Logistic Regression | Decision Tree |
|---|---|---|
| Interpretability | Coefficients + OR | If-then rules |
| Feature Types | Numeric (needs encoding) | Numeric + categorical natively |
| Linearity | Assumes linear log-odds | No linearity assumption |
| Interactions | Must add manually | Discovers automatically |
| Speed | Very fast | Fast (slower for ensembles) |
Preview
Next week we explore decision trees, random forests, and gradient boosting — and when they outperform logistic regression.