Pre-Pruning: Stop Before Overfitting
Constrain the tree during training with hyperparameters.
max_depth
Absolute depth limit. Start: 5–10
min_samples_split
Min samples to attempt split. Start: 10–20
min_samples_leaf
Min samples for a valid leaf. Start: 5–10
max_features
Max features per split. Start: ‘sqrt’
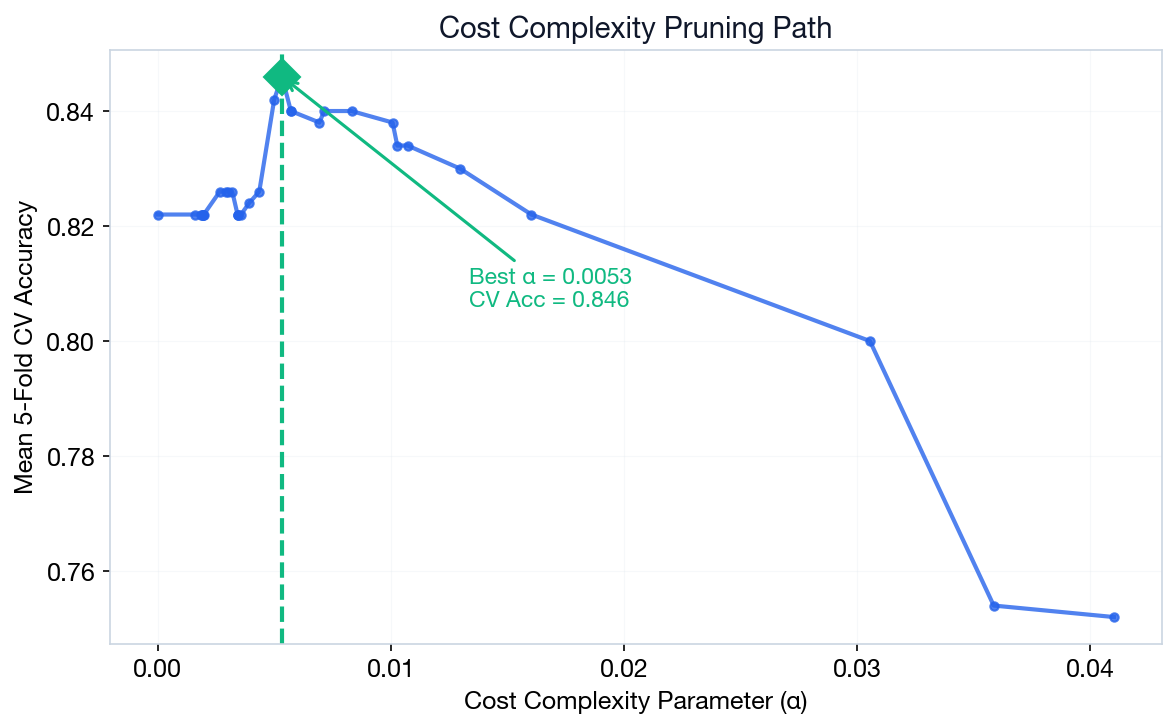
Post-Pruning: Cost Complexity
Grow a full tree, then prune branches that don't improve generalization.
Rα(T) = R(T) + α|T|
- R(T) — Misclassification rate (e.g., 0.15 = 15% errors)
- |T| — Number of leaf nodes (e.g., 8 leaves)
- α — Penalty per leaf. α=0 means no penalty (full tree). Higher α = simpler tree
Example: R(T)=0.15, |T|=8, α=0.01 → Cost = 0.15 + 0.01×8 = 0.23.
Prune to 4 leaves: R(T)=0.18, Cost = 0.18 + 0.01×4 = 0.22 (lower → prune!)
CS Connection: The α parameter is like weight decay (L2 regularization) in neural networks — it penalizes model complexity. Higher α = simpler tree, just like higher λ = smaller weights.
Regression Trees
Same tree structure, but leaf values are means instead of class labels. Splits minimize MSE within each partition.
Classification: leaf = majority class vote.
Regression: leaf = mean of training samples in
that partition.
Example: A leaf contains 5 houses priced at: ₱2M, 2.5M, 3M, 2.8M, 2.2M
Prediction = mean = (2 + 2.5 + 3 + 2.8 + 2.2) / 5 = ₱2.5M
MSE: CART finds the cut that minimizes price variance in each child group. Lower variance = more similar houses grouped together.
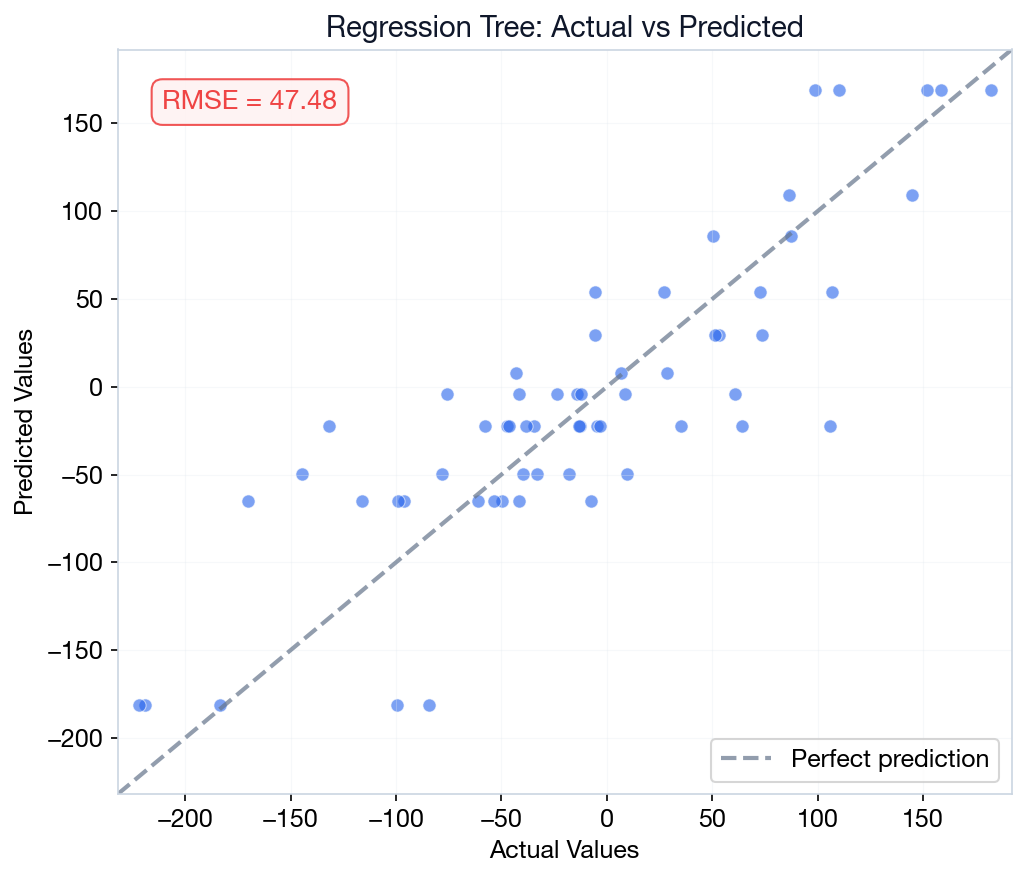
Trees cannot extrapolate. If training house prices range ₱1M–₱5M, the tree will never predict ₱6M. Leaf values are always within the training range. This is a fundamental limitation vs. linear models or neural networks.
Random Forest in Python
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(
n_estimators=200, # 200 trees
max_features='sqrt', # sqrt(p) features/split
oob_score=True, # free validation
n_jobs=-1, # all CPU cores
random_state=42
)
rf.fit(X_train, y_train)
print(f"OOB Score: {rf.oob_score_:.3f}")Output: OOB converges around 0.92 (see right). Diminishing returns after ~200 trees.
Key Parameters to Tune
| Parameter | Default | Recommended Range |
|---|---|---|
n_estimators | 100 | 200–500 (more is safe, just slower) |
max_depth | None (full) | 10–30 or None |
max_features | 'sqrt' | 'sqrt' (classification), 0.33 (regression) |
min_samples_leaf | 1 | 5–20 (reduces overfitting) |
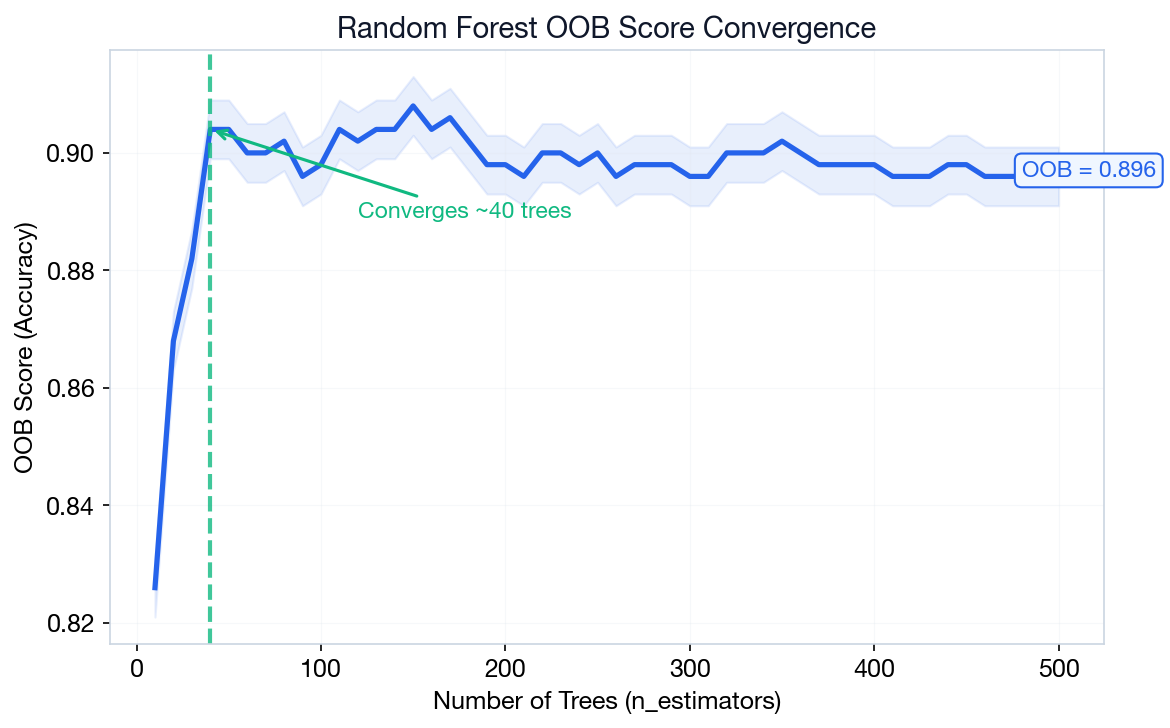
n_jobs=-1 uses all CPU cores — RF is "embarrassingly parallel" since every tree is independent. A 200-tree RF on 8 cores trains ~8× faster.
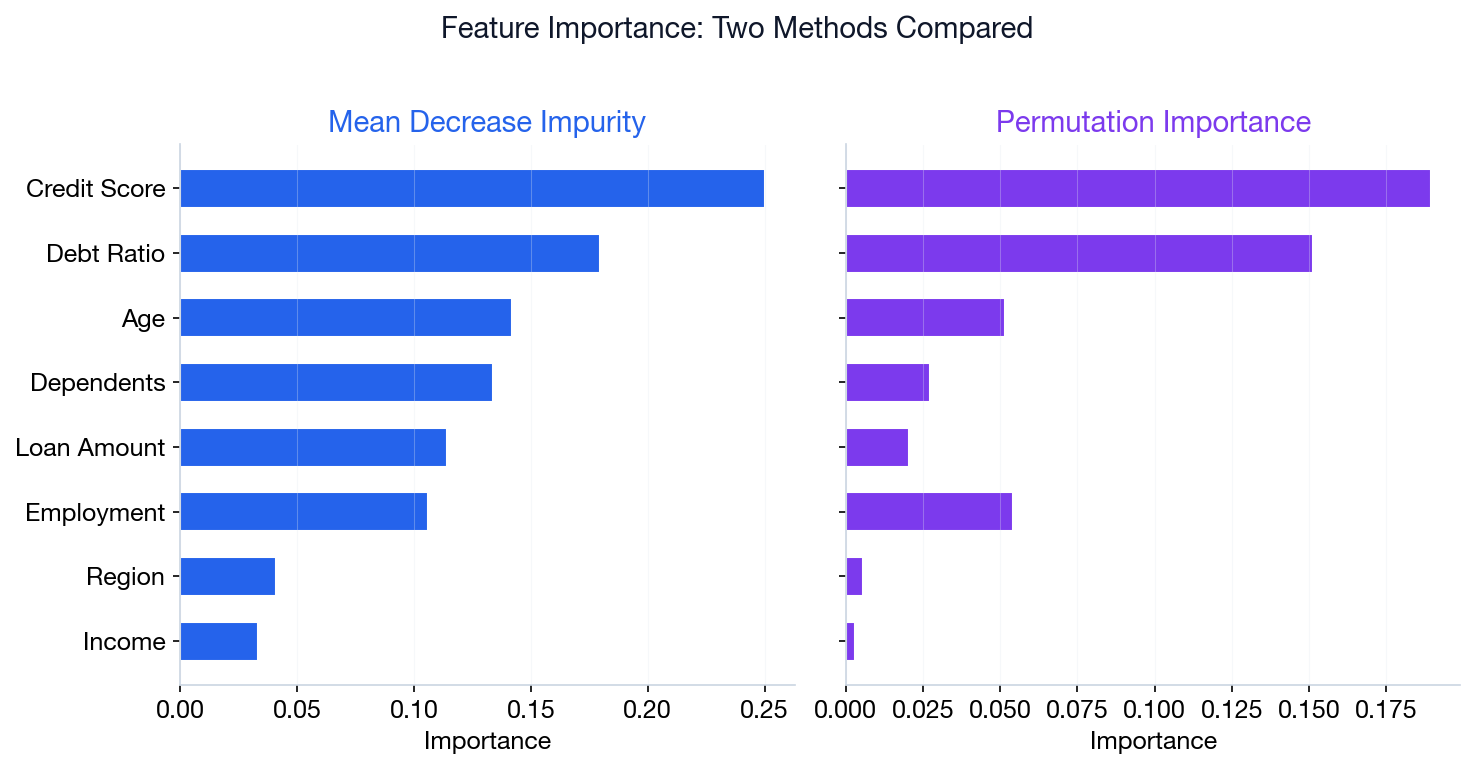
Feature Importance: Two Methods
Mean Decrease Impurity (MDI)
Built-in, fast, but biased toward high-cardinality features (high-cardinality = many unique values, e.g. ZIP codes).
rf.feature_importances_ — sum of Gini decreases across all trees where the feature is used.
Permutation Importance
More reliable. Measures accuracy drop when feature values are shuffled.
permutation_importance(rf, X_test, y_test) — model-agnostic, works with any estimator.
MDI for quick screening during development. Permutation for final reports — it’s unbiased and works on any model, not just trees.
Out-of-Bag (OOB) Error
Each tree is trained on ~63% of data (bootstrap sample). The remaining ~37% can be used as a free validation set.
P(not selected) = (1 − 1/n)n ⟶ 1/e ≈ 0.368
~63.2% in-bag • ~36.8% out-of-bag (free validation)
No need for a separate validation set! OOB score approximates test performance without holding out data.
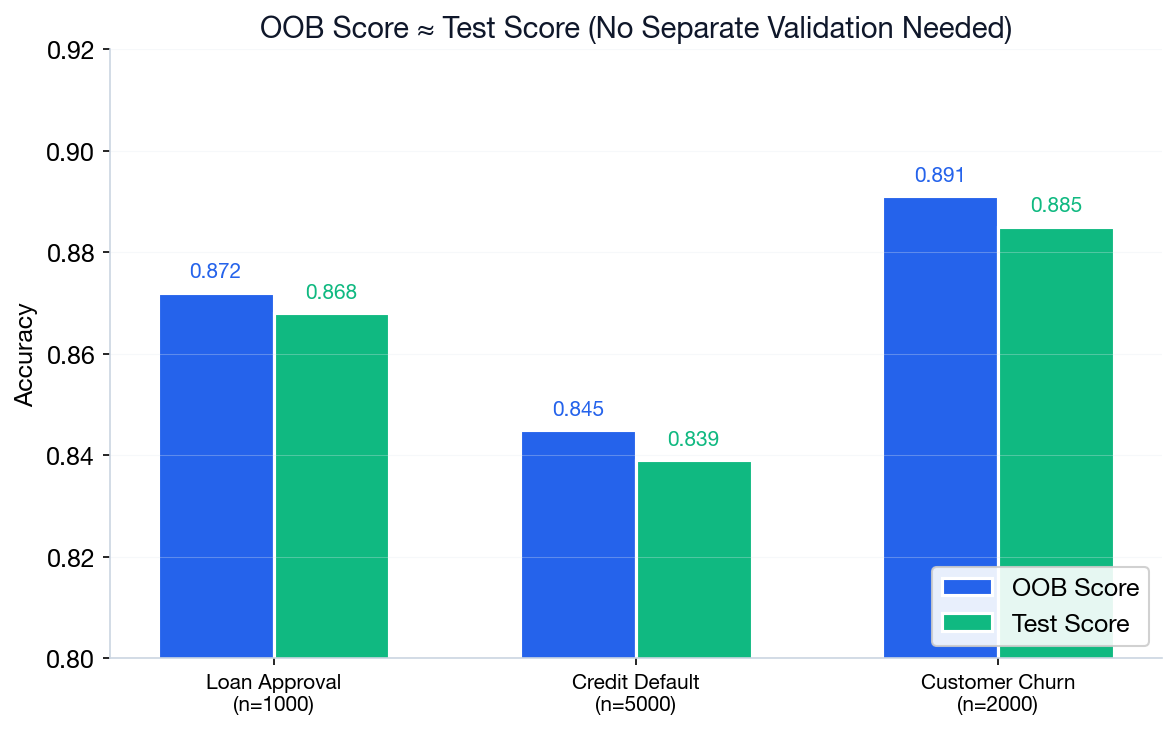
The 63.2% proof: P(sample drawn at least once in n draws) = 1 − (1−1/n)n → 1 − 1/e ≈ 0.632 as n→∞. So ~37% of data is "free" validation per tree. OOB replaces cross-validation, but always keep a separate test set.
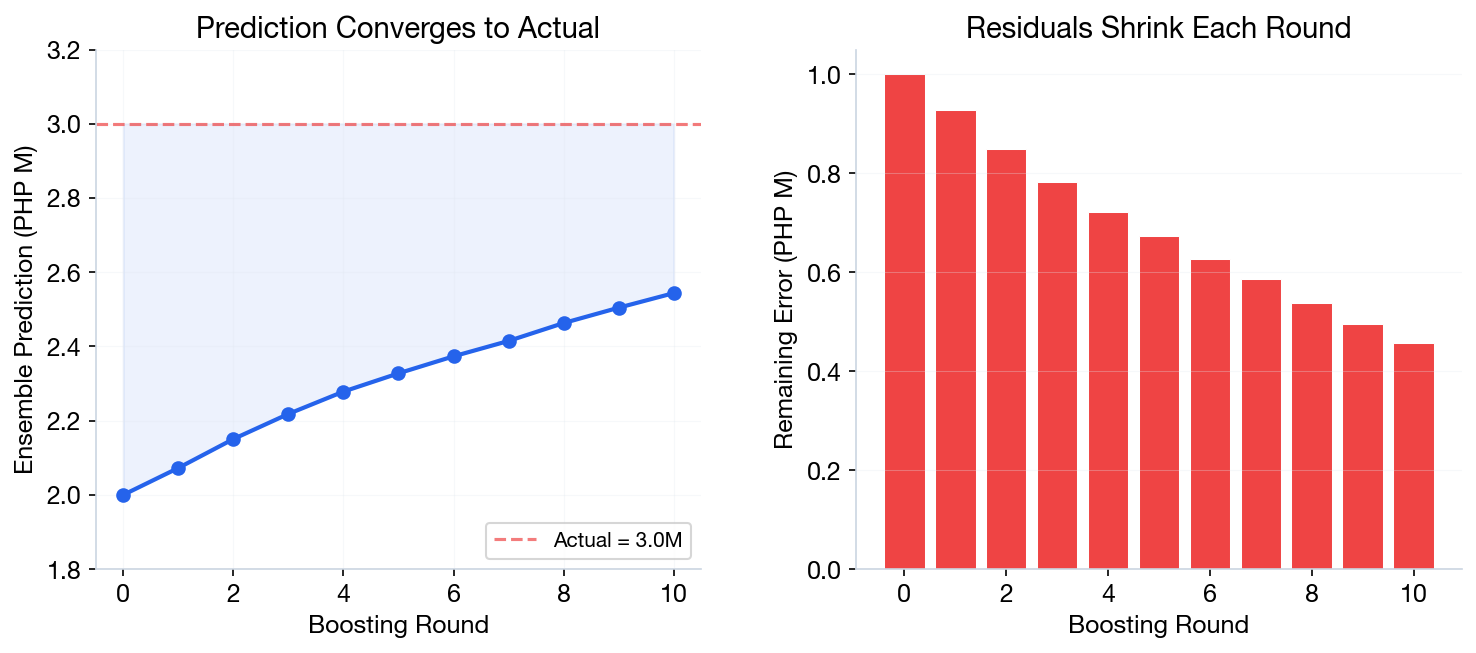
Boosting: Iteration by Iteration
Predicting a house price. Actual = ₱3.0M
| Iter | What Tree Learns | Output | Running Total |
|---|---|---|---|
| 0 | Start: mean of all prices | — | ₱2.0M |
| 1 | Residual: 3.0 − 2.0 = 1.0M | +0.8M | ₱2.8M |
| 2 | Residual: 3.0 − 2.8 = 0.2M | +0.15M | ₱2.95M |
| 3 | Residual: 3.0 − 2.95 = 0.05M | +0.04M | ₱2.99M |
Each tree corrects the remaining error. After just 3 iterations: ₱2.0M → ₱2.99M — almost perfect!
Notice: Output < Residual each round. That gap is the learning rate (γ) — it scales how much each tree contributes. (Defined formally on the next slide.)
Why learning_rate = 0.1 beats 1.0: With lr=1.0, each tree fully corrects errors → memorizes noise in ~10 trees. With lr=0.1, each tree only nudges the prediction by 10% → needs ~100 trees but generalizes better. Same tradeoff as step size in gradient descent.
XGBoost: Extreme Gradient Boosting
Fast, regularized, scalable. The go-to algorithm for Kaggle competitions and production ML on tabular data.
Built-in L1/L2 regularization, early stopping, missing value handling, and parallel tree construction.
Key Hyperparameters
| n_estimators | Number of boosting rounds (100–1000) |
| learning_rate | Step size shrinkage (0.01–0.3) |
| max_depth | Tree depth (3–10, default 6) |
| early_stopping | Stop when validation loss plateaus |
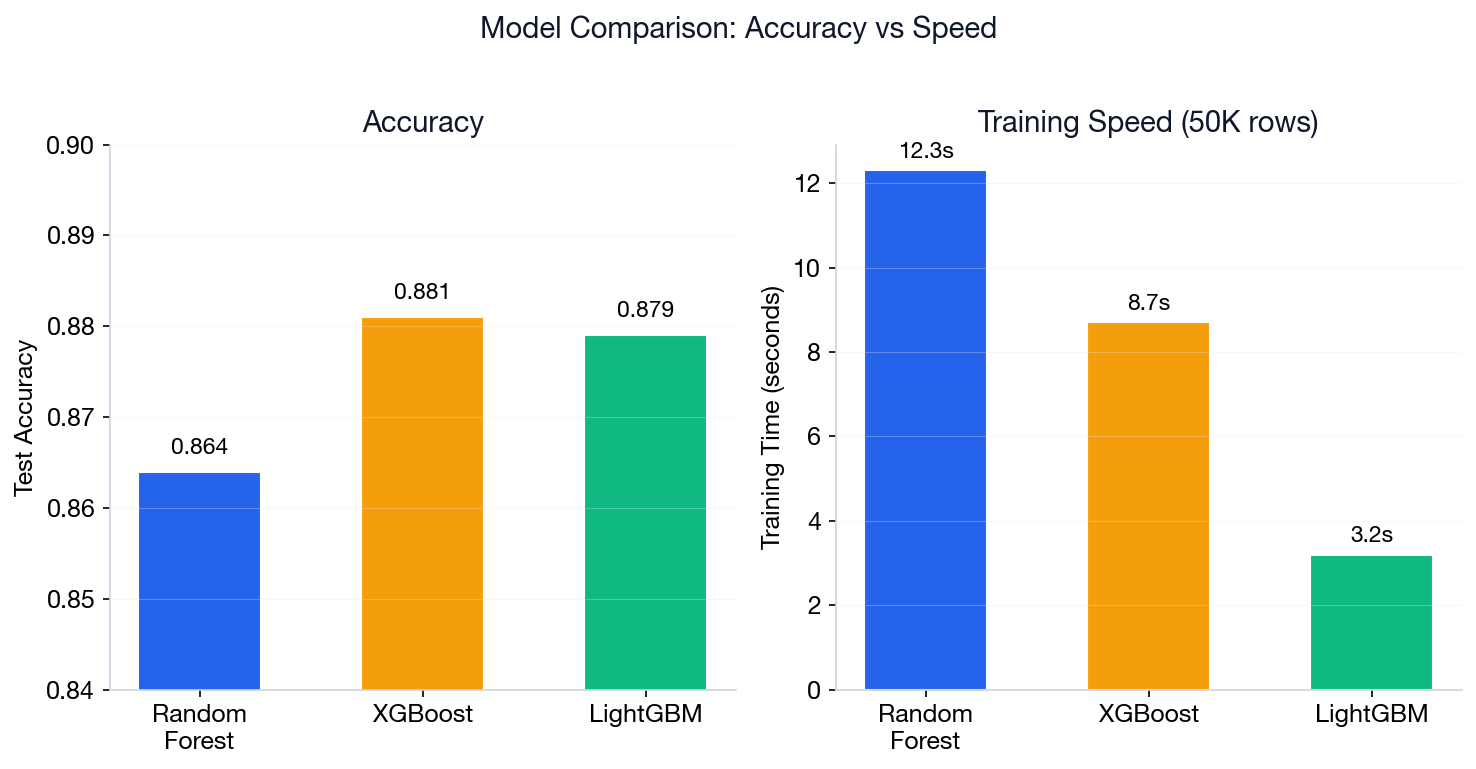
Choose XGBoost when: you need maximum accuracy on tabular data and can invest time in hyperparameter tuning. Use Random Forest when you need a robust model with minimal tuning.
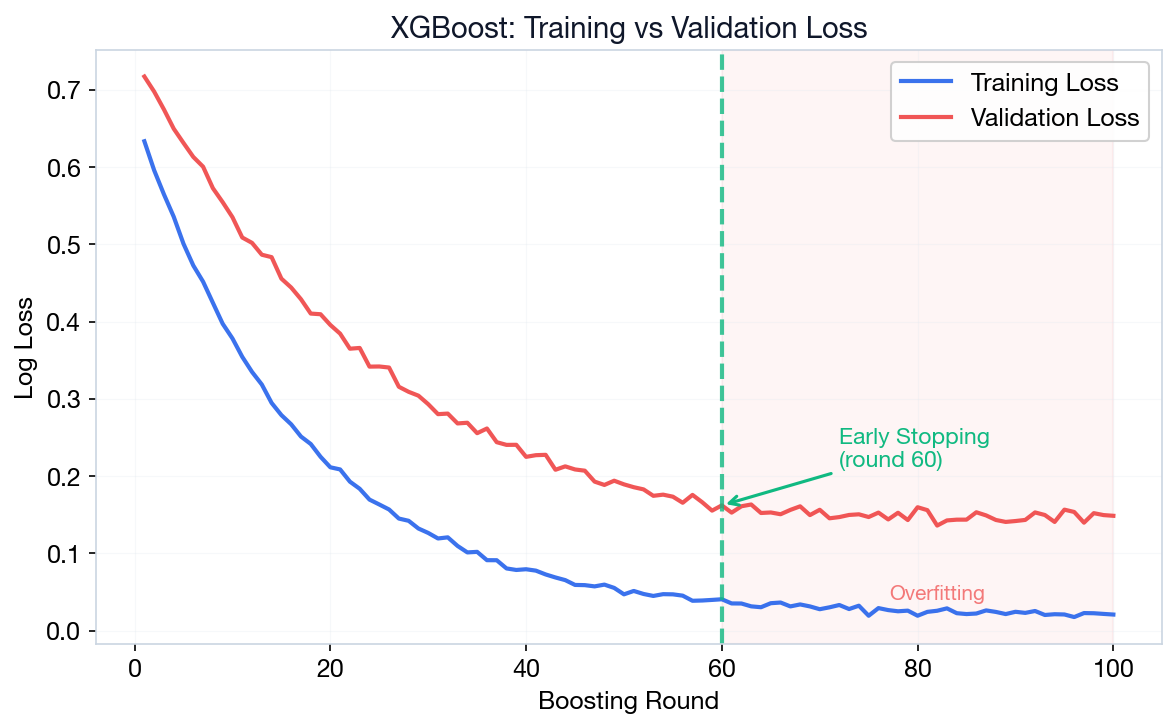
XGBoost: Python Code Example
import xgboost as xgb
model = xgb.XGBClassifier(
n_estimators=200,
max_depth=6,
learning_rate=0.1,
early_stopping_rounds=10,
eval_metric='logloss' # penalizes overconfident wrong predictions
)
model.fit(X_train, y_train,
eval_set=[(X_val, y_val)],
verbose=False)
print(f"Best round: {model.best_iteration}")
print(f"Test acc: {model.score(X_test, y_test):.3f}")Early Stopping = stop training when validation loss stops improving. Prevents overfitting automatically.
logloss = penalizes overconfident wrong predictions (lower = better).
L1 reg = drives small weights to zero (implicit feature selection). L2 reg = shrinks all weights evenly, prevents any one feature dominating.
LightGBM: Light Gradient Boosting
Microsoft's gradient boosting library (2017). Key innovations: leaf-wise growth, histogram binning, GOSS sampling.
import lightgbm as lgb
model = lgb.LGBMClassifier(
n_estimators=200,
num_leaves=31, # main complexity control
learning_rate=0.1,
n_jobs=-1
)
model.fit(X_train, y_train)Key Parameters
| Parameter | Default | Notes |
|---|---|---|
num_leaves | 31 | Main complexity knob (replaces max_depth) |
min_child_samples | 20 | Prevents overfitting on small data |
subsample | 1.0 | Row sampling per tree (0.6–0.9) |
colsample_bytree | 1.0 | Column sampling (like RF) |
3 Key Innovations: (1) Leaf-wise growth = split highest-loss leaf only. (2) Histogram binning = 255 bins instead of exact thresholds (10–100× faster). (3) GOSS = keep high-gradient samples, subsample the rest.
Leaf-wise vs Level-wise: XGBoost grows all nodes at same depth. LightGBM grows the leaf that reduces loss the most — faster convergence, but can overfit on small data (<10K rows).
Hyperparameter Tuning
from sklearn.model_selection import RandomizedSearchCV
param_dist = {
'n_estimators': [100, 200, 300, 500],
'max_depth': [3, 5, 7, 10],
'learning_rate': [0.01, 0.05, 0.1],
}
search = RandomizedSearchCV(
xgb.XGBClassifier(), param_dist,
n_iter=20, cv=5, scoring='roc_auc'
)
search.fit(X_train, y_train)
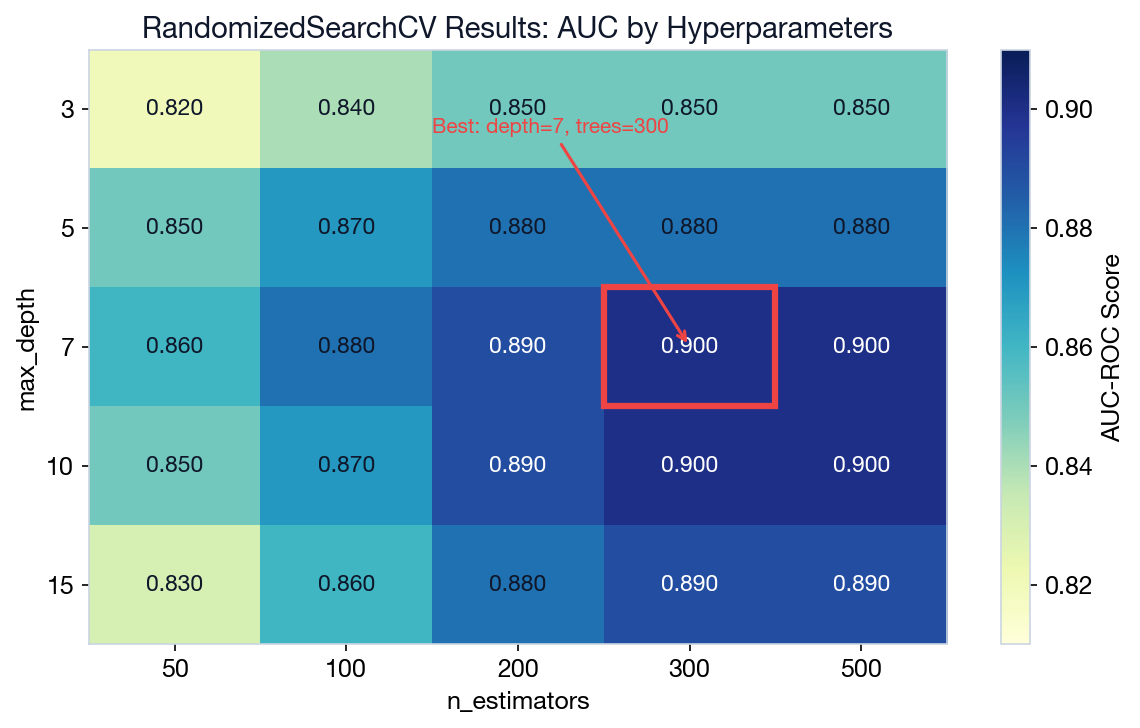
print(search.best_params_)Use scoring='roc_auc' for imbalanced datasets. RandomizedSearchCV is much faster than GridSearch when the parameter space is large.
cv=5 = 5-fold cross-validation: split data into 5 parts, train on 4, test on 1, repeat 5×, average the scores.
roc_auc = Area Under ROC Curve. Measures class separation ability. 1.0 = perfect, 0.5 = random guessing.
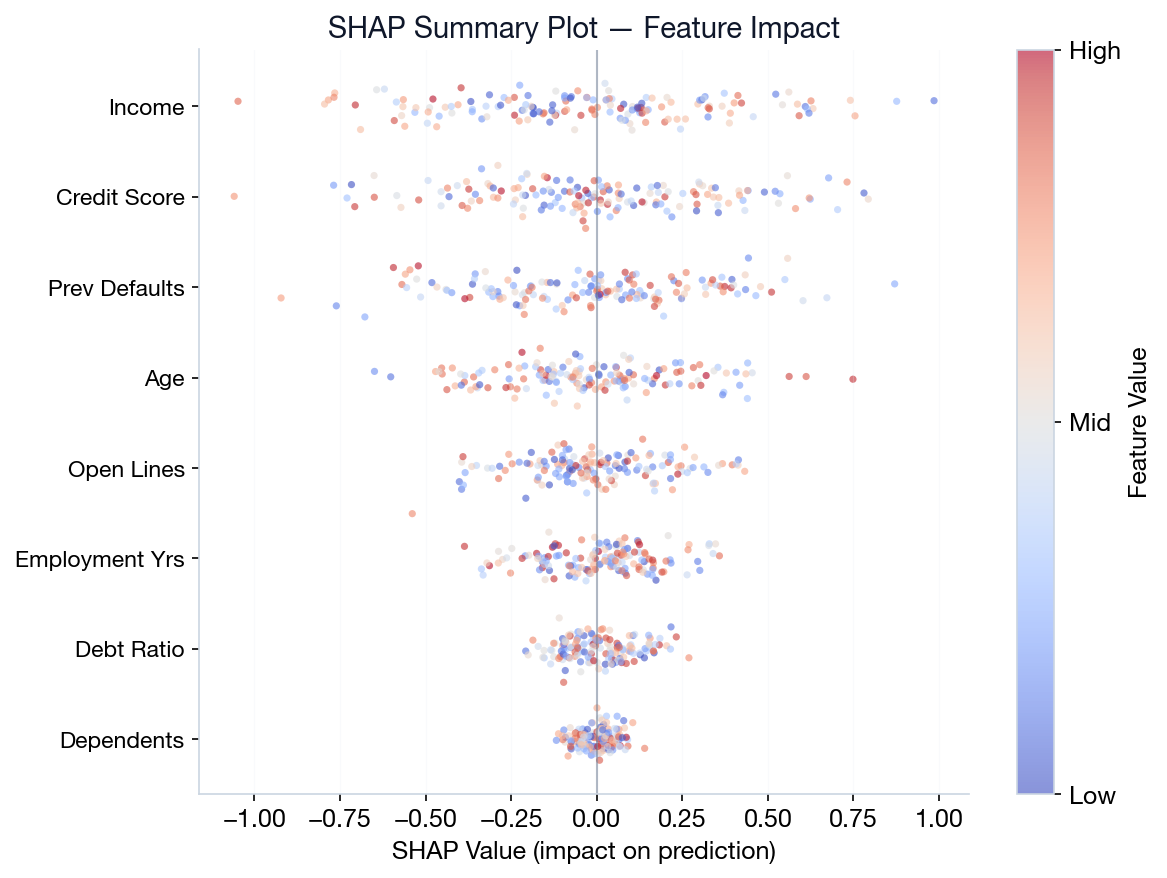
SHAP: Explaining Individual Predictions
Intuition: Imagine a team project. SHAP figures out each member's (feature's) fair contribution to the final grade (prediction). It asks: “If we remove this feature, how much does the prediction change?”
φi = ∑S⊆N\{i} |S|!(|N|−|S|−1)! ⁄ |N|! · [v(S∪{i}) − v(S)]
Marginal contribution of feature i, averaged over all coalitions (coalition = any subset of features used together)
Feature importance tells you which features matter globally. SHAP tells you why a specific prediction was made.
How to read beeswarm: Red dots right = pushes prediction up. Blue dots left = pushes down. Wider spread = more important.
Think of SHAP like splitting a group project grade fairly — each feature gets credit proportional to its actual contribution to the prediction.
Common Mistake: SHAP ≠ causation. If your model uses ice cream sales to predict drowning risk, SHAP will show high importance for ice cream — but both just correlate with summer.
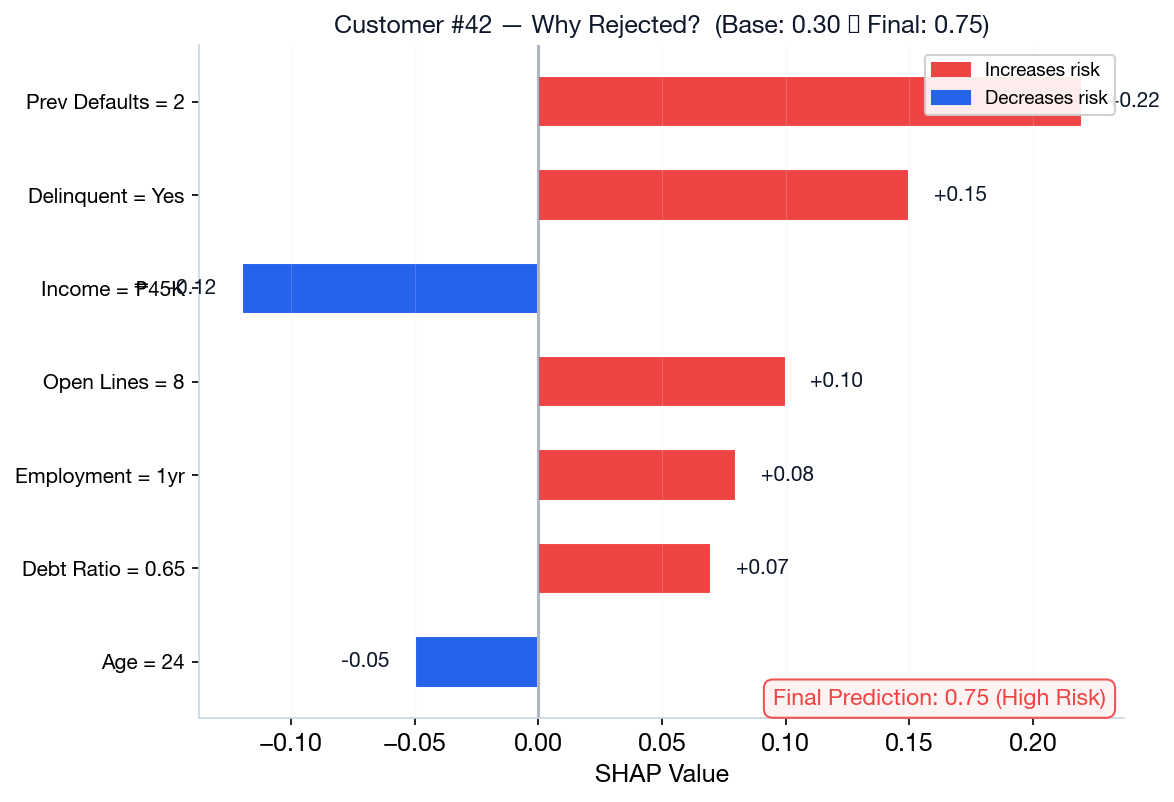
Credit Risk with XGBoost + SHAP
Build a credit scoring model on Philippine data and explain individual rejection decisions using SHAP.
Dataset & Features
Simulated Philippine credit data: income, employment length, number of open credit lines, previous defaults, delinquency status. Target: default risk (binary).
Pipeline
- Clean & encode categorical features
- Train XGBoost with early stopping
- Generate SHAP values for each customer
- Waterfall plot explains individual decisions
SHAP explanations satisfy BSP regulatory requirements for transparent credit decisions.