What Makes Time Unique
Unlike cross-sectional data, time series carries memory. Today depends on yesterday.
This section covers time series structure, decomposition, and resampling.

Time Series Data Has Memory
A time series is a sequence of data points ordered by time — each observation may depend on previous ones.
Key Characteristics
- Temporal dependence — today affects tomorrow
- Trend — long-term direction
- Seasonality — repeating patterns
- Noise — random variation
Four Components Hide Inside Every Series
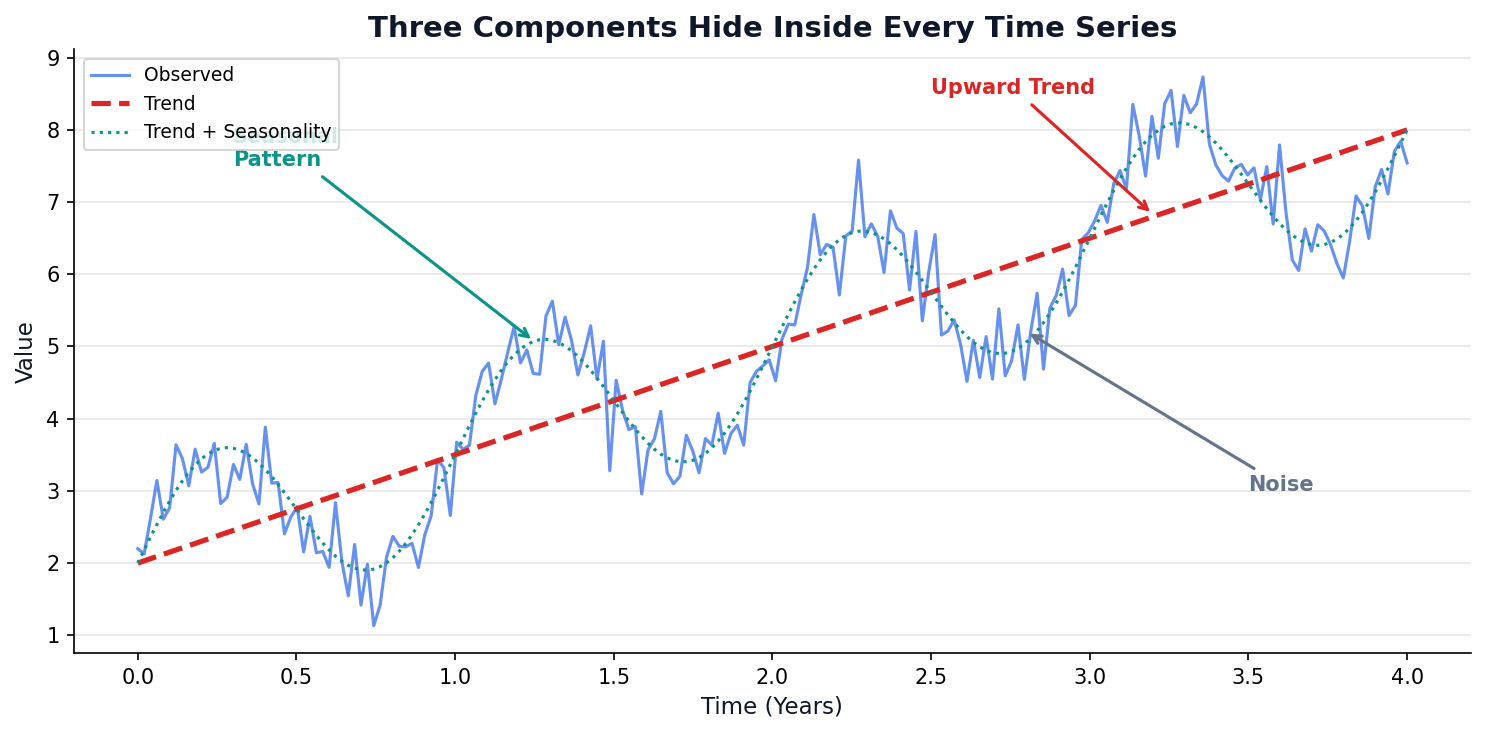
Decomposition = splitting a series into its building blocks. Every time series is a mix of these four:
1. Trend (T)
The long-term direction — is the series going up, down, or flat over years?
2. Seasonality (S)
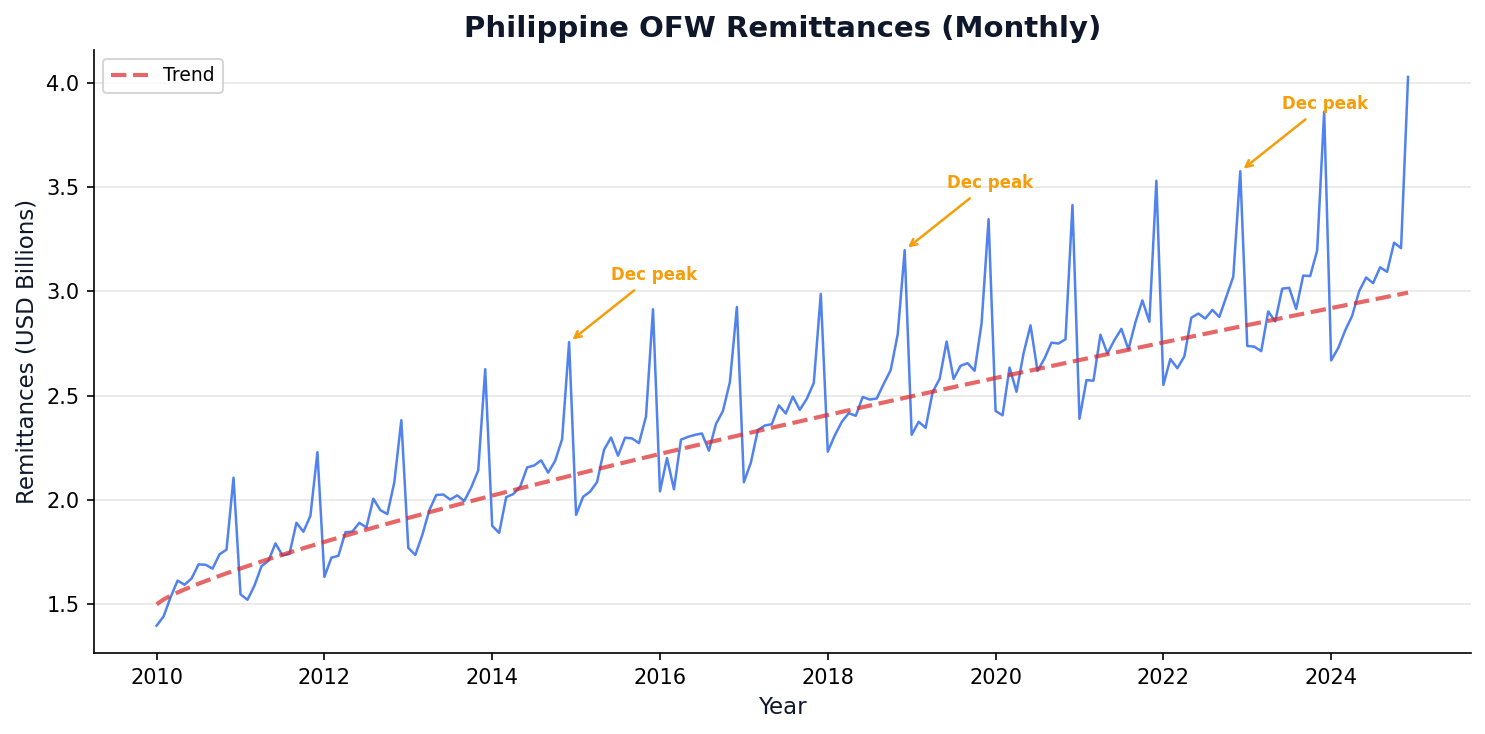
Repeating patterns at fixed intervals — December peaks, weekend dips, summer surges.
3. Cyclical (C)
Rise and fall without fixed period — business cycles, economic booms/busts (years-long waves).
4. Residual / Noise (R)
Random leftover after removing the other three — unpredictable, ideally small.
Additive
$Y_t = T_t + S_t + C_t + R_t$
Constant seasonal swing (+₱500M every Dec)
Multiplicative
$Y_t = T_t \times S_t \times C_t \times R_t$
Growing seasonal swing (+15% every Dec)
Decomposition: Step by Step
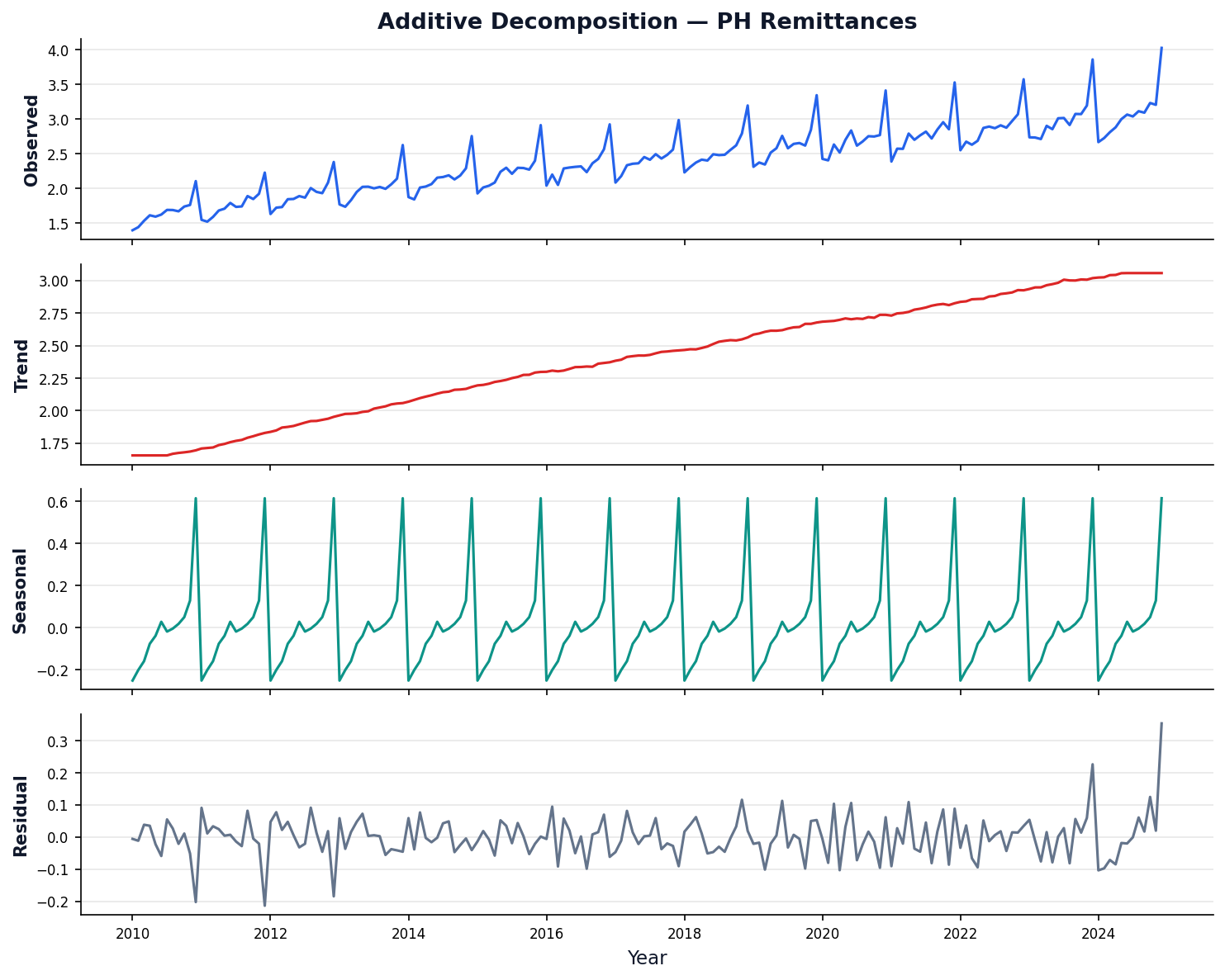
Step 1: Extract Trend (T)
Smooth the series with a centered moving average of window = period.
For period $m$=12: average 12 months centered on each point. Removes seasonality, keeps only the long-term direction.
Step 2: Extract Seasonality (S)
Detrend first, then average all same-month values.
$S_{\text{month}} = \frac{1}{n}\sum D_t$ for all Jans, all Febs, …
Example: average all December detrended values → $S_{\text{Dec}}$ = +0.5 (always a peak).
Step 3: What's Left = Residual (R)
Subtract trend and seasonality from the original.
$R_t = Y_t - T_t - S_t$
$R_t = \frac{Y_t}{T_t \times S_t}$
If the decomposition is good, R should look like random noise near zero (additive) or near 1 (multiplicative).
Python code: see Appendix
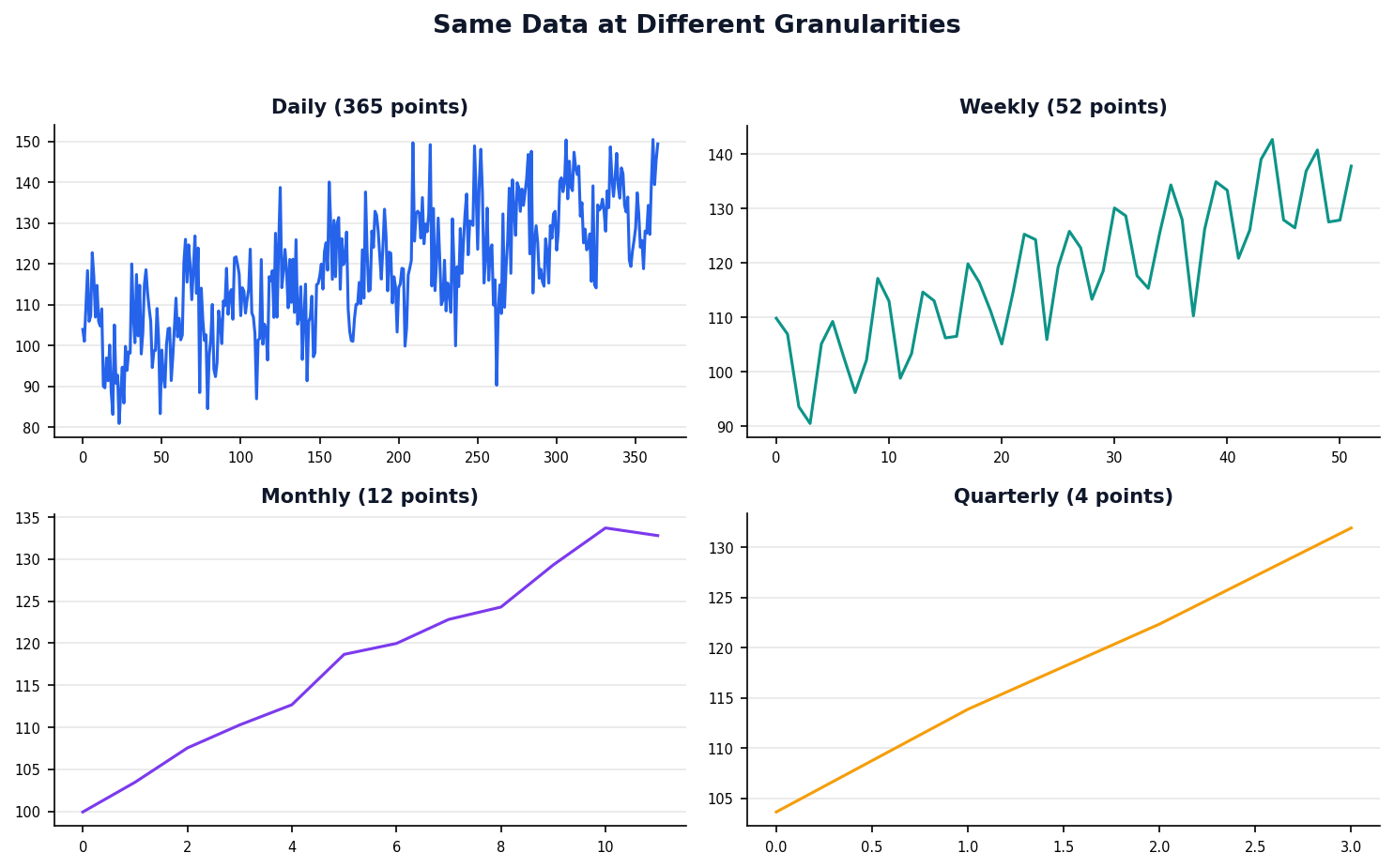
Resampling Changes the Granularity
Resampling means changing the time granularity — downsampling (daily → monthly) aggregates, upsampling (monthly → daily) interpolates.
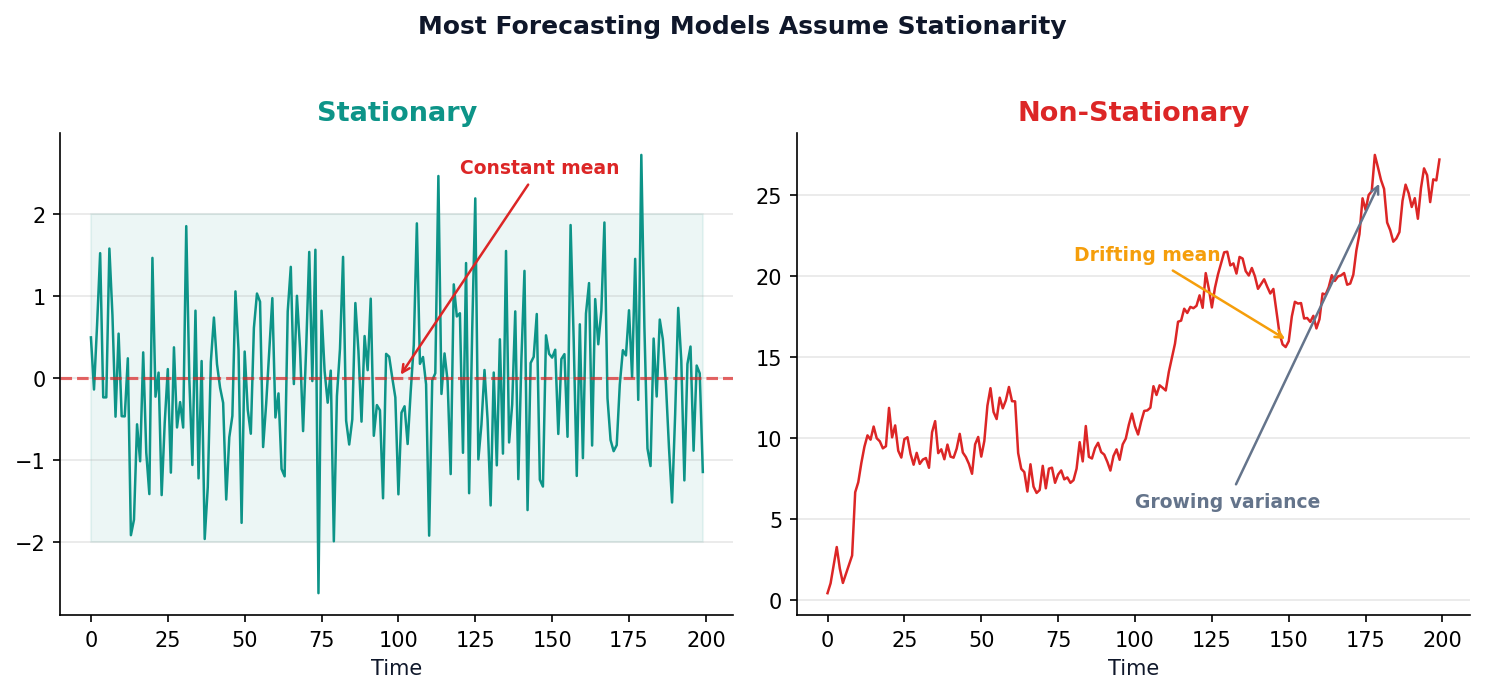
The Stationarity Requirement
Most forecasting models assume the future looks statistically like the past.
If the mean or variance drifts over time, predictions break down.
Forecasting Breaks When the Rules Keep Changing
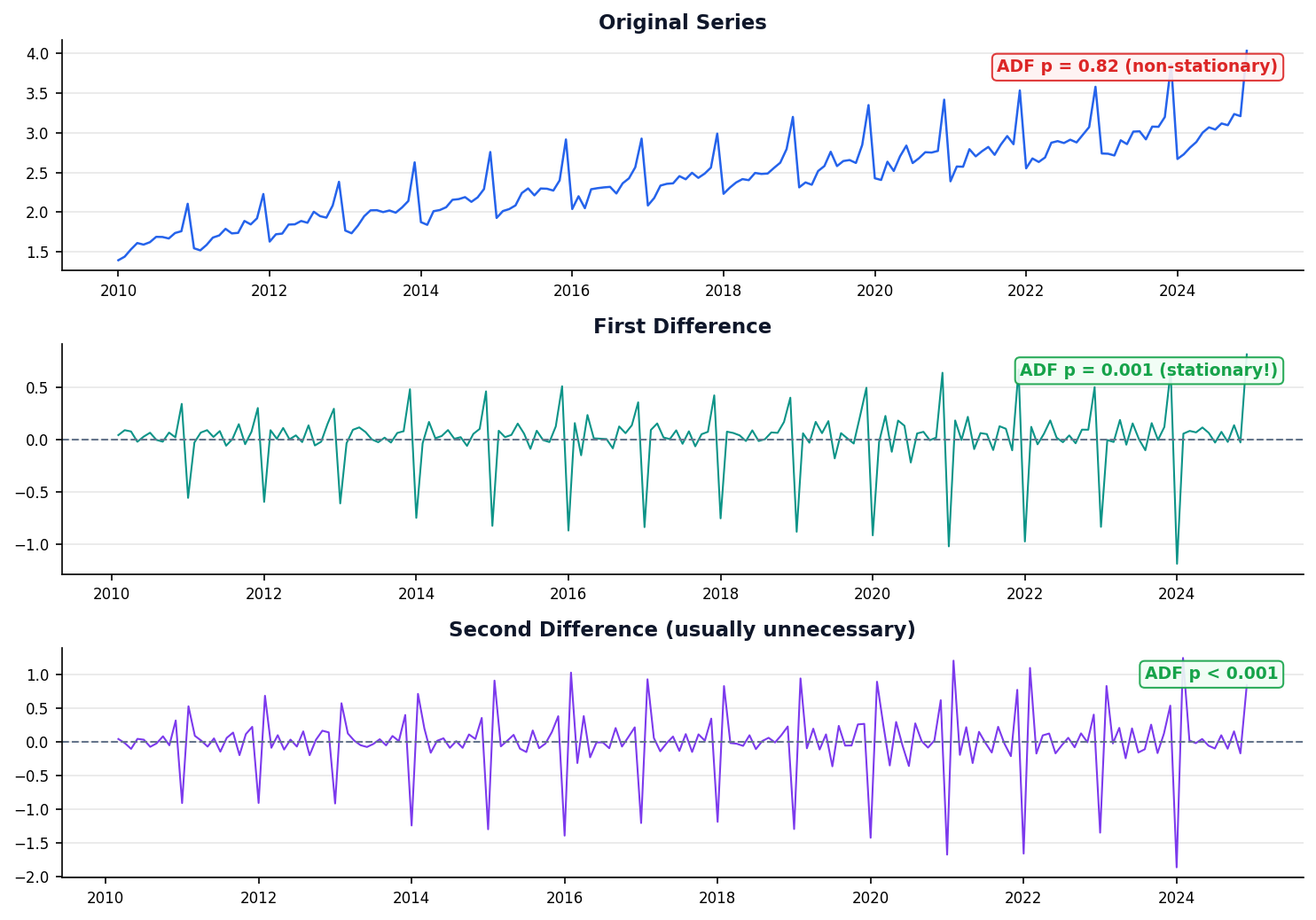
Differencing Removes the Trend
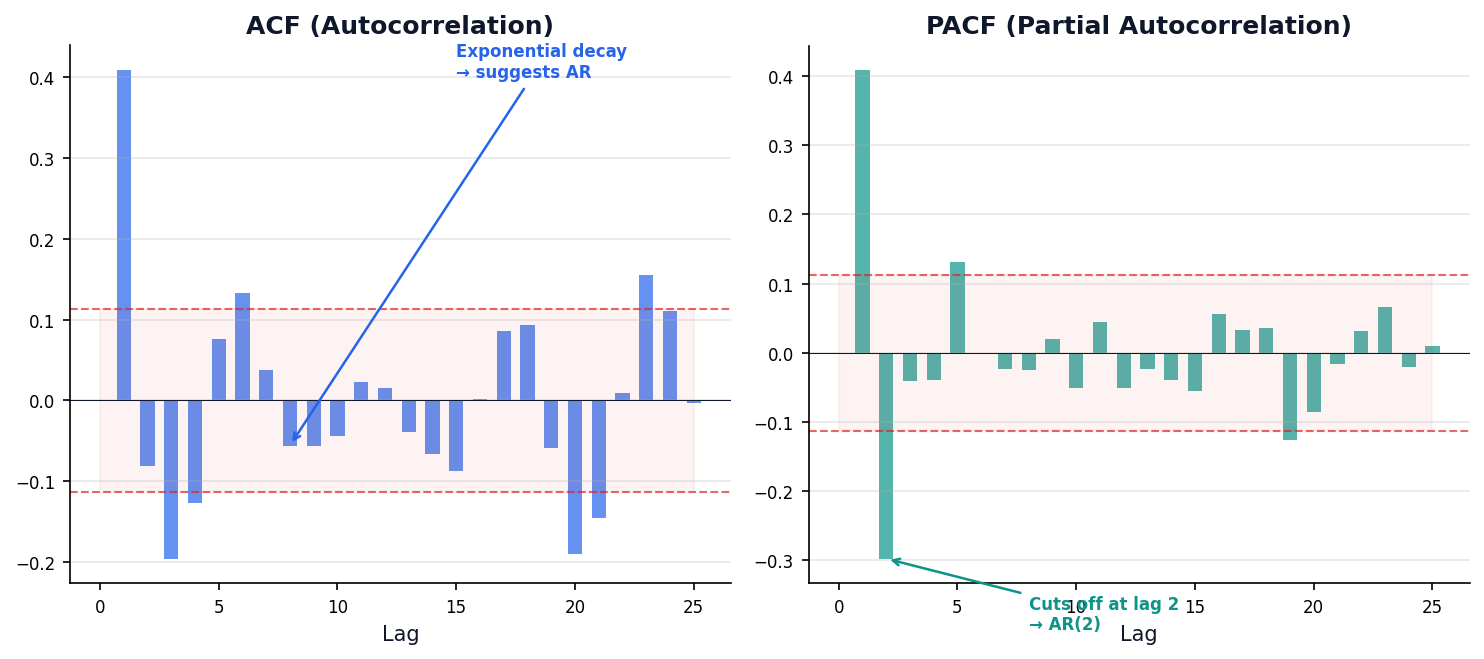
Reading the Autocorrelation Signature
ACF and PACF plots are the fingerprint of any time series — they tell you which model to use.
Past Values Predict Future Values
ACF (Autocorrelation Function)
Correlation between Yt and Yt-k at each lag k. Includes indirect effects through intermediate lags.
PACF (Partial Autocorrelation)
Direct correlation between Yt and Yt-k after removing effects of intervening lags.
Intuition: If sales were high last month, are they likely high this month too? Autocorrelation measures exactly this — how much the past predicts the future.
Definitions
- Autocorrelation — how much a series correlates with its own past values
- Lag — a delayed version of the series (lag-1 = last month, lag-12 = same month last year)
- ACF (Autocorrelation Function) — shows correlation at every lag
- PACF (Partial ACF) — shows direct correlation at each lag, removing intermediate effects
Smoothing the Signal
Before forecasting, we need to separate signal from noise.
Smoothing techniques reveal underlying patterns by reducing random variation.

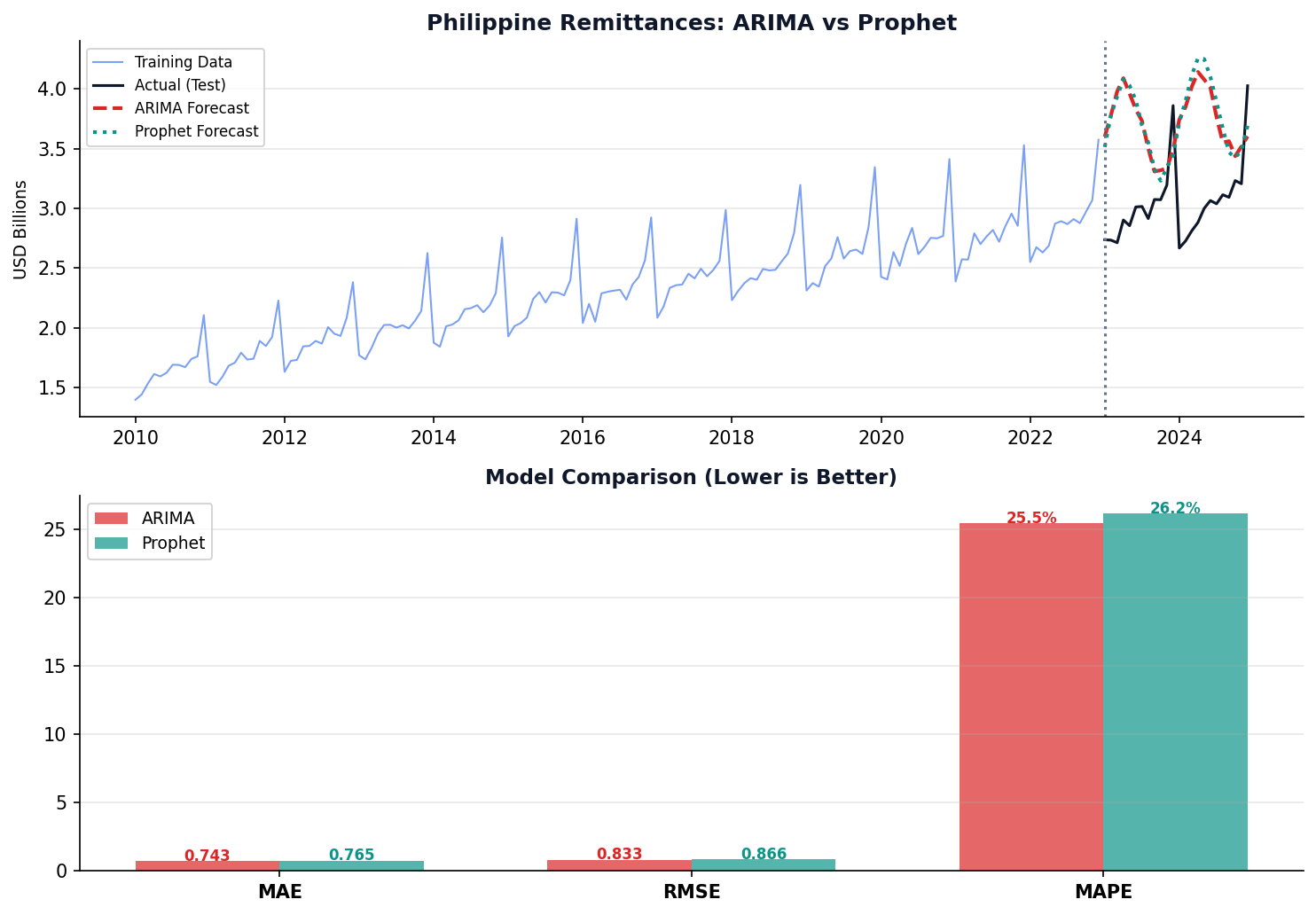
ARIMA: The Workhorse of Forecasting
Three ideas from Session 1 — autoregression, differencing, and moving average — combined into one powerful model.

Prophet: Built for Business
Meta's open-source tool handles missing data, holidays, and changepoints automatically.
Designed for analysts who need good forecasts fast, not ARIMA experts.
Prophet Setup and Forecasting
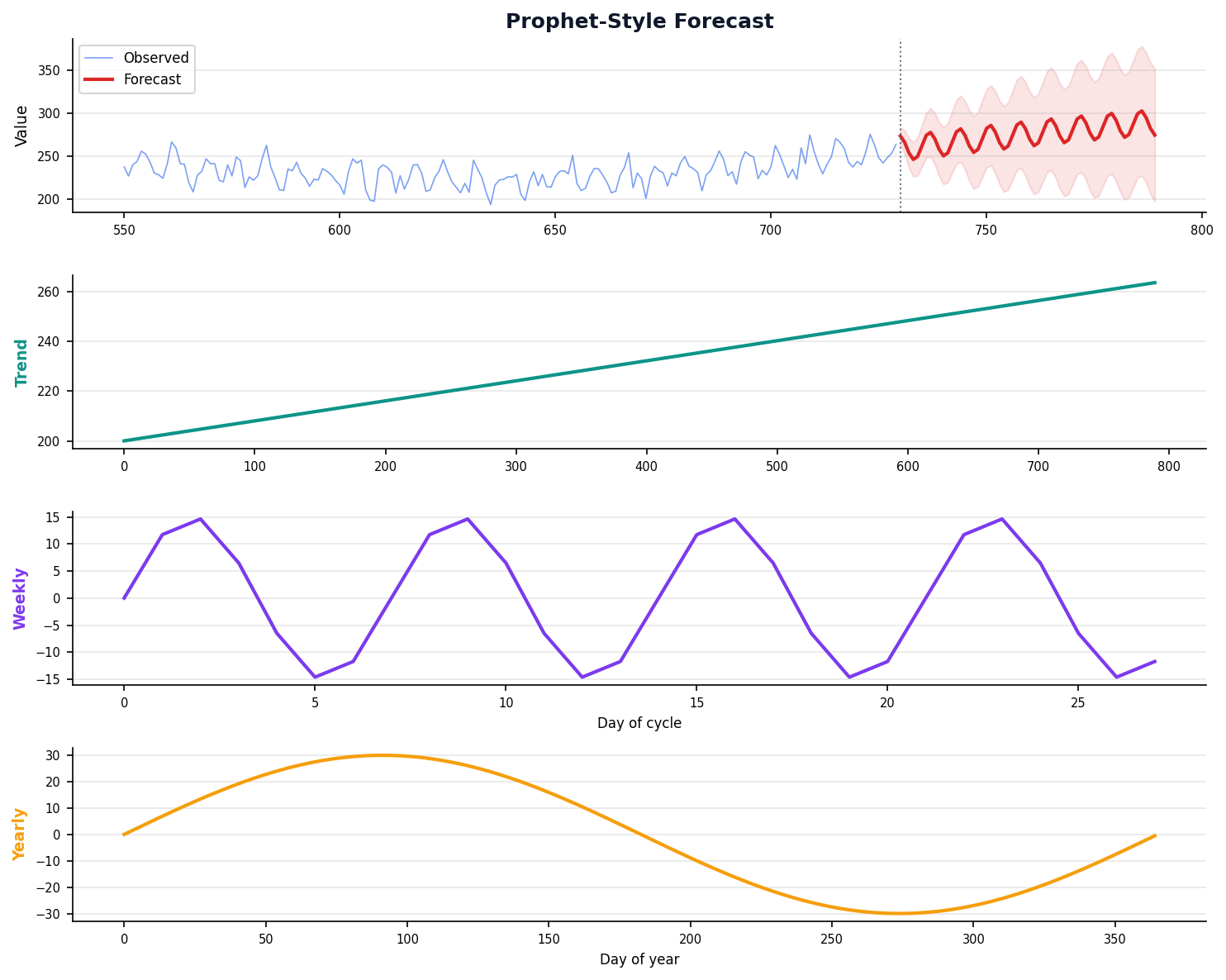
model.plot_components() for trend + seasonality breakdown.
Python code: see Appendix
Philippine Holidays Make Forecasts Smarter
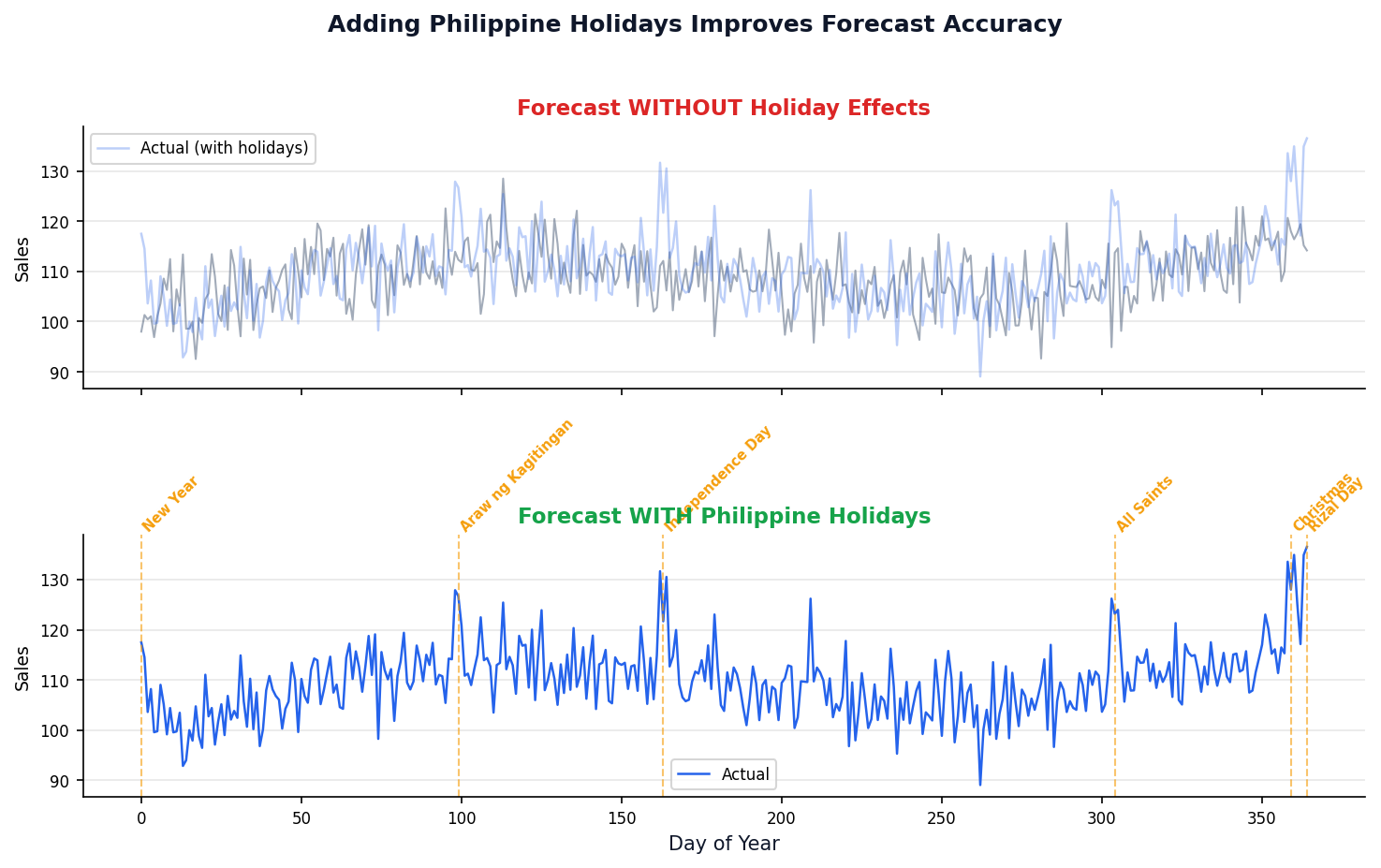
Measuring Forecast Quality
A forecast without an error estimate is just a guess.
This section covers metrics, temporal splits, and model comparison.

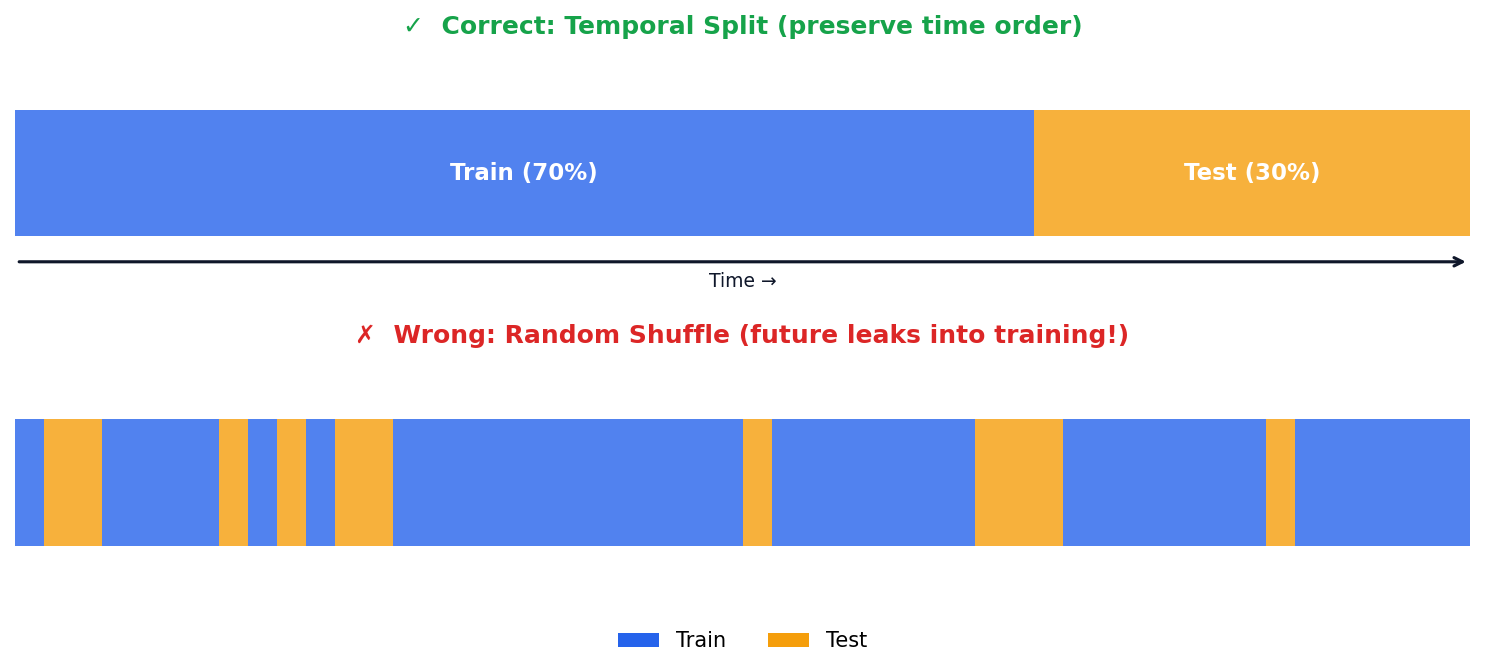
Time Series Train-Test Split: Never Shuffle
Temporal split — split by TIME (train on past, test on future). Never shuffle time series data! White noise — a series of completely random values with no pattern (mean=0, constant variance). Good residuals look like white noise.
Philippine Remittances: Complete Forecasting Pipeline